DSPy through a RAG System
MagicLens, Derm Foundation from Google, MTIA from Meta

Articles

Databricks wrote an article on how DSPy can be used to build AI systems specifically Retrieval Augmented Generation(RAG). I have covered DSPy in multiple previous newsletters; one, second and third. The last one is the following:
Mamba ands DSPy explained!

Articles We covered Mamba as an introduction in one of the previous newsletter: This article from Gradient expands a lot more about the advantages and technical details with comparison to Transformers: Limitations of Transformers(now it should be obvious to everyone as talked in the previous newsletter!):
If we go back to the main article; DSPy uses programming instead of prompting to achieve better results. It accomplishes this by allowing users to define the components of their AI systems. This is done by composing layers, for this application; a retrieval layer and a generation layer. These layers are then used together to create a program that can answer questions. The article includes an example of how DSPy can be used to answer a question about hockey. In conclusion, DSPy is a new tool that can be used to improve AI tasks by allowing users to program their AI systems.
DSPy allows users to compose layers together to create a compound AI system. For example, a user might compose a retrieval layer and a generation layer to create a system that can answer questions. The retrieval layer would be used to find information that is relevant to the question, and the generation layer would be used to generate an answer to the question.

Google announced MagicLens: a series of image retrieval models. Trained on 36.7M (query image, instruction, target image) triplets with rich semantic relations mined from the web, a single MagicLens model can achieve comparable or better results on 10 benchmarks of various multimodality-to-image, image-to-image, and text-to-image retrieval tasks than prior state-of-the-art (SOTA) methods. Also, MagicLens can satisfy diverse search intents expressed by open-ended instructions.

MagicLens is built upon single-modality encoders initialized from CLIP or CoCa and trained with simple contrastive loss. With a dual-encoder architecture, MagicLens can take both image and text inputs to deliver a VL embedding, thus enabling multimodal-to-image and image-to-image retrieval. Also, the bottom single-modality encoders can be re-used for text-to-image retrieval, with non-trivial performance gains.
Main advantages over other approaches is that naturally occurring image pairs on the same web page contain diverse image relations (e.g., inside and outside views of the same building). Modeling such diverse relations can enable richer search intents beyond just searching for identical images in traditional image retrieval and it can satisfy various search intents expressed by open-ended instructions, especially complex and beyond visual intents — where prior best methods fall short.

Google research published a blog post on Derm Foundation and Path Foundation. These tools are designed to be used by medical researchers to analyze dermatology and pathology images. The tools can be used to create models to classify skin conditions and identify tumors.
Derm Foundation is a tool that can be used to analyze dermatology images. It works by first converting a dermatology image into an embedding. This embedding can then be used to train a model to classify skin conditions. Path Foundation works in a similar way, but it is designed for pathology images. Pathology images are larger and more complex than dermatology images, so Path Foundation uses a different process to create embeddings.

If we do deep in how Derm Foundation works:
Derm Foundation first pre-processes the dermatology image. This may involve resizing the image and converting it to a format that is suitable for the deep learning model.
The pre-processed image is then fed into the deep learning model. The deep learning model extracts features from the image and generates an embedding.
The embedding can then be used to train a model for a specific task, such as classifying skin conditions.
If we go deep in how Path Foundation works:
Path Foundation also pre-processes the pathology image. However, the pre-processing steps for pathology images are more complex than the pre-processing steps for dermatology images. This is because pathology images are larger and more complex than dermatology images.
The pre-processed pathology image is then fed into a deep learning model that is specifically designed for pathology images. This model extracts features from the image and generates an embedding.
The embedding can then be used to train a model for a specific task, such as identifying tumors.
The article also discusses the limitations of Derm Foundation and Path Foundation and it is not yet clear how well they will generalize to different types of tasks, patient populations, and image settings. Additionally, downstream models built using Derm Foundation or Path Foundation still require careful evaluation to understand their expected performance.
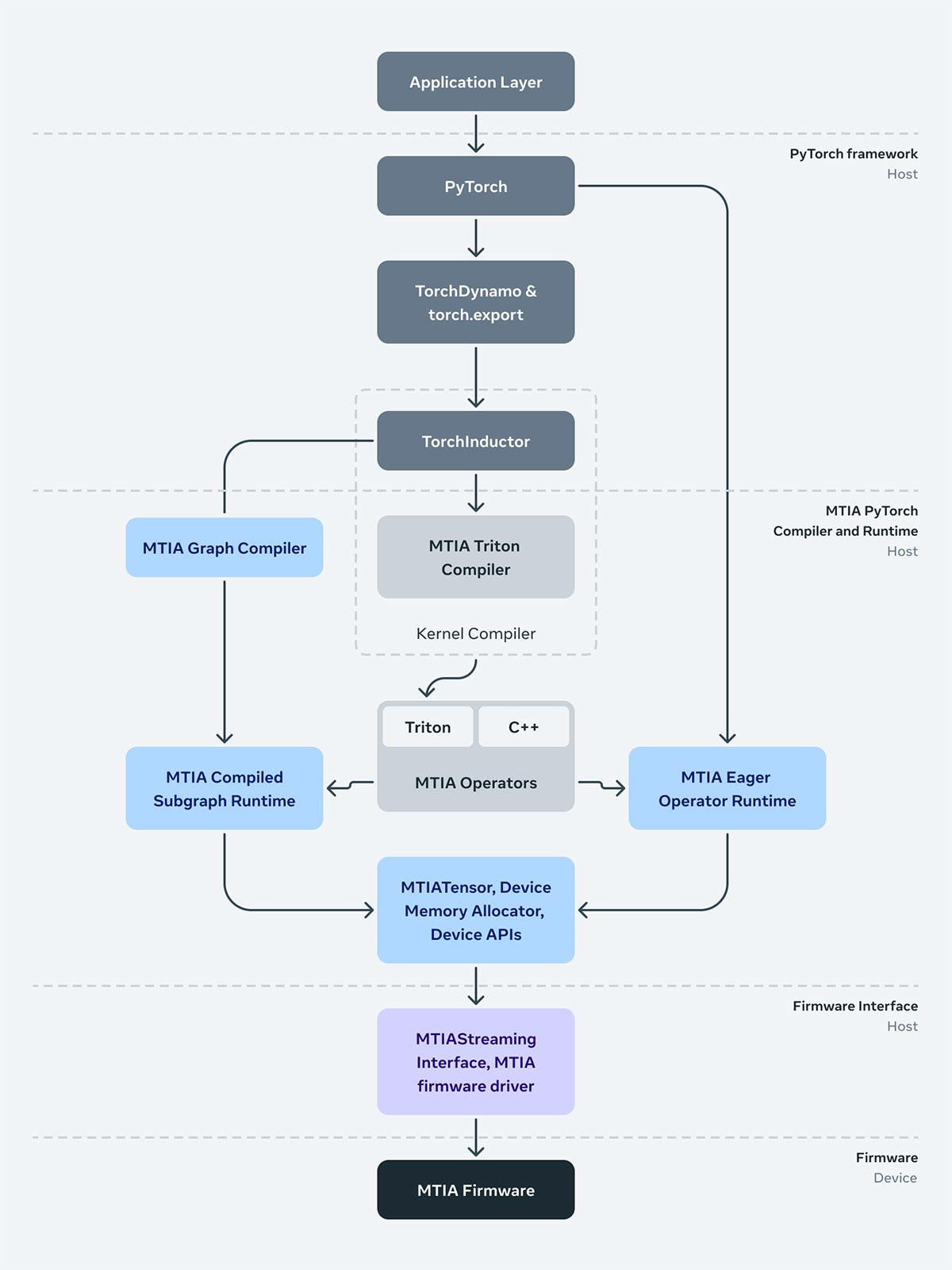
Meta wrote about their new custom-made chips for their AI workloads. It discusses the challenges of supporting large-scale AI models. The new chips, called MTIA, are designed to be more efficient than commercially available GPUs. They achieve this by having a better balance of compute, memory bandwidth, and memory capacity. The article also details the software stack designed to work with the new chips. Some main themes from the article are:
Challenges of large-scale AI models: Training and running large AI models requires a significant amount of computing power and memory. Traditional CPUs are not powerful enough for these tasks, and GPUs, while more powerful, can still be inefficient. GPUs are designed for a wide range of graphical tasks, and not specifically optimized for the types of computations needed for AI models. This can lead to bottlenecks in performance and inefficiencies in power usage.
Custom-made chips: Meta has designed the MTIA chips specifically for the needs of their AI workloads. These chips are designed to provide a better balance of compute, memory bandwidth, and memory capacity. This allows the chips to process AI models more efficiently than traditional GPUs.
Compute: The MTIA chips have a large number of cores designed for the specific types of computations needed for AI models. This allows the chips to perform a large number of calculations simultaneously.
Memory bandwidth: Memory bandwidth is the rate at which data can be transferred between the chip and memory. AI models often require access to large amounts of data, so having high memory bandwidth is essential. The MTIA chips have been designed with high memory bandwidth to meet the needs of AI models.
Memory capacity: The MTIA chips also have a large amount of memory capacity. This allows the chips to store the data needed for AI models on-chip, which can further improve performance.
Software stack: In order to get the most out of the MTIA chips, Meta has also developed a custom software stack. This software stack is designed to work with the specific architecture of the MTIA chips and to optimize the performance of AI models running on the chips.
Well end to end system that does model system code sign can bring a lot of efficiencies in a very large scale systems and MTIA will be an example of this.
Libraries
Axolotl is a tool designed to streamline the fine-tuning of various AI models, offering support for multiple configurations and architectures.
Features:
Train various Huggingface models such as llama, pythia, falcon, mpt
Supports fullfinetune, lora, qlora, relora, and gptq
Customize configurations using a simple yaml file or CLI overwrite
Load different dataset formats, use custom formats, or bring your own tokenized datasets
Integrated with xformer, flash attention, rope scaling, and multipacking
Works with single GPU or multiple GPUs via FSDP or Deepspeed
Easily run with Docker locally or on the cloud
Log results and optionally checkpoints to wandb or mlflow
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks.
Deploy any model from MTEB: deploy the model you know from SentenceTransformers
Fast inference backends: The inference server is built on top of torch, optimum(onnx/tensorrt) and CTranslate2, using FlashAttention to get the most out of your NVIDIA CUDA, AMD ROCM, CPU, AWS INF2 or APPLE MPS accelerator.
Dynamic batching: New embedding requests are queued while GPU is busy with the previous ones. New requests are squeezed intro your device as soon as ready.
Correct and tested implementation: Unit and end-to-end tested. Embeddings via infinity are correctly embedded. Lets API users create embeddings till infinity and beyond.
Easy to use: The API is built on top of FastAPI, Swagger makes it fully documented. API are aligned to OpenAI's Embedding specs. View the docs at https://michaelfeil.eu/infinity on how to get started.

GenX is a highly-configurable, open source electricity resource capacity expansion model that incorporates several state-of-the-art practices in electricity system planning to offer improved decision support for a changing electricity landscape.
GenX is a constrained linear or mixed integer linear optimization model that determines the portfolio of electricity generation, storage, transmission, and demand-side resource investments and operational decisions to meet electricity demand in one or more future planning years at lowest cost, while subject to a variety of power system operational constraints, resource availability limits, and other imposed environmental, market design, and policy constraints.

Varuna is a tool for efficient training of large DNN models on commodity GPUs and networking. It implements a combination of pipeline parallelism and data parallelism in PyTorch, and enables training on a changing set of resources smoothly.


Great Tables can make wonderful-looking tables in Python. The philosophy here is that we can construct a wide variety of useful tables by working with a cohesive set of table components. You can mix and match things like a header and footer, attach a stub (which contains row labels), arrange spanner labels over top of the column labels, and much more. Not only that, but you can format the cell values in a variety of awesome ways.