
Articles

Google published a blog post on their VDTTS(Visually Driven Text to Speech) model, it follows their earlier Tacotron model. It reports better results than the other models when it comes to dubbing for integrating speech into videos.

Google published another paper that follows Pathways in the language model domain and published a blog post. This model is Transformer based model that has 540B parameters.
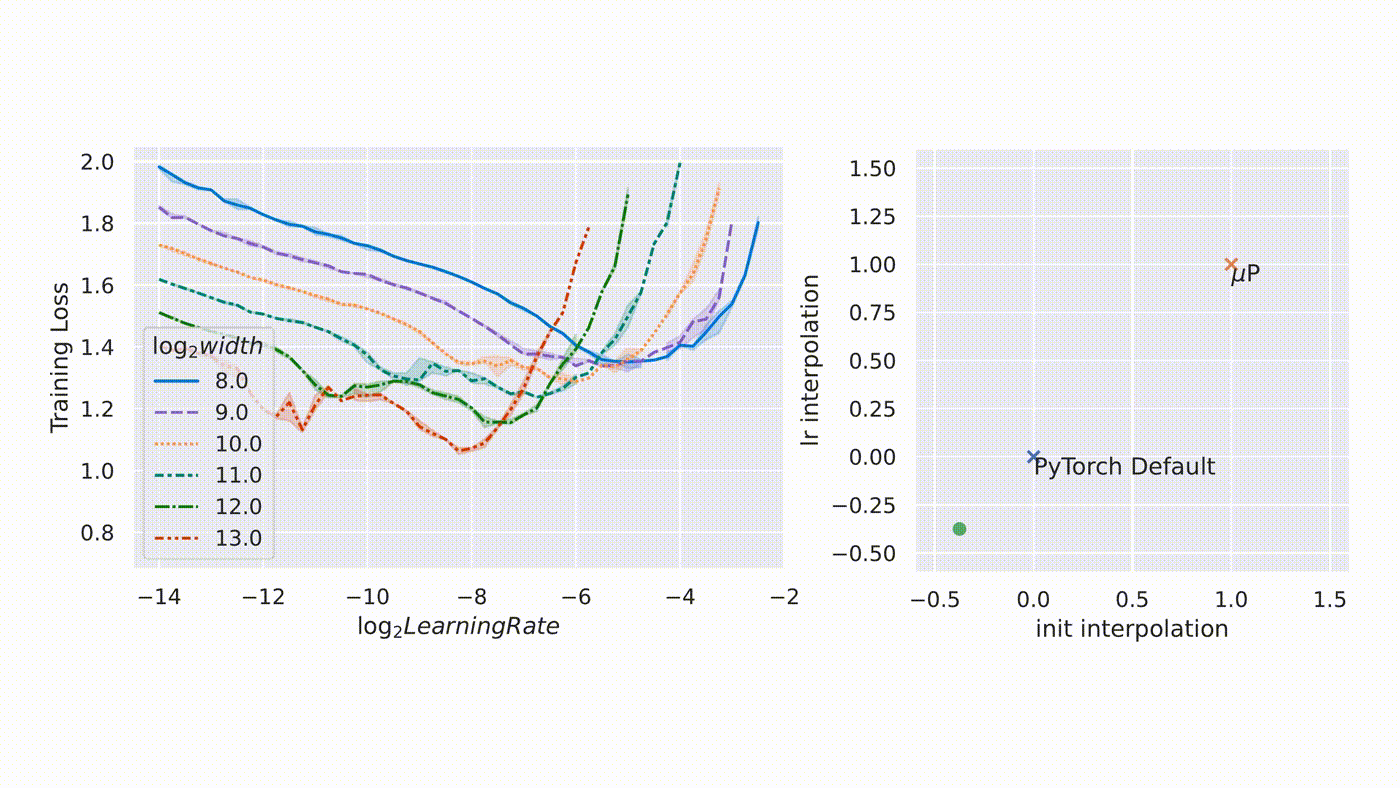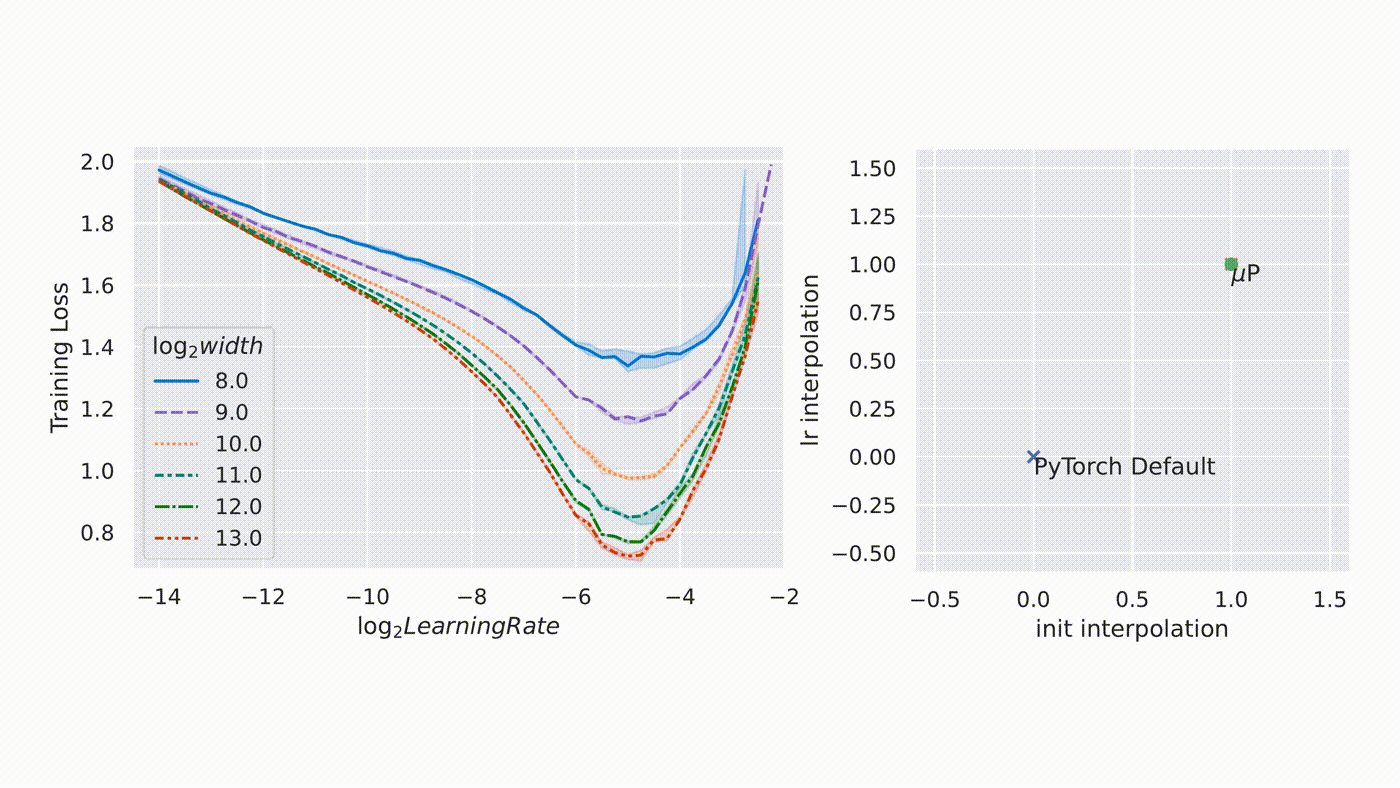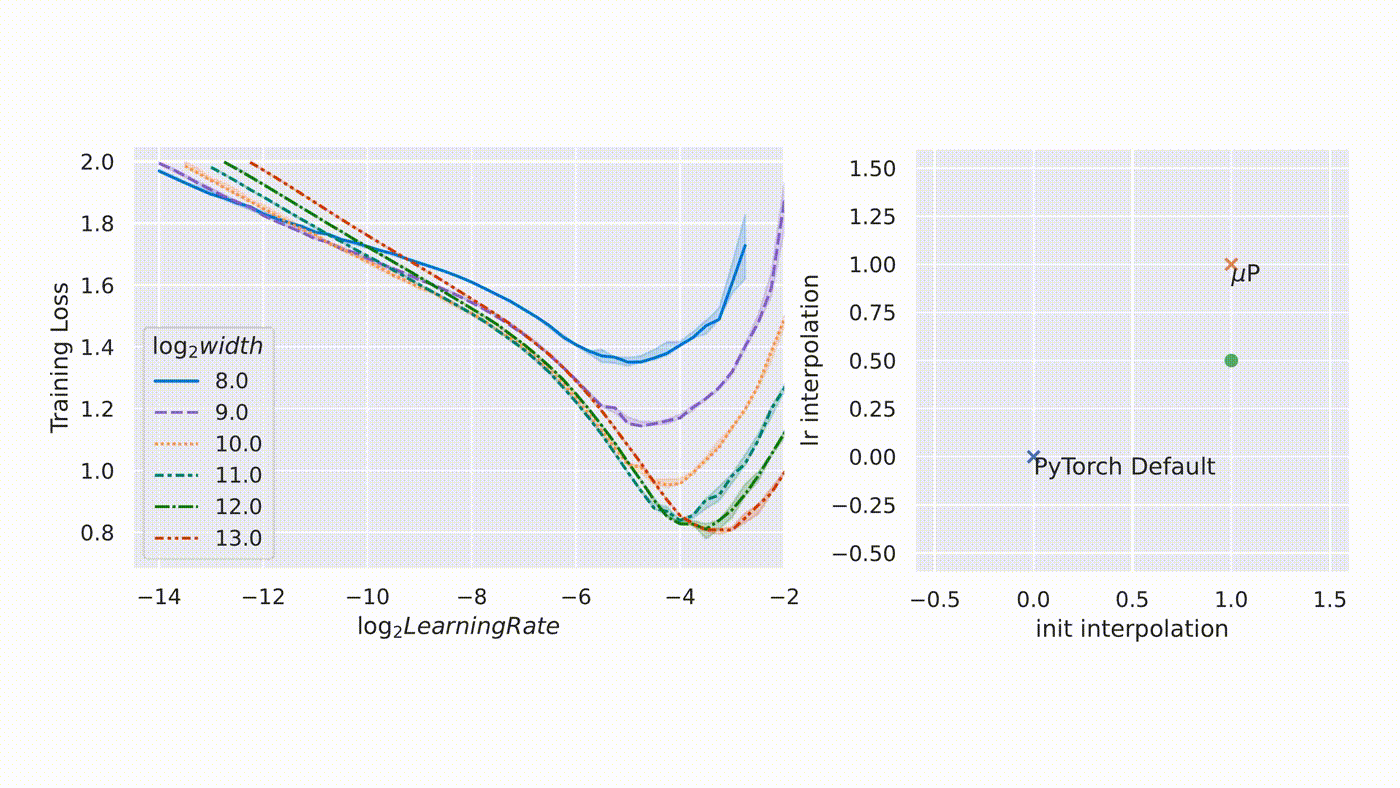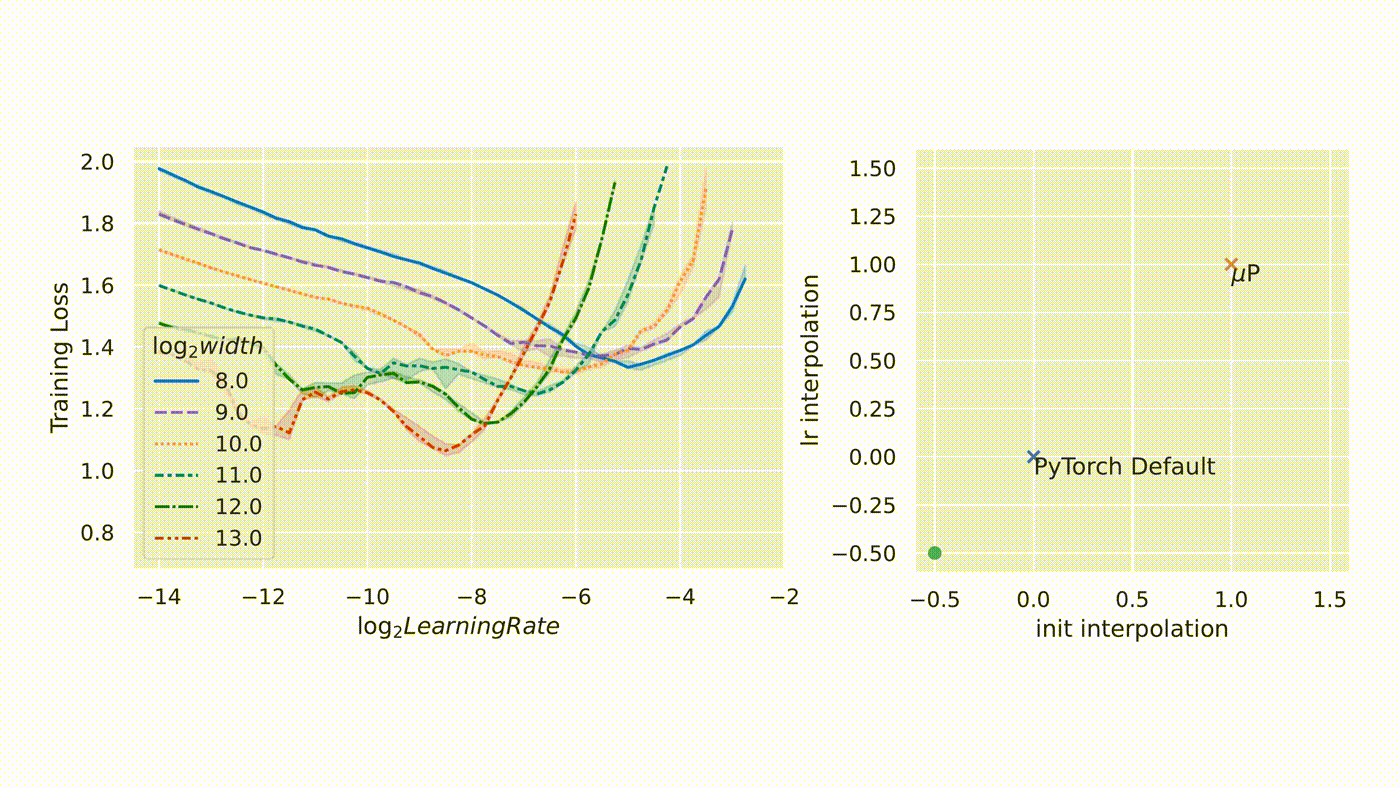
µTransfer: A technique for hyperparameter tuning of enormous neural networks is a blog post by Microsoft that talks about a new technique hyperparameter optimization that introduced in a previous paper, where we showed that it uniquely enables maximal feature learning in the infinite-width limit. In collaboration with researchers at OpenAI, they verified its practical advantage on a range of realistic scenarios, which we describe in our new paper, “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer.”
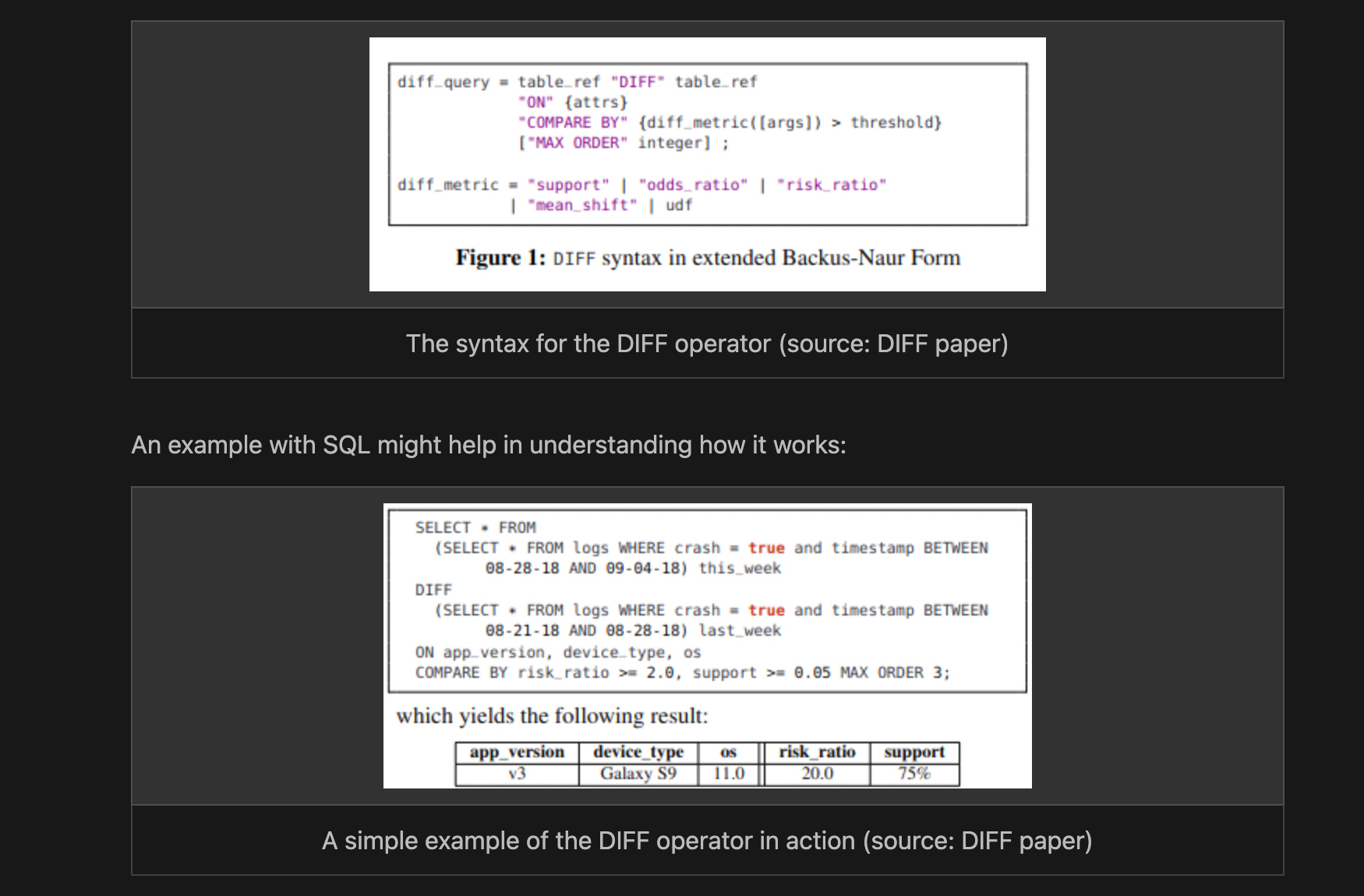
Adam Marcus explains diff tool that he built and explains some of the motivations of this tool in the following blog post. The diff paper is the main motivation.
Libraries
Jaxton provides 100 exercises in the notebook form to teach you Jax. The exercises are relatively easy, so if you do not know anything about Jax, the tutorial might be great way to get started. If you know basic or an introductory level Jax, I recommend using another tutorial to learn Jax.

Padl is a framework to build pipelines leveraging PyTorch under the hood. Using and reproducing deep learning models in practice is about much more than writing individual PyTorch layers; it also means specifying how individuals PyTorch layers intercommunicate, how inputs are prepared as tensors, which pieces of auxiliary data are necessary to prepare those inputs, and how tensor outputs are post-processed and converted to make them useful for the target application. PADL's "Pipeline" specifies all of these additional things.
Lightning Flash has a number of different recipes among different types of tasks and datasets.
Composer is a library written in PyTorch that enables you to train neural networks faster, at lower cost, and to higher accuracy. We've implemented more than two dozen speed-up methods that can be applied to your training loop in just a few lines of code, or used with our built-in Trainer. We continually integrate the latest state-of-the-art in efficient neural network training.
IR From Bag-of-words to BERT and Beyond through Practical Experiments is the official repository of "IR From Bag-of-words to BERT and Beyond through Practical Experiments", an ECIR 2021 full-day tutorial with PyTerrier and OpenNIR search toolkits.
Notebooks
Multi-Headed Attention (MHA) is a tutorial/implementation of multi-headed attention from paper Attention Is All You Need in PyTorch.
This notebook shows how to do draw artline from existing images.
Self-Attention (https://arxiv.org/abs/1805.08318). Generator is pretrained UNET with spectral normalization and self-attention through DeOldify.
Generator Loss : Perceptual Loss/Feature Loss based on VGG16. (https://arxiv.org/pdf/1603.08155.pdf)
RoPE Embeddings assumes the positional information gets embedded in embeddings and therefore not use them in causal attention. Non-causal self-attention needs explicit positional information because it cannot infer it.