

UltraScale Playbook
GenAI Libraries: R2R, RAGFlow, Guidance, Moonlight

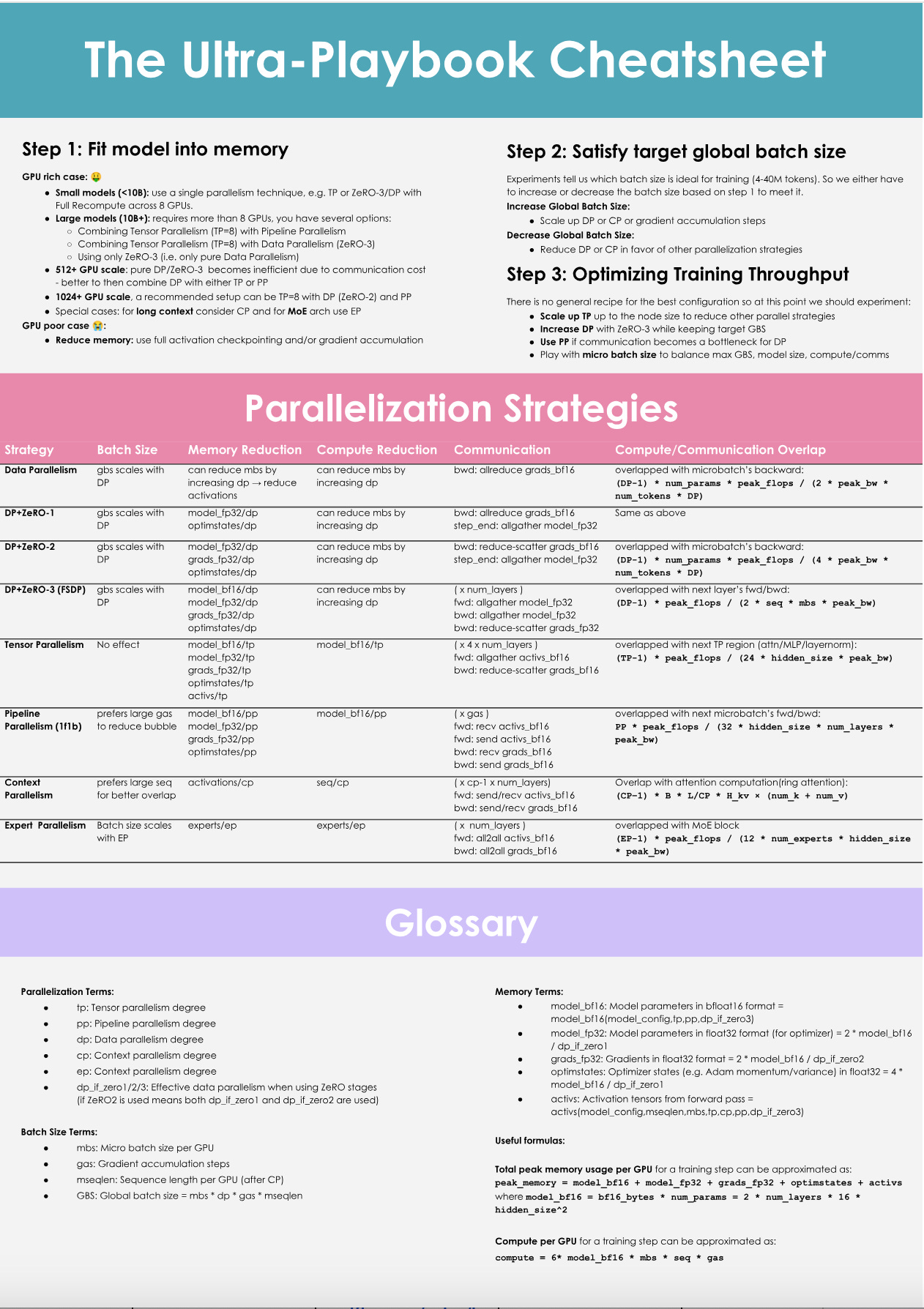
HuggingFace wrote an excellent report called Ultra-Scale Playbook, a guide detailing methodologies for training large language models (LLMs) on GPU clusters. The playbook analyzes over 4,000 scaling experiments conducted across GPU configurations ranging from 1 to 512 devices. It addresses three primary constraints in distributed training:
Memory usage (hardware limits per GPU)
Compute efficiency (percentage of time GPUs spend on arithmetic operations)
communication overhead (latency and bandwidth utilization between nodes)
The techniques discussed reduce peak memory consumption by up to 80%, improve compute utilization beyond 90%, and minimize communication idle time through overlapping strategies.
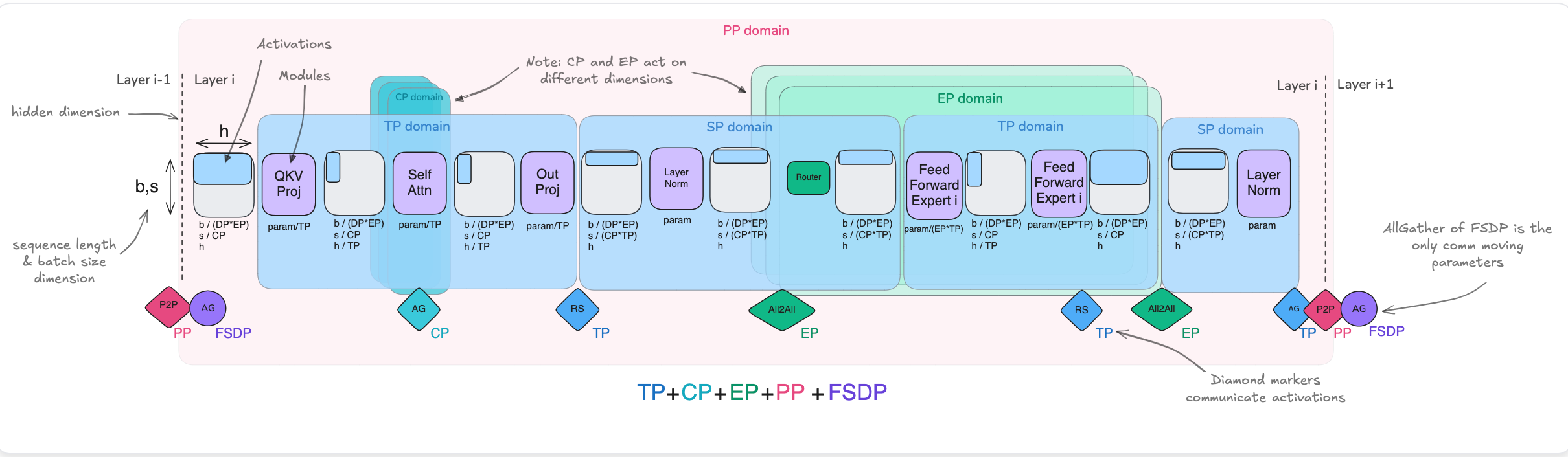
For memory optimization, here we come to various parallelism in the training through a number of different parallelism capabilities to reduce the memory needed to run the training.
Data Parallelism
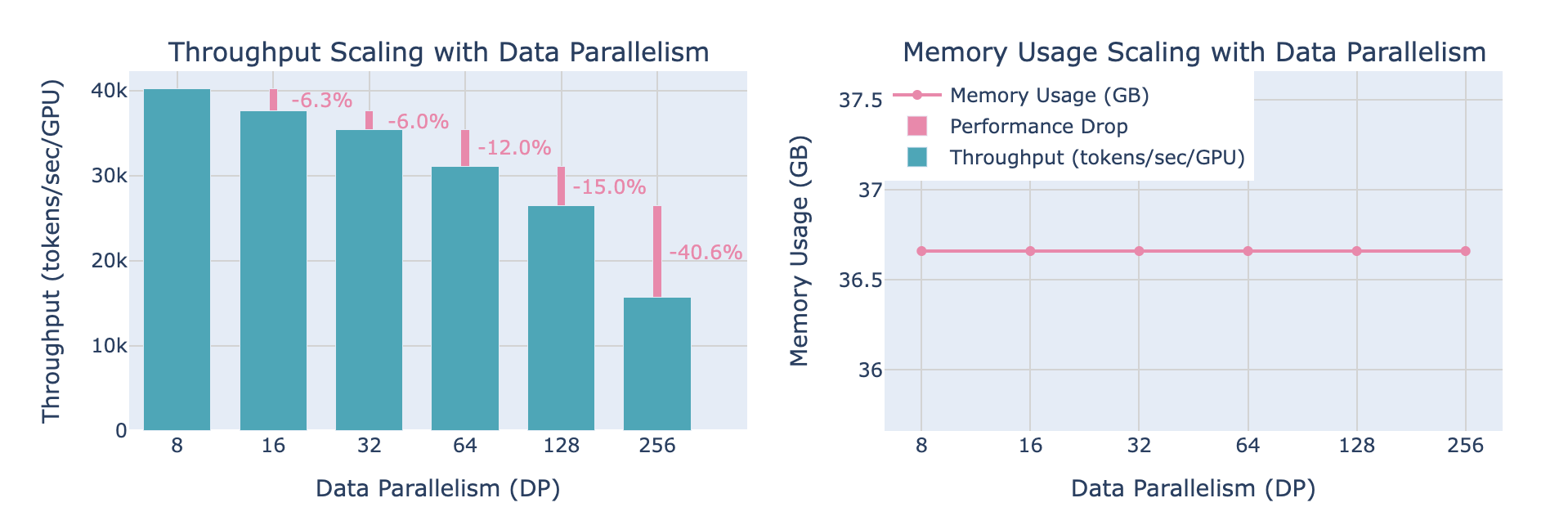
Data parallelism splits training batches across GPUs, with each device maintaining a full model copy. For a batch size B and N GPUs, each GPU processes B/N samples. Gradients are averaged via all-reduce operations after backward passes. The memory overhead scales linearly with model size M, requiring O(M) per GPU.Communication costs grow as O(M⋅logN) per iteration due to all-reduce operations. At 512 GPUs, this method alone becomes bottlenecked by inter-node bandwidth limitations (typically 100-400 GB/s for NVLink vs. 10-25 GB/s for InfiniBand).

Tensor Parallelism
Tensor parallelism partitions individual model layers across GPUs. For a transformer layer with hidden dimension dd, weight matrices W∈Rd×d are split along rows or columns. For N GPUs, each device stores Wi∈Rd/N×d, reducing per-GPU memory to O(d2/N). Forward passes require all-gather operations O(d2/N) communication per layer), while backward passes use reduce-scatter. This introduces O(2⋅L⋅d2/N) communication per layer L, making it suitable for intra-node splits where NVLink bandwidth exceeds 300 GB/s.
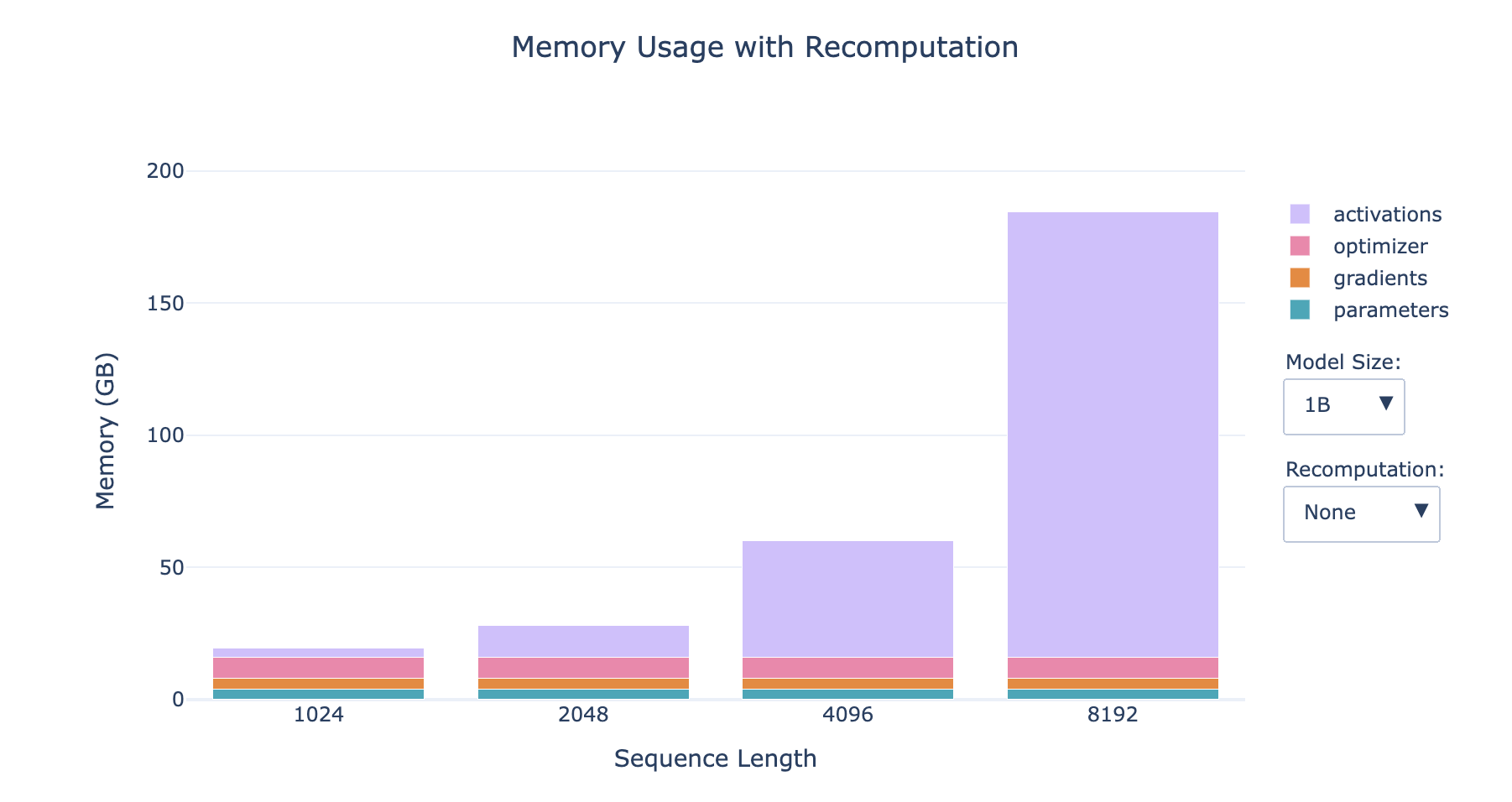
Sequence Parallelism
Sequence parallelism distributes input sequences of length S across devices. Each GPU processes S/N tokens, with attention computations requiring all-to-all communication for query-key-value matrices. Memory savings scale linearly with N, reducing activation memory from O(S⋅d) to O(S⋅d/N). For S=32,768 and d=12,288(Llama 3 configurations), this reduces activation memory from 1.5 GB to 48 MB per GPU at N=32.
Pipeline Parallelism
Pipeline parallelism partitions model layers across stages. For L layers and N GPUs, each stage contains L/N layers. Microbatches of size B are pipelined to keep all stages active. Memory is reduced by O(L/N), but requires storing activations for B microbatches, leading to O(B⋅S⋅d) per-stage memory.
There are also a number of computation centric optimizations that can help enhance the usage of the compute that is provided through the kernels. This is to improve the compute throughput against a particular GPU hardware.
Kernel Fusion
The playbook evaluates fused CUDA kernels that combine multiple operations (e.g., layer normalization + attention) into single GPU tasks. For a 175B parameter model, kernel fusion reduces kernel launch overhead from 15% to 2% of total runtime and decreases memory access latency by 40% through shared tensor caching.
Mixed Precision Training
Using FP8 (8-bit floating point) for activations and BF16 (16-bit brain float) for weights reduces memory consumption by 50% compared to FP32. Throughput increases by 1.8×, with a 12% loss in perplexity requiring gradient scaling adjustments. The playbook provides quantization thresholds: activations in FP8 cause overflow after certain number of steps, necessitating automatic scaling factors calibrated every 100 steps.
Overlapping Compute and Communication
The playbook’s experiments show that overlapping 85% of communication with compute reduces iteration time by 30% at 512 GPUs. Techniques include:
Prefetching: Loading next-batch data during backward passes (10% speedup).
Gradient Bucketing: Aggregating small gradients into 128 MB buckets before all-reduce (20% less communication time).
Non-Blocking All-Reduce: Launching communication ops before compute completes, achieving 75% overlap efficiency.
There are a number of ways to reduce the communication overhead, thereby improving the throughput of the distributed training in multiple node setup by optimizing the communication between the nodes.
Hierarchical All-Reduce
For multi-node clusters, hierarchical all-reduce performs intra-node reductions before inter-node communication. On 8-node clusters with 8 GPUs per node, this reduces inter-node traffic by 87.5%. The playbook benchmarks this approach at 512 GPUs, showing 2.1× higher throughput than flat all-reduce.

Expert Parallelism in Mixture-of-Experts (MoE)
In MoE models with E experts, each GPU hosts E/N experts. During routing, all-to-all communication exchanges tokens between experts. For a 1.6T parameter model with 128 experts across 64 GPUs, expert parallelism reduces per-GPU memory from 24 GB to 3.8 GB but incurs 22% overhead from token redistribution.
HuggingFace also reports a number of experiments around different levers across these different dimensions(memory, compute optimization, communication overhead) as not all of the levers are net positive in all of the dimensions. One lever might improve memory usage, where it might cause a lot more communication overhead and this necessities looking at some of these levers from a trade-off framework to optimize these different dimensions against the hardware that is being used.
The playbook quantifies tradeoffs across 4,000 experiments:
Tensor + Data Parallelism: At 64 GPUs, combining 8-way tensor and 8-way data parallelism yields 92% compute utilization vs. 78% for pure data parallelism. Peak memory drops from 38 GB to 12 GB per GPU.
Pipeline + Sequence Parallelism: For 1T parameter models, 16-stage pipeline and 32-way sequence parallelism achieve 47% MFU (model FLOPs utilization), compared to 29% MFU with pure pipeline.
ZeRO Stage 3: Reduces memory by 80% via partitioning optimizer states, gradients, and parameters. However, communication increases by 3.2×, limiting scalability beyond 256 GPUs.
Of course, in this large scale, it is very hard to find an optimal set of configuration that results in the best set of levers and their hyper parameters. One can do a parameter sweep across all of the possible configuration to optimize the throughput of the training or model size based on the outcome that people want to achieve.
Unsurprisingly, the playbook introduces a cost model to predict training efficiency:
MFU=Actual TFLOPs Peak TFLOPs=312⋅B⋅S⋅d2/NAGPU⋅(1−TcommTtotal) MFU=Peak TFLOPsActual TFLOPs=AGPU312⋅B⋅S⋅d2/N⋅(1−TtotalTcomm)
where
B = batch size,
S = sequence length,
d = hidden dim,
N = GPUs,
AGPU = GPU compute (e.g., 312 TFLOPS for H100),
Tcomm = communication time.

The model selects configurations within 5% of optimal MFU across tested hardware.
Flash Attention Variants
Memory-efficient attention kernels reduce peak memory from O(S2) to O(S):
FlashAttention-2: Achieves 1.5× speedup over baseline with 72% memory reduction for S=32k.
FlashDecoding: Optimizes inference by splitting keys/values across GPUs, reducing decoding latency by 2.4× at 512 GPUs.
Quantization-Aware Kernels
Custom kernels for 4-bit weight quantization (NF4) maintain 98% of FP16 accuracy while reducing memory by 4×. The playbook reports 2.1× higher throughput compared to FP16 baseline for 70B parameter models
Libraries

Guidance is an efficient programming paradigm for steering language models. With Guidance, you can control how output is structured and get high-quality output for your use case—while reducing latency and cost vs. conventional prompting or fine-tuning. It allows users to constrain generation (e.g. with regex and CFGs) as well as to interleave control (conditionals, loops, tool use) and generation seamlessly. Guidance is available through PyPI and supports a variety of backends (Transformers, llama.cpp, OpenAI, etc.). To use a specific model see loading models.
T5X is a modular, composable, research-friendly framework for high-performance, configurable, self-service training, evaluation, and inference of sequence models (starting with language) at many scales.
It is essentially a new and improved implementation of the T5 codebase (based on Mesh TensorFlow) in JAX and Flax. To learn more, see the T5X Paper.
Below is a quick start guide for training models with TPUs on Google Cloud. For additional tutorials and background, see the complete documentation.

Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. Muon consists of: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves ∼ 2× computational efficiency compared to AdamW with compute optimal training.
Based on these improvements, they introduce Moonlight, a 3B/16B-parameter Mixture-of-Expert (MoE) model trained with 5.7T tokens using Muon. The model improves the current Pareto frontier, achieving better performance with much fewer training FLOPs compared to prior models.
VILA is a family of open VLMs designed to optimize both efficiency and accuracy for efficient video understanding and multi-image understanding.

PGAI allows you to enhance and improve the Postgresql for variety of use cases with regards to ML applications:
Automatic creation and synchronization of vector embeddings for your data
Seamless vector and semantic search
Retrieval Augmented Generation (RAG) directly in SQL
Ability to call out to leading LLMs like OpenAI, Ollama, Cohere, and more via SQL.
Built-in utilities for dataset loading and processing
All with the reliability, scalability, and ACID compliance of PostgreSQL.

R2R (Reason to Retrieve) is the most advanced AI retrieval system, supporting Retrieval-Augmented Generation (RAG) with production-ready features. Built around a containerized RESTful API, R2R offers multimodal content ingestion, hybrid search functionality, knowledge graphs, and comprehensive user and document management.

GenAIScript allows you to programmatically assemble prompts for LLMs using JavaScript. Orchestrate LLMs, tools, and data in code.
JavaScript toolbox to work with prompts
Abstraction to make it easy and productive
Seamless Visual Studio Code integration
Online documentation is available at microsoft.github.io/genaiscript
RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data. The code is available at GitHub.
Flow is a a lightweight task engine for building AI agents that prioritizes simplicity and flexibility.
Unlike traditional node and edge-based workflows, Flow uses a dynamic task queue system built on three simple principles:
Concurrent Execution - Tasks run in parallel automatically
Dynamic Scheduling - Tasks can schedule new tasks at runtime
Smart Dependencies - Tasks can await results from previous operations
Results of all tasks are stored in a thread-safe Context.
This task-based architecture makes complex workflows surprisingly simple:
Parallel task execution without explicit threading code
Self-modifying dynamic workflows and cycles
Conditional branching and control flow
Streaming of tasks execution
State management, load previous state and save current state
Start execution from a specific task
Dynamically push next tasks with specific inputs
Map Reduce, running the same task in parallel on multiple inputs and collecting results
Below The Fold

Cobra is a library for creating powerful modern CLI applications.
Cobra is used in many Go projects such as Kubernetes, Hugo, and GitHub CLI to name a few. This list contains a more extensive list of projects using Cobra.
Trailbase is a blazingly fast, open-source application server with type-safe APIs, built-in JS/ES6/TS runtime, realtime, auth, and admin UI built on Rust, SQLite & V8.
Reading List
This is an excellent tutorial that shows how to write an operating system from scratch.
Co-Scientist paper from Google; it is a long technical report, but worth it especially thinking about scientific hypothesis construction and mapping this hypothesis testing, scientific method into LLM agent functions.