Google Releases Gemini
Deepmind Releases Graphcast and Lyric; Weather Prediction and Music Generation

Articles

Google releases Gemini which is a large Foundation Model that beats Human Expert benchmark on MMLU(Massive Multitask Language Understanding) in the largest model that they have trained “Gemini Ultra”.
It has the following capabilities and benefits:
Capabilities:
Multimodal understanding: Gemini can process a wide range of information, including text, code, audio, images, and video. This allows it to perform tasks that were previously impossible for AI systems, such as generating realistic images from text descriptions or translating languages with perfect fluency.
Real-time decision making: It can process information and make decisions in real time, making it ideal for applications such as robotics and self-driving cars.
Unparalleled accuracy: It is trained on a massive dataset of text and code, which allows it to achieve state-of-the-art performance on a variety of tasks.
Benefits:
Increased productivity: Gemini can automate many tasks that are currently performed by humans, freeing up people to focus on more creative and strategic work.
Improved decision making: It can provide insights and recommendations that can help businesses and organizations make better decisions.
Enhanced creativity: It can be used to generate new ideas and content, such as poems, code, scripts, and musical pieces.

They have released a report around some of the details and benchmarks that they have conducted as well.
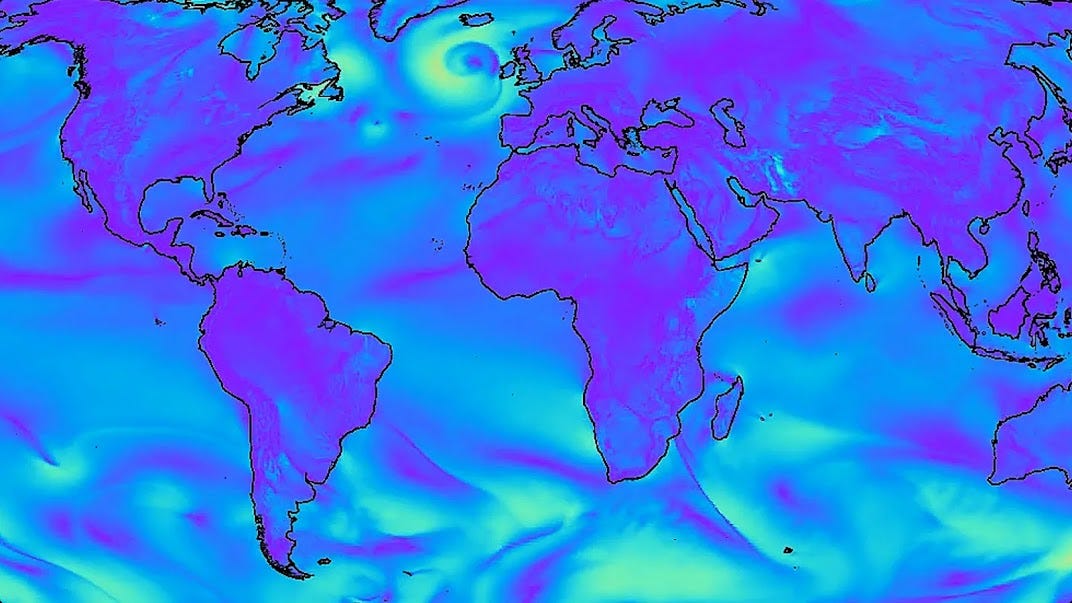
Google Deepmind built a new model called GraphCast, which is a new AI model for weather forecasting that can make more accurate and faster predictions than traditional models. It was trained on a large amount of historical weather data and can predict the weather up to 10 days in advance.GraphCast can also identify extreme weather events earlier than traditional models, which has the potential to save lives and reduce the impact of extreme weather events.
GraphCast is already being used by some weather agencies, and the model code is open sourced(in below Libraries section, I gave couple of pointers).
It uses a graph neural network (GNN) to model the relationships between different weather variables. This allows it to capture complex relationships that traditional models cannot.
It attention to focus on the most important parts of the data. This helps to improve the accuracy of the predictions.
It is able to make predictions at a high resolution which is a net positive advantage of all of the existing models as they cannot make predictions on such a granular high accuracy as well as Graphcast does.
Libraries

tinyvector - the tiny, least-dumb, speedy vector embedding database.
Tiny: It's in the name. It's just a Flask server, SQLite DB, and Numpy indexes. Extremely easy to customize, under 500 lines of code.
Fast: Tinyvector wlll have comparable speed to advanced vector databases when it comes to speed on small to medium datasets.
Vertically Scales: Tinyvector stores all indexes in memory for fast querying. Very easy to scale up to 100 million+ vector dimensions without issue.
Open Source: MIT Licensed, free forever.
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over structured data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to:
Allow business users to get insights from the data warehouse without going through a data analyst
Enable Q+A from your production DBs inside your SaaS application
Create a ChatGPT plug-in from your proprietary data

This library is an implementation of ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs in PyTorch.
The paper summary by the author is found here.

A Unified Library for Parameter-Efficient and Modular Transfer Learning
adapters is an add-on to HuggingFace's Transformers library, integrating adapters into state-of-the-art language models by incorporating AdapterHub, a central repository for pre-trained adapter modules.

DSPy is the framework for solving advanced tasks with language models (LMs) and retrieval models (RMs). DSPy unifies techniques for prompting and fine-tuning LMs — and approaches for reasoning, self-improvement, and augmentation with retrieval and tools. All of these are expressed through modules that compose and learn.
To make this possible:
DSPy provides composable and declarative modules for instructing LMs in a familiar Pythonic syntax. It upgrades "prompting techniques" like chain-of-thought and self-reflection from hand-adapted string manipulation tricks into truly modular generalized operations that learn to adapt to your task.
DSPy introduces an automatic compiler that teaches LMs how to conduct the declarative steps in your program. Specifically, the DSPy compiler will internally trace your program and then craft high-quality prompts for large LMs (or train automatic finetunes for small LMs) to teach them the steps of your task.
The DSPy compiler bootstraps prompts and finetunes from minimal data without needing manual labels for the intermediate steps in your program. Instead of brittle "prompt engineering" with hacky string manipulation, you can explore a systematic space of modular and trainable pieces.
TaskMatrix connects ChatGPT and a series of Visual Foundation Models to enable sending and receiving images during chatting.
See their paper: Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models

Fairseq(-py) is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks.

Danswer allows you to ask natural language questions against internal documents and get back reliable answers backed by quotes and references from the source material so that you can always trust what you get back. You can connect to a number of common tools such as Slack, GitHub, Confluence, amongst others.
Tutorials/Classes

Microsoft has a Generative AI introduction that has 12 different classes that go in details of various technologies of LLMs and Foundation Models. A lot of people reached out last week after the introduction by Andrej Karpathy and this would be a good continuation of that introduction that I mentioned last week.
Graphcast contains example code to run and train GraphCast. It also provides three pretrained models:
GraphCast, the high-resolution model used in the GraphCast paper (0.25 degree resolution, 37 pressure levels), trained on ERA5 data from 1979 to 2017,GraphCast_small, a smaller, low-resolution version of GraphCast (1 degree resolution, 13 pressure levels, and a smaller mesh), trained on ERA5 data from 1979 to 2015, useful to run a model with lower memory and compute constraints,GraphCast_operational, a high-resolution model (0.25 degree resolution, 13 pressure levels) pre-trained on ERA5 data from 1979 to 2017 and fine-tuned on HRES data from 2016 to 2021. This model can be initialized from HRES data (does not require precipitation inputs).