

XGen, a 7B LLM trained on up to 8K sequence length from SalesForce
Climax: Foundation Model for Weather and Climate

Articles
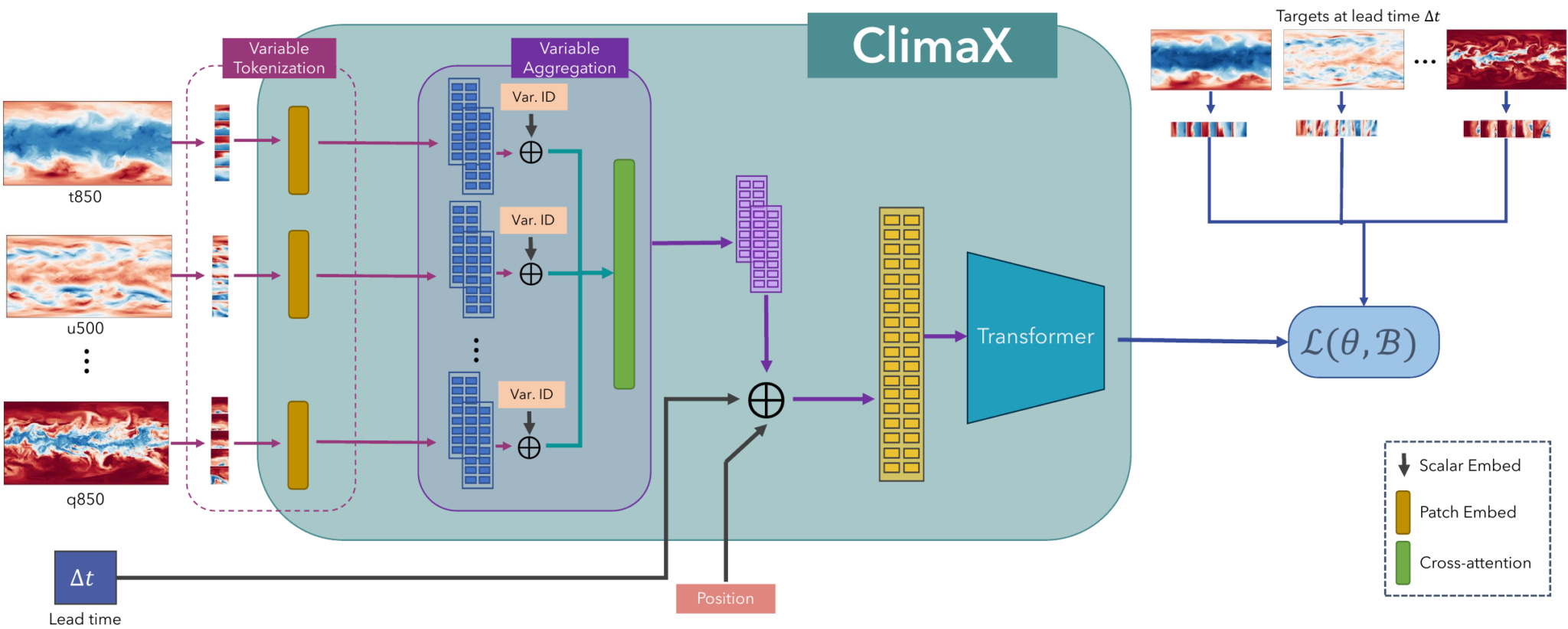
Microsoft Research introduces ClimaX, a foundation model for weather and climate science. ClimaX is a deep learning model that is trained on a variety of heterogeneous datasets spanning many weather variables at multiple spatio-temporal resolutions. The model is designed to be generalizable and can be fine-tuned to address a wide variety of weather and climate tasks, including those that involve atmospheric variables and spatio-temporal granularities unseen during pretraining.
The key insight behind ClimaX is the realization that all the prediction and modeling tasks in weather and climate science are based on physical phenomena and their interactions with the local and global geography. ClimaX is designed to capture these physical relationships by using a transformer-based architecture that is able to learn long-range dependencies.
The article demonstrates the effectiveness of ClimaX on a variety of weather and climate tasks, including:
Forecasting temperature, humidity, and other weather variables
Predicting extreme weather events
Downscaling climate model outputs to higher resolutions
The post concludes that ClimaX is a promising new tool for weather and climate science. The model is generalizable, efficient, and can be used to address a wide variety of tasks. The post makes the claim that ClimaX has the potential to revolutionize the way we study and predict weather and climate.
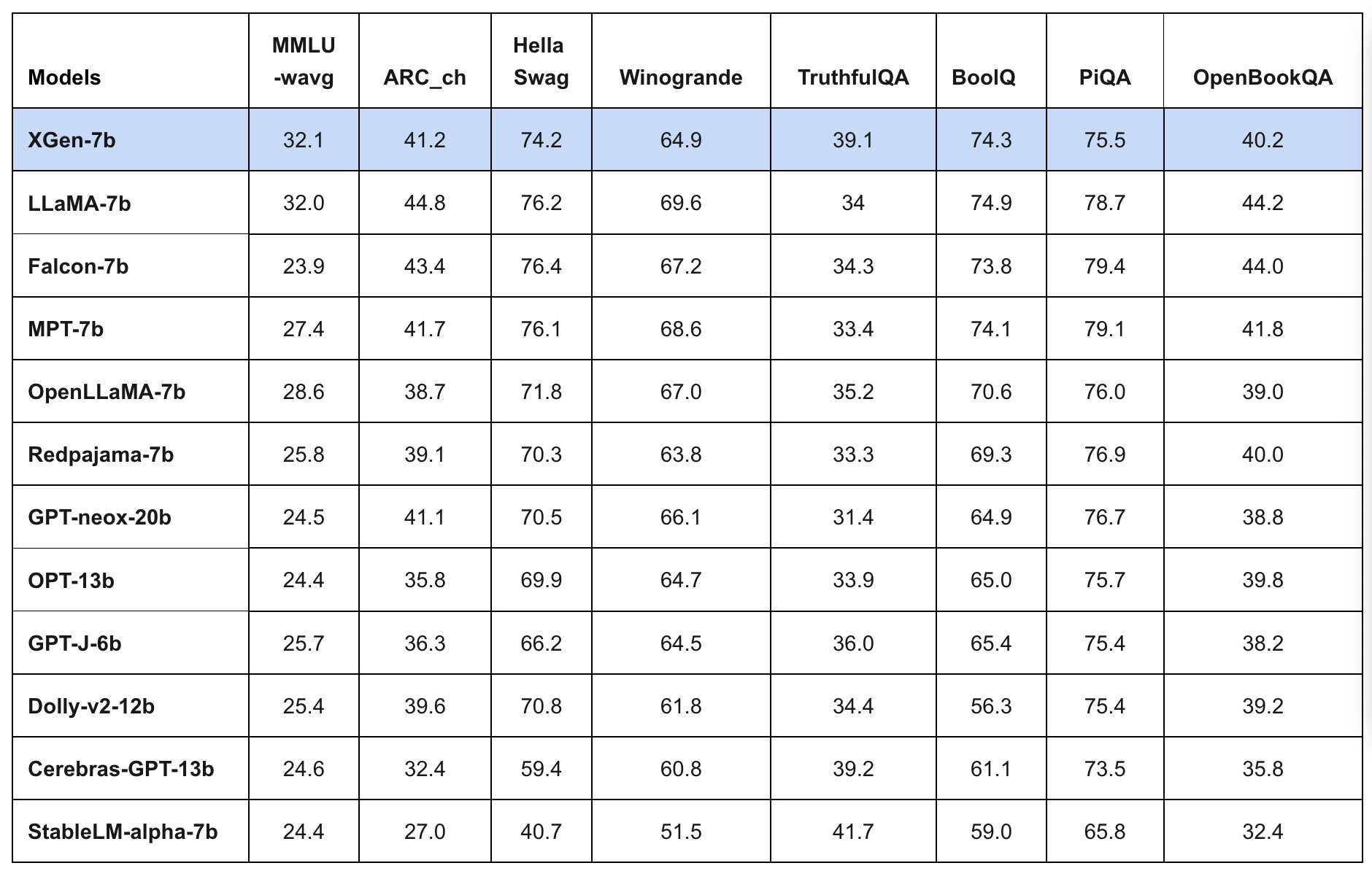
Salesforce AI Research introduces XGen, a 7B LLM (large language model) trained on up to 8K sequence length for up to 1.5T tokens. The model is fine-tuned on public-domain instructional data.
Blog post compares XGen to other LLMs of similar size and show that XGen achieves comparable or better results on a variety of tasks, including:
MMLU: A benchmark for measuring the ability of LLMs to understand and generate natural language.
QA: A benchmark for measuring the ability of LLMs to answer questions in natural language.
HumanEval: A benchmark for measuring the ability of LLMs to generate code that is similar to code written by humans.
XGen is a promising new LLM that is capable of achieving state-of-the-art results on a variety of tasks and it has the following technical capabilities:
XGen is a 7B LLM trained on up to 8K sequence length for up to 1.5T tokens.
XGen is fine-tuned on public-domain instructional data.
XGen achieves comparable or better results on a variety of tasks, including MMLU, QA, and HumanEval.
XGen is a promising new LLM that is capable of achieving state-of-the-art results on a variety of tasks.

OpenAI announces the general availability of the GPT-4 API. The API allows developers to access GPT-4, OpenAI's latest and most powerful language model.
GPT-4 is a 175B parameter transformer model trained on a massive dataset of text and code. It is capable of generating text, translating languages, writing different kinds of creative content, and answering your questions in an informative way.
The API is available to all developers, and there is a free tier that allows you to use GPT-4 for up to 500 requests per month. There are also paid tiers that offer more requests and features.
The blog post also discusses some of the benefits of using the GPT-4 API, including:
Ease of use: The API is easy to use and requires no prior experience with machine learning.
Powerful: GPT-4 is a powerful language model that can be used for a variety of tasks.
Flexible: The API is flexible and can be used to integrate GPT-4 into your own applications.

CMU published a post for ReLM which is an automaton-based constrained decoding system that sits on top of the LLM.
ReLM uses a compact graph representation of the solution space, which is derived from regular expressions and then compiled into an LLM-specific representation. This allows users to measure the behavior of LLMs without having to understand the intricacies of the model.
ReLM can be used to validate LLMs on a variety of tasks, including:
Memorization: Checking for patterns that indicate that the LLM has memorized data from its training set.
Bias: Checking for patterns that indicate that the LLM is biased towards certain groups of people or topics.
Toxicity: Checking for patterns that indicate that the LLM is generating text that is offensive or harmful.
Language understanding: Checking for patterns that indicate that the LLM is not understanding the meaning of the text that it is generating.
Libraries

CodeTF is a one-stop Python transformer-based library for code large language models (Code LLMs) and code intelligence, provides a seamless interface for training and inferencing on code intelligence tasks like code summarization, translation, code generation and so on. It aims to facilitate easy integration of SOTA CodeLLMs into real-world applications.
In addition to the core LLMs's features for code, CodeTF offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, it enables parsing of attributes such as function names, comments, and variable names. Pre-built libraries for numerous languages are provided, eliminating the need for complicated parser setup. CodeTF thus ensures a user-friendly and accessible environment for code intelligence tasks.
The current version of the library offers:
Fast Model Serving: We support an easy-to-use interface for rapid inferencing with pre-quantized models (int8, int16, float16). CodeTF handles all aspects of device management, so users do not have to worry about that aspect. If your model is large, we offer advanced features such as weight sharding across GPUs to serve the models more quickly.
Fine-Tuning Your Own Models: We provide an API for quickly fine-tuning your own LLMs for code using SOTA techniques for parameter-efficient fine-tuning (HuggingFace PEFT) on distributed environments.
Supported Tasks: nl2code, code summarization, code completion, code translation, code refinement, clone detection, defect prediction.
Datasets+: We have preprocessed well-known benchmarks (Human-Eval, MBPP, CodeXGLUE, APPS, etc.) and offer an easy-to-load feature for these datasets.
Model Evaluator: We provide interface to evaluate models on well-known benchmarks (e.g. Human-Eval) on popular metrics (e.g., pass@k) with little effort (~15 LOCs).
Pretrained Models: We supply pretrained checkpoints of state-of-the-art foundational language models of code (CodeBERT, CodeT5, CodeGen, CodeT5+, Incoder, StarCoder, etc.).
Fine-Tuned Models: We furnish fine-tuned checkpoints for 8+ downstream tasks.
Utility to Manipulate Source Code: We provide utilities to easily manipulate source code, such as user-friendly AST parsers (based on tree-sitter) in 15+ programming languages, to extract important code features, such as function name, identifiers, etc.
The 'llama-recipes' repository is a companion to the Llama 2 model. The goal of this repository is to provide examples to quickly get started with fine-tuning for domain adaptation and how to run inference for the fine-tuned models. For ease of use, the examples use Hugging Face converted versions of the models. See steps for conversion of the model here.
Llama 2 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios. In order to help developers address these risks, we have created the Responsible Use Guide. More details can be found in our research paper as well. For downloading the models, follow the instructions on Llama 2 repo.
NewHope, a chat model based on llama-2-13b, aiming to provide a strong coding capability. NewHope handle different languages including Python, C++, Java, JavaScript, Go, and more. Preliminary evaluation on HumanEval shows that NewHope possesses 99% of GPT-4's programming capabilities.