Compound AI Systems over Vanilla LLMs
So many GenAI Libraries! SliceGPT, Medusa, Hydra, Phidata, Guidance, LLMFlows,

Articles

BAIR(Berkeley AI Research) wrote rather an interesting blog post. Their main argument is that; the LLMs are not the solution to our problems, but rather “compound systems” that bring models to other systems(guardrail, etc) to solve a particular user/product problem.
Theory is that AlphaCode, ChatGPT+, Gemini are examples of Compound AI Systems that solve tasks through multiple calls to models and other components. There are multiple advantages over vanilla LLMs:
Responsiveness and adaptability to further business use cases
Higher ROI
Better control and guardrails around safety
Of course, the compound systems require different types of programming paradigm and the solutions should not be same what we use for building these vanilla LLMs. New compound AI systems contain non-differentiable components like search engines or code interpreters, and thus require new methods of optimization. Optimizing these compound AI systems is still a new research area; for example, DSPy offers a general optimizer for pipelines of pretrained LLMs.
Jeff Dean presents a survey for ML development in the last decade and where the field is going in:
I will take some slides from his presentation and summarized each slides in few sentences.

He starts with the scaling of the models and how the scaling of the compute, data, model size delivers better results and the main theme of the talk can be also considered how scaling make these models much better(algorithmically and computationally) at the time of the survey.

This slide was the most interesting to me; first used the inputs as outputs and then explained how the field is now trying to generate the modality for a given input text. Earlier especially in computer vision, generally the problem, given an image or video, it was to predict a piece of text(category of a class, understanding the audio into text, translation, etc), now with multi-modal capabilities, we are trying to generate modalities from text. Such a simple slide, but it was a really good one.
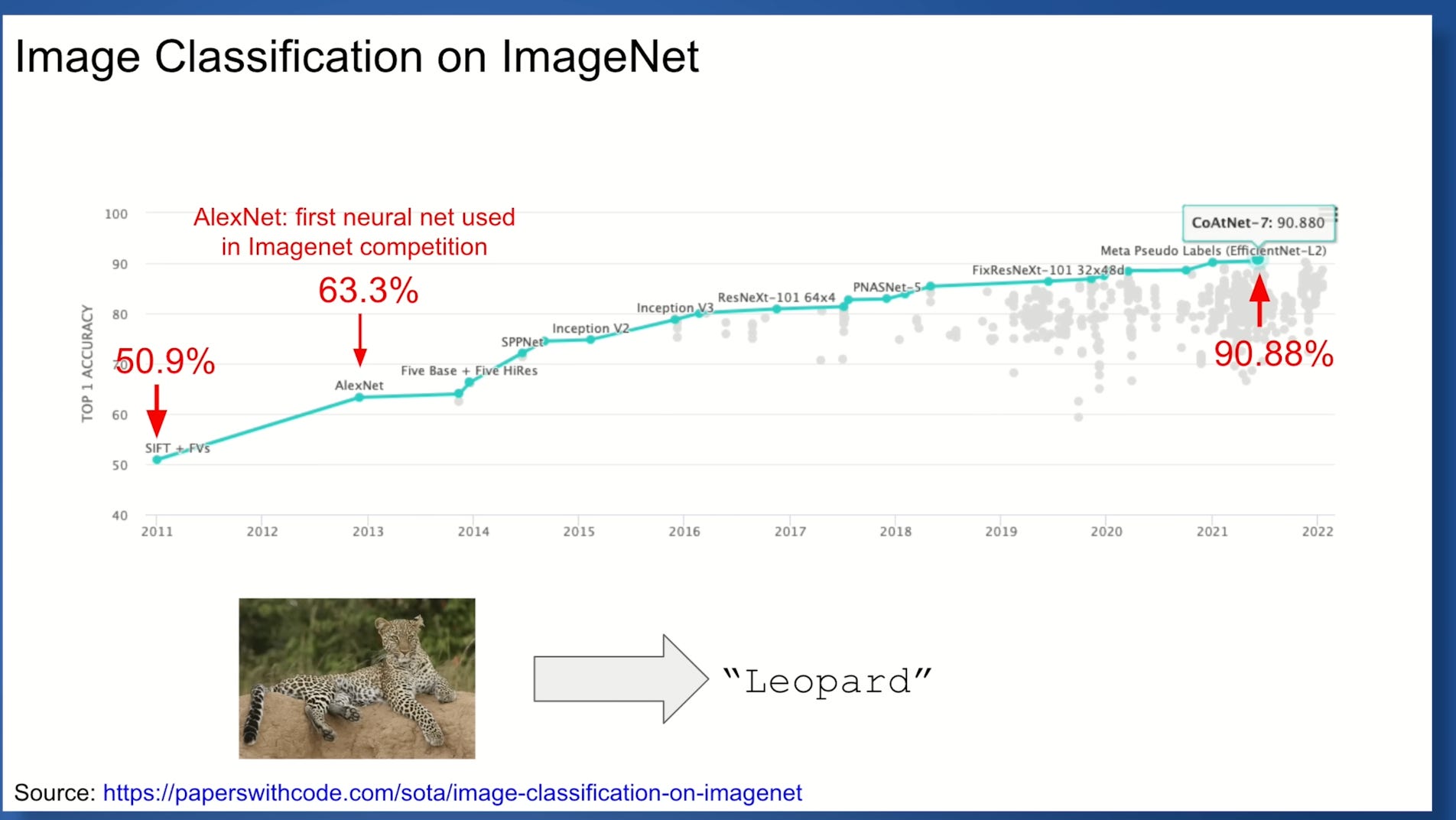
Although the biggest jump was on AlexNet(2013), we have came a long way since then in terms of accuracy(90.88%) and now the accuracy is larger than the human evaluation.

Very similar story on speech recognition(smaller the error rate is the better).

Reduced precision(quantization) is okay and actually sometimes enables model to be robust to “noise” and can help generalization.
It also uses a handful operations under the hood for linear algebra computations.

Google invests a family of hardware type called TPU(Tensor Processing Unit) and this slide and following slide shows how much compute that it enables for both inference and training.

One thing that Google realized early on is that robust and capable infrastructure is key for improving model performance as model scaling requires compute, memory and powerful hardware due to that.

They are offering these HW through their cloud offering GCP and it provides a lot of compute for very large training and inference loads.

He then starts with how it started slides in the presentation through different papers. First, he takes an example of large scale N-gram models for machine translation. Although this is not considered to be a sound approach, it is good paper to show the effectiveness of the large datasets in order to learn language models.

Then, he goes over one of the most famous paper; so called “Word2Vec” paper to showcase that deep learning establishes itself a sound method for language modeling.

Then, another seminal paper “Seq2Seq” paper, he talks about how to use a neural encoder over an input sequence to generate state, and use that to initialize state of the neural decoder. Because, we do not have Transformers at this stage(yet!), they are using LSTMs.

And of course, the Transformer paper! This is probably the breakthrough paper that shows how effective Transformer family of models for anything sequence related modeling and it had tremendous success for a variety of different large scale tasks in machine learning.


After Transformer paper, he talks about a variety of different techniques to show which models are enabled and which areas.

He then talks about their work which is Gemini model that is multimodal foundational model that handles any of modality to understand and performs very well for a variety of tasks in language and image.

They support a variety of different sizes of this model. And the basic version is available for free in gemini.google.com, and you can pay for the better version on a monthly basis.

They use a router based approach for training to do dynamically adjusts the neurons per model learning through an efficient mixture of models approach. And he talks about how this flexibility is enabled in the HW layer in TPUs.

Training data is very important and they spent quite a bit of time to collect high quality training datasets.
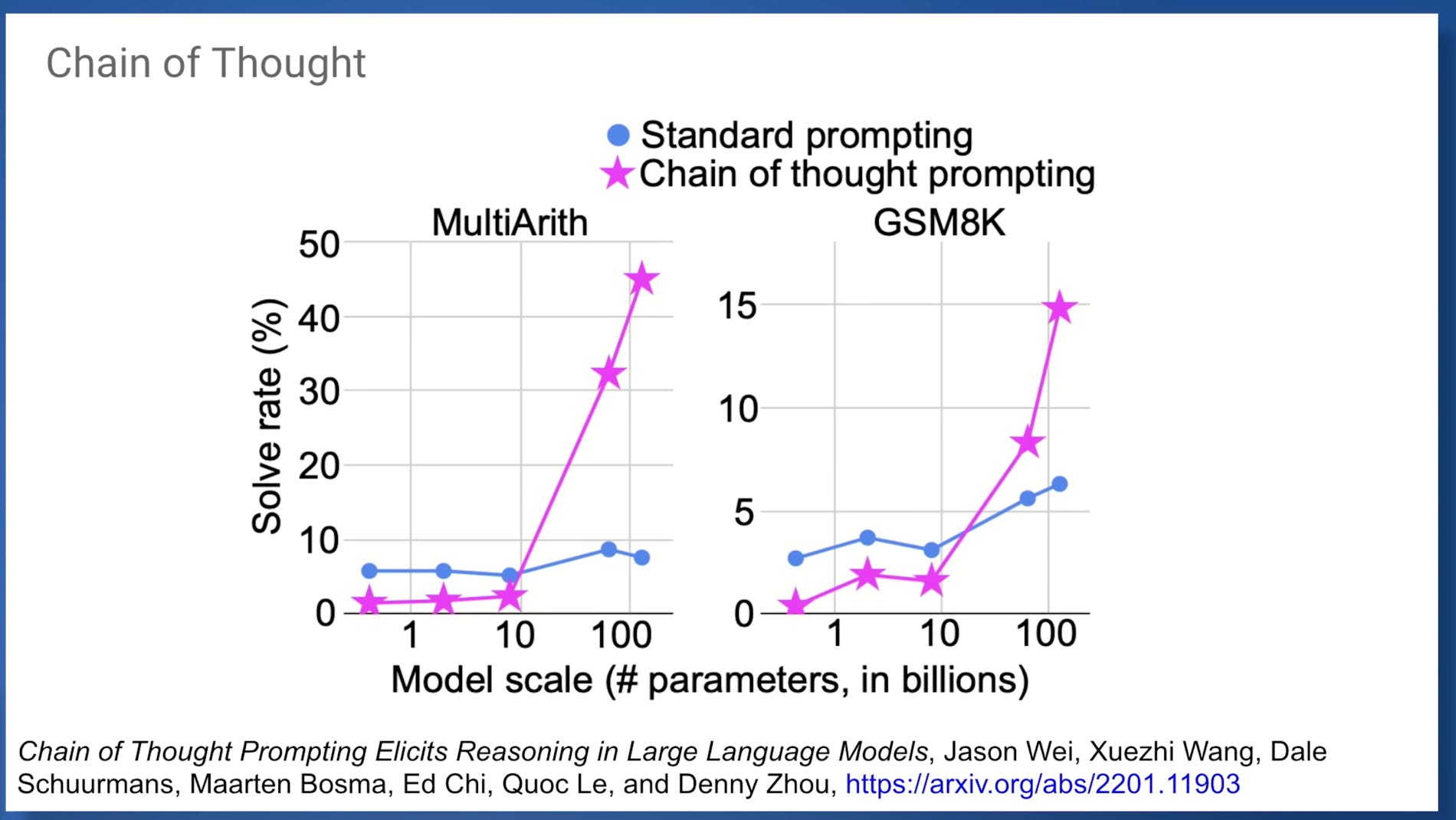
This slide was interesting to me where it demonstrates that a model with chain of though prompting can actually do better than standard prompting; which means that step by step explanation and reasoning actually makes the model performance better!
This is also probably the same case for humans as it is better to answer a question by providing the solution step by step probably.

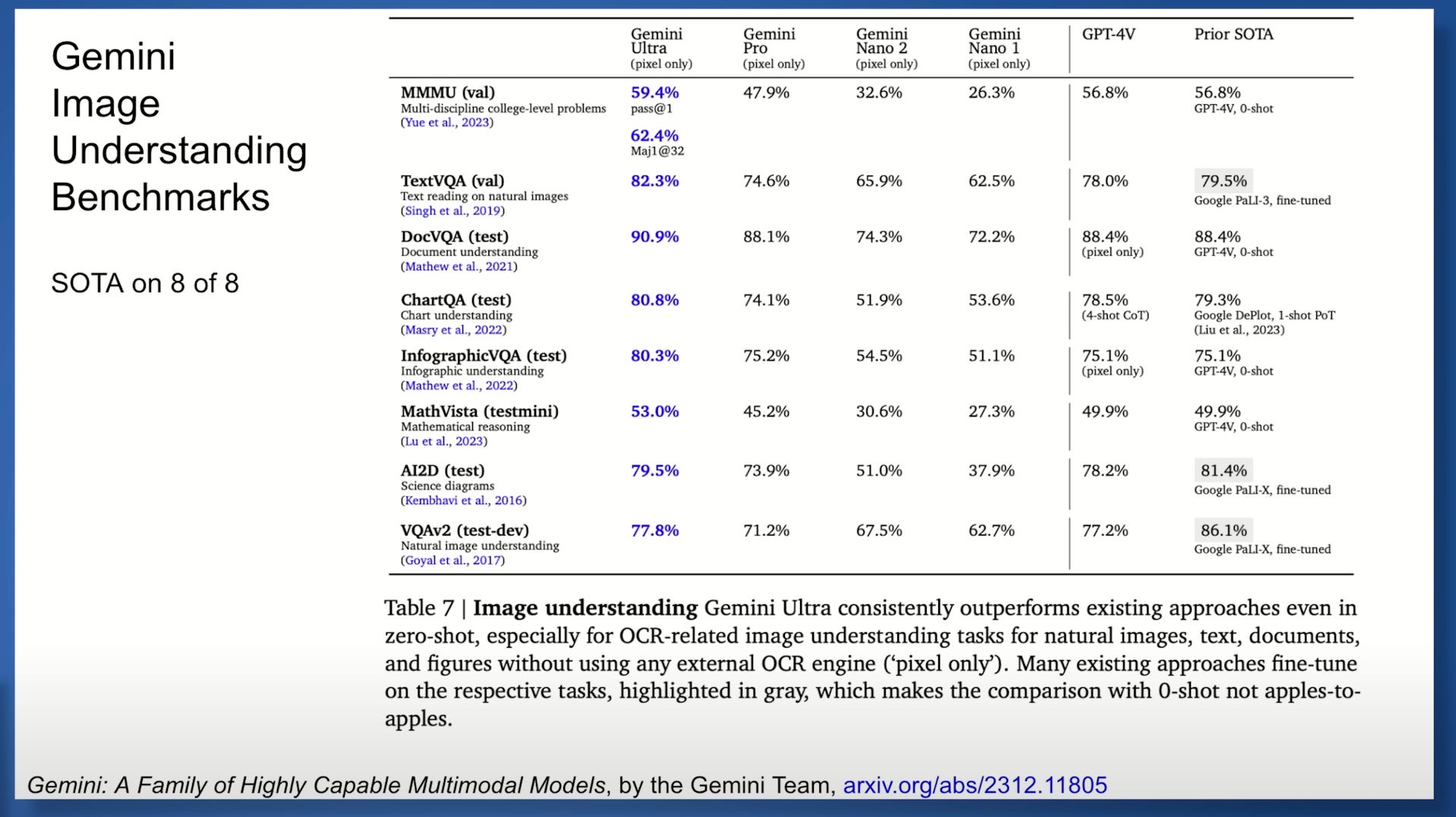

After that, he talks about the evaluations that he has done and what type of criteria that they used for evaluations as well as some benchmark results on how Gemini performed the best for a variety of different tasks.





Lastly, he covered a variety of different applications in different domains like drug discovery.
It is very approachable video, I recommend checking it out to learn more about!
Libraries

Ecosystem graphs from Stanford has a number of models that can be used for fine-tuning or distilling information to other foundation models.

Medusa is a simple framework that democratizes the acceleration techniques for LLM generation with multiple decoding heads. Medusa adds extra "heads" to LLMs to predict multiple future tokens simultaneously. When augmenting a model with Medusa, the original model stays untouched, and only the new heads are fine-tuned during training. During generation, these heads each produce multiple likely words for the corresponding position. These options are then combined and processed using a tree-based attention mechanism. Finally, a typical acceptance scheme is employed to pick the longest plausible prefix from the candidates for further decoding.

Hydra is a speculative decoding framework that leverages tree-based decoding and draft head-based draft models as proposed in Medusa. We make a simple change to the structure of the draft heads and condition each draft head on the candidate continuation so far such the draft heads are sequentially dependent. This along with some training objective and other head architecture changes leads to Hydra decoding improving throughput by up to 1.3x compared to Medusa decoding.

Phidata is a toolkit for building AI Assistants using function calling.
Function calling enables LLMs to achieve tasks by calling functions and intelligently choosing their next step based on the response, just like how humans solve problems.

guidance is a programming paradigm that offers superior control and efficiency compared to conventional prompting and chaining. It allows users to constrain generation (e.g. with regex and CFGs) as well as to interleave control (conditional, loops) and generation seamlessly.

LLMFlows is a framework for building simple, explicit, and transparent LLM(Large Language Model) applications such as chatbots, question-answering systems, and agents.
At its core, LLMFlows provides a minimalistic set of abstractions that allow you to utilize LLMs and vector stores and build well-structured and explicit apps that don't have hidden prompts or LLM calls. LLM Flows ensures complete transparency for each component, making monitoring, maintenance, and debugging easy.
It has a separate documentation page as well.
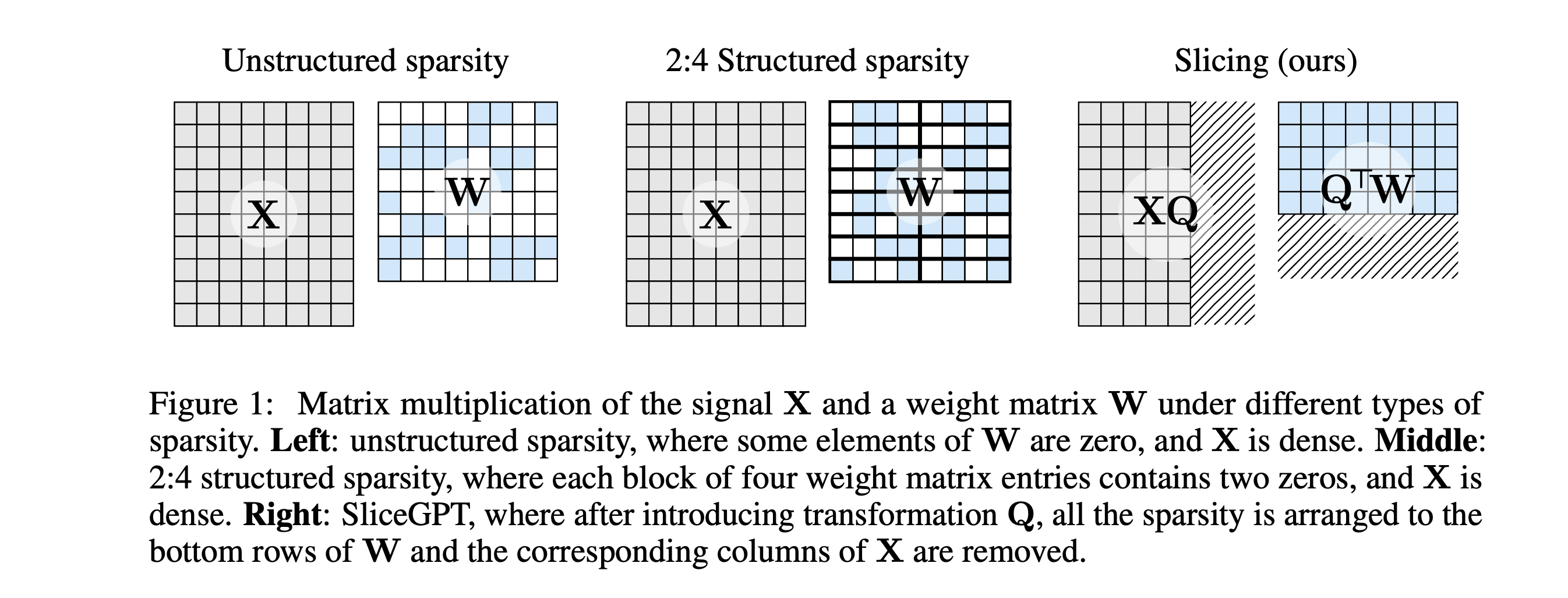
SliceGPT is a new post-training sparsification scheme that makes transformer networks (including LLMs) smaller by first applying orthogonal transformations to each transformer layer that leave the model unchanged, and then slicing off the least-significant rows and columns (chosen by the eigenvalue decay) of the weight matrices. The model structure is left unchanged, but each weight matrix is replaced by a smaller (dense) weight matrix, reducing the embedding dimension of the model. This results in speedups (without any additional code optimization) and a reduced memory footprint.
Datasets

CIDAR contains 10,000 instructions and their output. The dataset was created by selecting around 9,109 samples from Alpagasus dataset and then translating it to Arabic using ChatGPT. In addition, we append that with around 891 Arabic grammar instructions from the website Ask the teacher. All the 10,000 samples were reviewed by around 12 reviewers. The HuggingFace page has more information on the datasets and has some preview samples separately.