Pruning Aware Training(PAT) in LLMs
Posterior, LLMRank, Depth Pro

Articles

(Image is taken from Model Optimization Toolkit page from Tensorflow)
Pruning Aware Training
Pruning in deep learning refers to the process of removing unnecessary weights or neurons from a neural network to reduce its size and computational requirements while maintaining performance. Traditionally, pruning has been applied after training, but this approach often leads to significant performance degradation, especially for large language models.
Pruning Aware Training (PAT) is a new paradigm that aims to address this issue by incorporating pruning considerations during the training process itself. This approach is similar to Quantization Aware Training(QAT) that I have covered before, but the function and also how to mitigate some of the loss varies in the pruning case. However, the as part of PAT outcome is similar in that allows the model to adapt to sparsity constraints gradually, potentially leading to better performance retention at higher pruning ratios.
Why do we want to reduce model size?
We generally want smaller models due to following reasons:
1. Deployment Constraints: Many real-world applications require models to run on edge devices with limited computational resources and memory.
2. Inference Latency: Smaller models can process inputs faster, which is critical for real-time applications like chatbots or voice assistants.
3. Energy Efficiency: Compressed models consume less energy, making them more environmentally friendly and suitable for battery-powered devices.
4. Bandwidth Requirements: Smaller models are easier to distribute and update over networks with limited bandwidth.
5. Cost Considerations: Reduced computational requirements can lead to significant cost savings in cloud-based deployments.
There are multiple post-training pruning approaches. This is one category of pruning approaches that are different than pruning aware training approaches, but it is important to understand them first as the application of pruning aware training uses some of these functions and apply them in the training time.
Magnitude-based Pruning
This is one of the simplest pruning techniques, where weights with the smallest absolute values are removed. The assumption is that these weights contribute the least to the model's output.
Advantages:
Easy to implement
Computationally efficient
Disadvantages:
May remove important weights that have small magnitudes but significant impact
Often leads to significant performance degradation at high pruning ratios
Gradient-based Pruning
This method uses gradient information to determine the importance of weights. Weights with small gradients are considered less important and are pruned.
Advantages:
More informed than magnitude-based pruning
Can capture the dynamic importance of weights during training
Disadvantages:
Computationally more expensive
May be sensitive to noisy gradients
Structured Pruning
Instead of pruning individual weights, structured pruning removes entire neurons or filters. This can lead to more hardware-friendly sparse models.
Advantages:
Results in models that are easier to accelerate on existing hardware
Can lead to significant reductions in model size and computation
Disadvantages:
Often results in higher performance degradation compared to unstructured pruning
Less flexible than fine-grained pruning
Iterative Pruning
This approach involves alternating between pruning and fine-tuning steps. After each pruning step, the model is retrained to recover performance.
This is also most similar to the pruning aware training with respect to recouping the model accuracy after a while. However, it does not do the pruning at the time of training.
Advantages:
Can achieve higher pruning ratios while maintaining performance
Allows for gradual adaptation to sparsity
Disadvantages:
Time-consuming due to multiple rounds of pruning and retraining
May still struggle with very high pruning ratios

Pruning Aware Training(PAT)
Okay, we went through all of these methods, but why do we need PAT over all of these methods given we have a set of approaches that provide different advantages and disadvantages separately? Of course, we can do better than all of these approaches separately. PAT offers several advantages over traditional post-training pruning approaches:
Improved Model Quality
PAT can significantly reduce the performance degradation typically associated with pruning, especially for LLMs. By considering sparsity during training, the model learns to distribute its knowledge across the remaining weights more effectively.
Efficient Resource Utilization
By incorporating pruning considerations from the start, models can be optimized for deployment on resource-constrained devices throughout the entire training process. This leads to more efficient use of computational resources during both training and inference.
Compatibility with Existing Workflows
PAT can often be integrated into existing training pipelines with minimal modifications. This makes it easier for organizations to adopt without completely overhauling their model development processes.
Effectiveness at Higher Sparsity Levels
PAT has shown promising results even at high pruning ratios where post-training pruning often fails. This is particularly important for LLMs, where achieving high compression rates is crucial for practical deployment.
Integration with Fine-tuning
PAT can be applied during model fine-tuning, allowing for task-specific optimization. This is especially valuable in transfer learning scenarios, where a pre-trained model is adapted to a specific downstream task.
Better Generalization
PAT may lead to better generalization by acting as a form of regularization. The sparsity constraints can help prevent overfitting and encourage the model to learn more robust features and model might generalize better and could be more robust to noise.
How PAT works?
The key idea behind PAT is to simulate the effects of pruning during the training process. This typically involves several components and techniques:
Gradual Sparsity Introduction
Instead of applying pruning all at once, PAT gradually increases sparsity over the course of training. This is usually done according to a predefined schedule, which can be linear, exponential, or follow more complex patterns.
Example Schedule:
def cubic_schedule(t, t_end):
return (t / t_end) ** 3
This schedule would increase the pruning ratio cubically from 0 to the target sparsity over the course of training.

Importance Score Calculation
Weights are assigned importance scores based on various criteria. Common approaches include:
- Magnitude: The absolute value of the weight
- Gradient-based: The product of the weight and its gradient
- Movement: The amount a weight has changed during training
- Second-order information: Using Hessian approximations to estimate weight importance
Some of the post-training pruning approaches above might use these functions as well.
Example: Magnitude-based importance scoring
def calculate_importance(module):
return torch.abs(module.weight.data)
Dynamic Mask Application
A binary mask is applied to the weights, with the mask updated periodically based on the importance scores. The mask determines which weights are active (1) and which are pruned (0).
Example: Updating the mask based on importance scores
def update_mask(module, sparsity):
importance = calculate_importance(module)
threshold = torch.quantile(importance, sparsity)
return (importance > threshold).float()
This method requires more attention as the mask itself very important for pruning as we want to eventually remove a number of weights in the model and through this, we want to remove. Learning mask, applying this mask post-training and/or through training is key to anything that we do in pruning.
Sparse Gradient Updates
Only non-pruned weights receive gradient updates, encouraging the model to adapt to the sparse structure. This is typically implemented by applying the mask during the backward pass.
Example: Applying the mask during backward pass
def backward_hook(module, grad_input, grad_output):
module.weight.grad *= module.weight_mask
This allows model to learn better/robust features and act like a good sparse regularizer overall.
Pruning Schedule
The pruning ratio is increased according to a predefined schedule, allowing the model to gradually adapt to higher levels of sparsity. This schedule can be adjusted based on validation performance or other metrics.
Example: Updating sparsity based on a schedule
def update_sparsity(epoch, total_epochs, final_sparsity):
return final_sparsity * cubic_schedule(epoch, total_epochs)
Within the sculler approach, one can adapt very simple scheduler schemes like one time sparsification, one can also adapt regulary/recurring updates such as odd/even scheme where one epoch you force sparsification to take place and in other epoch, you allow model to recover from the sparsity induced. This allows model to gradually adjust the sparsity induction rather than at one time to respond to the sparsification of the model.
Layerwise Adaptive Sparsity
Different layers in a neural network may have different sensitivities to pruning. PAT can apply different pruning ratios to different layers based on their importance or other criteria.
Example: Layerwise sparsity assignment
def assign_layerwise_sparsity(model, global_sparsity):
layer_importances = calculate_layer_importances(model)
return distribute_sparsity(layer_importances, global_sparsity)
On top of these, one can make the PAT even more efficient and better my slightly modifying either the scheduler or the function that has been applied to.
Optimization Techniques for PAT
Layerwise Adaptive Sparsity
Different layers in a neural network may have different sensitivities to pruning. Layerwise adaptive sparsity involves applying different pruning ratios to different layers based on their importance or other criteria.
1. Calculate layer importance scores based on metrics like gradient magnitude or activation statistics.
2. Distribute the global sparsity budget across layers, allocating more sparsity to less important layers.
3. Apply layer-specific pruning ratios during the PAT process.
This has the following advantages of “vanilla” layer wise adaptive sparsity:
Improved performance by preserving important layers
More efficient use of the sparsity budget
Attention Head Pruning
In transformer-based models, not all attention heads contribute equally to the model's performance. Attention head pruning focuses on removing entire attention heads rather than individual weights.
1. Calculate importance scores for each attention head based on metrics like attention entropy or gradient-based measures.
2. Prune entire attention heads with the lowest importance scores.
3. Adjust the remaining heads to compensate for the removed ones.
Advantages:
Significant reduction in computational complexity
Potential for improved interpretability of the model
Structured Pruning
While unstructured pruning can achieve higher sparsity ratios, structured pruning can lead to more hardware-friendly sparse models. Structured pruning focuses on removing entire neurons or filters instead of individual weights.
1. Calculate importance scores for neurons or filters based on criteria like L1-norm or feature map statistics.
2. Remove entire neurons or filters with the lowest importance scores.
3. Adjust the remaining network structure to maintain connectivity.
Advantages:
Easier to accelerate on existing hardware
Potential for greater reductions in model size and computation
Pruning Reversal
Sometimes, weights that were initially pruned may become important later in training. Pruning reversal allows temporarily pruned weights to be reintroduced if they become important.
1. Maintain a record of pruned weights and their last known values.
2. Periodically reassess the importance of pruned weights.
3. Reintroduce pruned weights that have become important, possibly pruning others to maintain the target sparsity.
Advantages:
Increased flexibility in adapting to changing importance during training
Potential for improved final performance
Dynamic Sparse Training
Instead of following a fixed pruning schedule, dynamic sparse training adjusts the sparsity pattern during training based on the current state of the model.
1. Start with a random sparse mask.
2. Periodically update the mask based on weight magnitudes or gradients.
3. Allow a small fraction of weights to be regrown in each update.
Advantages:
Adapts to the evolving needs of the model during training
Can potentially find better sparse configurations than static approaches
Why does not everyone adapt PAT?
After all of these, if you think, then, why do not everyone adapt the PAT? Because there are some challenges to adapt for all of the workflows it has some challenges as well.
Training Time
PAT can increase training time due to the additional computations required for importance score calculation and mask updates. This overhead can be significant, especially for large models.
Mitigation Approaches:
Optimize importance score calculations and mask updates
Use efficient sparse matrix operations where possible
Consider less frequent mask updates or importance recalculations
Memory Usage
Storing importance scores and masks can increase memory requirements during training. This can be particularly challenging for large language models that already push the limits of GPU memory.
Mitigation Approaches:
Use memory-efficient data types for storing masks and importance scores
Implement gradient checkpointing to trade computation for memory
Consider distributed training approaches to spread the memory load across multiple devices
Hyperparameter Tuning
Finding the optimal pruning schedule and importance criteria may require additional experimentation. This can significantly increase the computational resources needed for model development.
Mitigation Approaches:
Develop heuristics or automated methods for selecting pruning schedules
Use efficient hyperparameter optimization techniques like Bayesian optimization
Leverage transfer learning to reuse successful pruning configurations across similar tasks
Hardware Acceleration
Realizing the full benefits of pruning often requires specialized hardware support for sparse operations. Many current hardware accelerators are optimized for dense matrix operations and may not fully capitalize on the sparsity introduced by pruning.
Mitigation Approaches:
Explore structured pruning approaches that are more amenable to current hardware
Investigate software optimizations for sparse operations on existing hardware
Collaborate with hardware manufacturers to develop pruning-aware accelerators
Model Accuracy at Extreme Sparsity
While PAT generally outperforms post-training pruning, maintaining model accuracy at very high sparsity levels (e.g., >90%) remains challenging, especially for complex tasks.
Mitigation Approaches:
Combine PAT with other compression techniques like quantization or knowledge distillation
Investigate more sophisticated importance criteria and pruning strategies
Consider task-specific pruning approaches that leverage domain knowledge
These could be tradeoffs that need to be thought through to make a tradeoff decision between advantage that pruning aware training might bring and some of the disadvantages of the approaches.
Libraries

posteriors is a general purpose python library for uncertainty quantification with PyTorch.
Composable: Use with
transformers,lightning,torchopt,torch.distributions,pyroand more!Extensible: Add new methods! Add new models!
Functional: Easier to test, closer to mathematics!
Scalable: Big model? Big data? No problem!
Swappable: Swap between algorithms with ease!
A blog post from Normal Computing goes in detail on the motivations and some of the design decisions hat went into this library.

fully local taxi-driver language assistant provides a fully local language assistant called berto. berto can listen to your audio, transcribe it using whisper, and then interact with you in spanish using an ai model served locally via ollama. it also has text-to-speech capabilities to provide audio responses. 🗣️
🌟 features
local transcription of spoken language using whisper. 🎤
interaction with an ai model (llama 2 uncensored) served locally via ollama. 🦙
conversation options, including following up on questions related to science, history, and politics. ❓
text-to-speech responses using edge tts. 🔊
audio playback of berto's responses. 🎧
SASRec: Self-Attentive Sequential Recommendation is TensorFlow implementation for the paper:
Wang-Cheng Kang, Julian McAuley (2018). Self-Attentive Sequential Recommendation. In Proceedings of IEEE International Conference on Data Mining (ICDM'18)

Depth Pro: Sharp Monocular Metric Depth in Less Than a Second accompanies the research paper: Depth Pro: Sharp Monocular Metric Depth in Less Than a Second, Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, and Vladlen Koltun.
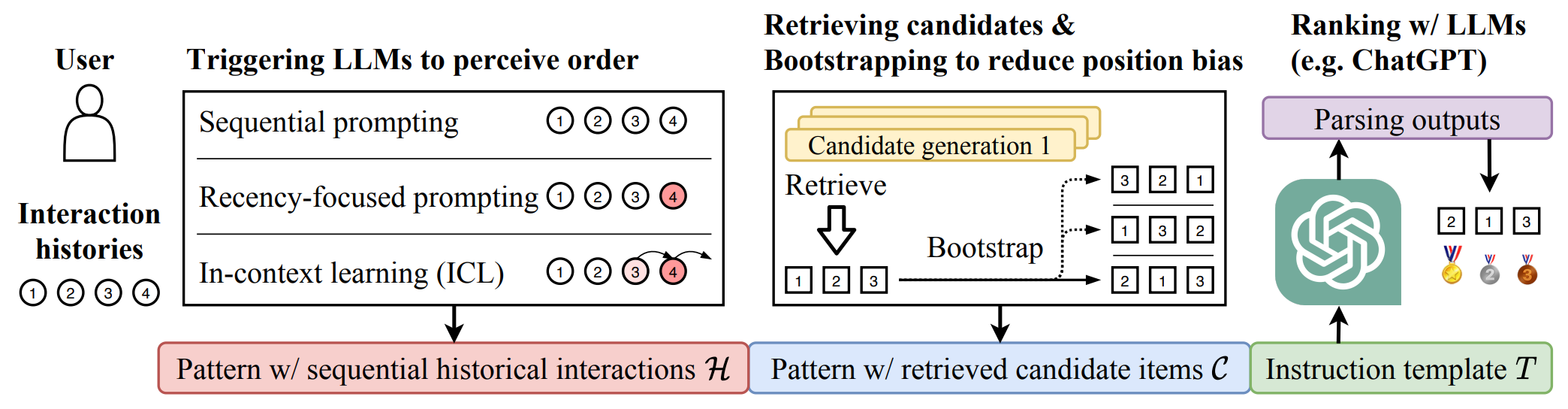
LLMRank aims to investigate the capacity of LLMs that act as the ranking model for recommender systems. [paper]
Yupeng Hou†, Junjie Zhang†, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, Wayne Xin Zhao. Large Language Models are Zero-Shot Rankers for Recommender Systems. ECIR 2024.