
Articles
We covered Mamba as an introduction in one of the previous newsletter:
Google open-sources Gemma(2B, 7B parameter models)

Articles Google launches their new model series called Gemma. After disastrous rollout of Gemini, they wanted to also open-source smaller models for community to try out and adopting for their GCP(Google Cloud Platform) more when it comes to try out the models.

This article from Gradient expands a lot more about the advantages and technical details with comparison to Transformers:
Limitations of Transformers(now it should be obvious to everyone as talked in the previous newsletter!):
Quadratic Bottleneck: Transformers use an attention mechanism that allows every token to look at every other token in the sequence, leading to a quadratic increase in training time complexity for long sequences.
Memory Bottleneck: Storing information about all previous tokens requires a lot of memory, making it difficult to handle very long sequences.
In the article, they separate the Transformer broadly into two different parts; Communication(mostly multi-head attention) and Computation(feed forward) with the idea that communication will be done between tokens and computation will happen for a given token. This is the first time I have seen this phrasing and it makes a lot of sense intuitively.

Mamba uses a different approach for communication between tokens. It employs a Control Theory-inspired State Space Model (SSM) that focuses on relevant information from the past instead of attending to everything.

Mamba’s usage of this approach is three-layered rather than two layers unlike Transofrmers. Mamba does computation in the linear projection layer and communication in the sequence transformation layer along with convolution layer(as the convolution itself will happen between tokens).
Before going further, taking a step back to explain the key concepts in Mamba:
State: Mamba maintains a state that captures the essential information about the past that is relevant for predicting the next element in the sequence.
Selection Mechanism: Unlike a traditional SSM where all tokens are treated equally, Mamba uses a selection mechanism that dynamically adjusts how much information is included in the state for each token. This allows Mamba to be more efficient than Transformers while still capturing important information for long sequences.

Due to state based approach and selection mechanism; Mamba shines in two aspects comparing to Transformers; efficiency and long term memory; which allows better long term memory state along with better representation of the sequence handling for long sequences.
Efficiency: Mamba is more efficient than Transformers for long sequences due to its state-based approach and selection mechanism.
Long-term Memory: Mamba can handle very long sequences because it focuses on the most relevant information and forgets less relevant details.
Effectiveness vs. Efficiency Trade-off: Transformers are more effective for short sequences due to their ability to attend to all information, but they become less efficient for longer sequences. Mamba offers a better balance between effectiveness and efficiency for long sequences.
Information Flow: Transformers rely on short-term memory (context window) while Mamba utilizes a "hard drive" like long-term memory (state).

Jina.ai wrote an article on DSPy, popular framework that makes it easy to compose generative AI applications.
The main problem that DSPy solves in the prompt engineering is the process of creating instructions for large language models (LLMs) in a way that gets the desired output. It is a complex task that requires understanding the capabilities and limitations of LLMs as well as the specific task at hand. DSPy aims to automate this process by breaking it down into smaller, more manageable components.
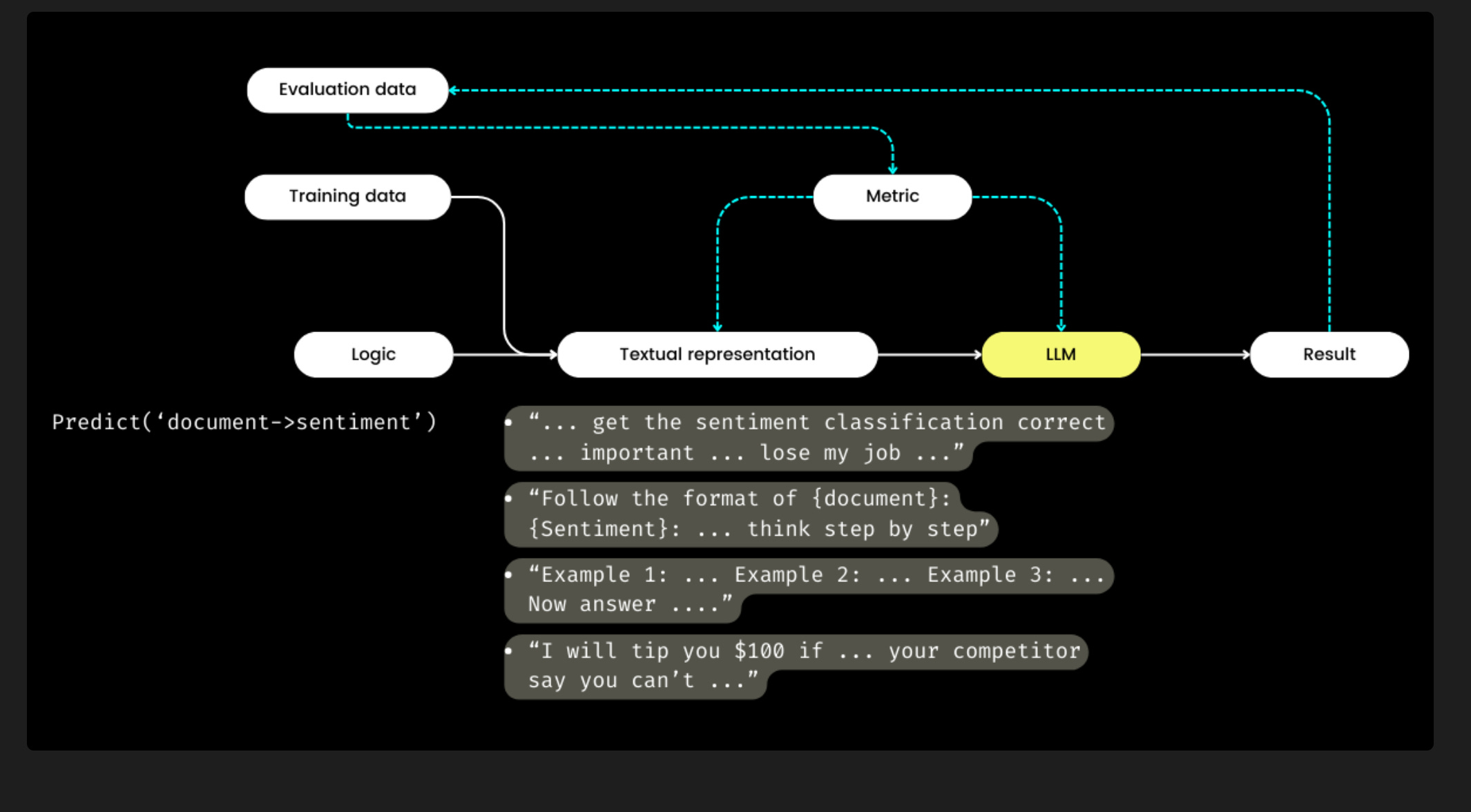
One of the key challenges in prompt engineering is the separation of concerns between the logic of the prompt and the wording used to express that logic. The logic of the prompt specifies what the LLM should do, while the wording is how the prompt is phrased. DSPy addresses this challenge by allowing users to specify the logic of the prompt separately from the wording. This allows DSPy to optimize the wording of the prompt using machine learning techniques.
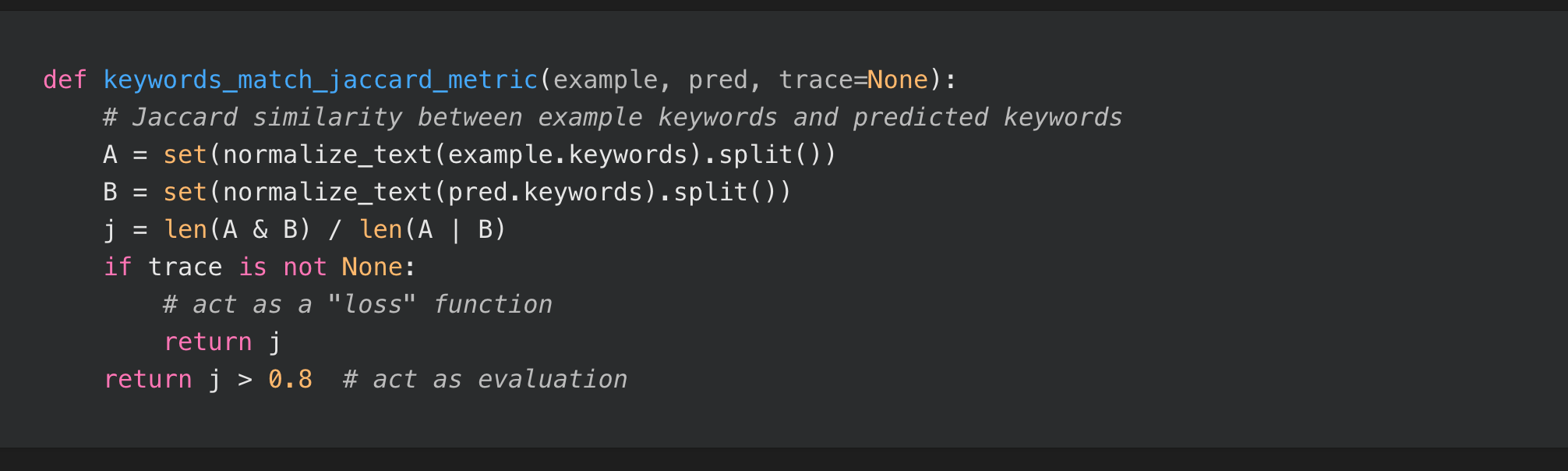
To optimize the wording of a prompt, DSPy requires data and evaluation metrics. The data is used to train the machine learning model, while the evaluation metrics are used to measure the performance of the prompt. DSPy can use a variety of machine learning techniques to optimize the wording of a prompt, such as reinforcement learning or evolutionary algorithms.

DSPy offers the following advantages:
Improved Prompt Quality: By separating the logic from the wording of the prompt, DSPy can help users to create prompts that are more effective at getting the desired output from LLMs.
Reduced Time and Effort: DSPy can automate some of the tasks involved in prompt engineering, such as finding the optimal wording for a prompt. This can save users time and effort.
Increased Reproducibility: By making prompt engineering more systematic, DSPy can help to improve the reproducibility of LLM results.
However, there are also some challenges associated with using DSPy:
Complexity: DSPy is a new framework, and it can be complex to learn and use.
Data Requirements: DSPy requires data to train the machine learning model that is used to optimize the wording of prompts. This data can be difficult to obtain in some cases.
Evaluation Metrics: DSPy requires evaluation metrics to measure the performance of prompts. These metrics can be difficult to define in some cases.
If you want to understand terminology and want an approachable introduction to DSPy, I recommend this article.
Libraries
bin2ml is a command line tool to extract machine learning ready data from software binaries. It's ideal for researchers and hackers to easily extract data suitable for training machine learning approaches such as natural language processing (NLP) or Graph Neural Networks (GNN's) models using data derived from software binaries.
Extract a range of different data from binaries such as Attributed Control Flow Graphs, Basic Block random walks and function instructions strings powered by Radare2.
Multithreaded data processing throughout powered by Rayon.
Save processed data in ready to go formats such as graphs saved as NetworkX compatible JSON objects.
Experimental support for creating machine learning embedded basic block CFG's using
tch-rsand TorchScript traced models.

The RAPTOR paper presents an interesting approaching for indexing and retrieval of documents:
The
leafsare a set of starting documentsLeafs are embedded and clustered
Clusters are then summarized into higher level (more abstract) consolidations of information across similar documents
This process is done recursivly, resulting in a "tree" going from raw docs (leafs) to more abstract summaries.
We can applying this at varying scales; leafs can be:
Text chunks from a single doc (as shown in the paper)
Full docs (as we show below)
With longer context LLMs, it's possible to perform this over full documents.
This Jupyter notebook shows how it works under the hood well.

AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. You can also provide a video to achieve face reenacment.

RestAI is an AIaaS (AI as a Service) for everyone. Create agents (projects) and consume them using a simple REST API.
Features
Projects: There are multiple types of agents (projects), each with its own features. (rag, ragsql, inference, vision)
Users: A user represents a user of the system. It's used for authentication and authorization (basic auth). Each user may have access to multiple projects.
LLMs: Supports any public LLM supported by LlamaIndex or any local LLM suported by Ollama.
VRAM: Automatic VRAM management. RestAI will manage the VRAM usage, automatically loading and unloading models as needed and requested.
API: The API is a first-class citizen of RestAI. All endpoints are documented using Swagger.
Frontend: There is a frontend available at restai-frontend
Long Form Factuality is accompanying Deepmind’s paper "Long-form factuality in large language models". This repository contains:
LongFact: A prompt set of 2,280 fact-seeking prompts requiring long-form responses.
Search-Augmented Factuality Evaluator (SAFE): Automatic evaluation of model responses in long-form factuality settings.
F1@K: Extending F1 score to long-form settings using recall from human-preferred length.
Experimentation pipeline for benchmarking OpenAI and Anthropic models using LongFact + SA