

Twitter open-sourced their recommendation algorithm
Twitter's algorithm explained and LLM libraries and tools

This week, we have one article only; I work in recommender systems domain and Twitter open sourced their training, serving layer of recommendation algorithm and published a blog post.
Of course, what is expected has happened, and I went deep dive on the code and the post itself in this issue.
Both repositories and post does not have all details, though. For example, candidate generators and training data are not released which I assume due to privacy and other types of concerns. However, explanation on candidate generation, ranking(light and heavy) and later stages especially on serving layer are clearly articulated and you can follow the code well in serving layer(you need to know a bit of Scala, though).
This issue is going to be very recommender systems focused due to that, we will go back to the original programming from next week.
Bugra
Twitter’s Recommender System Algorithm

Context
Twitter open-sourced their algorithm, both in the training and model layer and also in the serving layer.
Model/Training repository: https://github.com/twitter/the-algorithm-ml
Serving repository: https://github.com/twitter/the-algorithm
Candidate Generation
They have mainly 2 main candidate generators that combine “in-network” which stands for all of the people that you follow through the social graph that has all of the Tweets from people that you follow, the other candidate generator “out-network” where all of the other tweets that are not tweeted through people that you do not follow. After mixing the in-network and out-network, they try to strike balance of 50%-50% on average even though the percentage might change person to person.
In the “in-network” resource, one thing that strike me pretty interesting is that they compute a score between two different users.
The most important component in ranking In-Network Tweets is Real Graph. Real Graph is a model which predicts the likelihood of engagement between two users. The higher the Real Graph score between you and the author of the Tweet, the more of their tweets we'll include.
By doing so, instead of computing the user to tweet relation, they actually go after first user to user problem and then compute a relevancy score for an anchor user to all of the following users. Through that, they use this score for clusters of tweets to be able to rank/fetch various tweets from other users in a more balanced way.
For out-of network, they also go through social graph that they have to find out similar match interests.
We traverse the graph of engagements and follows to answer the following questions:
What Tweets did the people I follow recently engage with?
Who likes similar Tweets to me, and what else have they recently liked?
Even in out-network recommendations, they start with user to user relationship where they want to understand for a given user, which user might be more similar. From this perspective, I am actually pleasantly surprised how crucial “similarity score” of users for both in-network and out-of-network. This also enables them to seed the user interests well for out-of-network resources probably. On the downside, this might limit serendipity and diversity of the tweets even in out-of-network.
For users that are similar to each other, they use SimClusters to cluster users into clusters where they share a lot of similarity of activities to each other. In here the approach is pure collaborative filtering where they have user to user matrix based on user engagements(I would assume it would be positive engagements) and then they use a matrix factorization to recommend user to user. They use Sparse Binary Factorization.
Ranking
They have earlybird for light ranking, but this is a logistic regression model that is being replaced(the last training has happened many moons ago), so I will not cover this in detail. If you want to check out the weights, they are in here.
After the light ranking, they have a heavy ranking model that are 48M parameter neural network model(relatively small comparing to the size of their dataset IMHO). The model architecture is a parallel MaskNet which outputs a set of numbers between 0 and 1, with each output representing the probability that the user will engage with the tweet in a particular way.

The paper from Weibo goes into more detail for the ranking model architecture.
The probabilities that they predict:
recap.engagement.is_favorited: The probability the user will favorite the Tweet. recap.engagement.is_good_clicked_convo_desc_favorited_or_replied: The probability the user will click into the conversation of this Tweet and reply or Like a Tweet.
recap.engagement.is_good_clicked_convo_desc_v2: The probability the user will click into the conversation of this Tweet and stay there for at least 2 minutes.
recap.engagement.is_negative_feedback_v2: The probability the user will react negatively (requesting "show less often" on the Tweet or author, block or mute the Tweet author)
recap.engagement.is_profile_clicked_and_profile_engaged: The probability the user opens the Tweet author profile and Likes or replies to a Tweet.
recap.engagement.is_replied: The probability the user replies to the Tweet.
recap.engagement.is_replied_reply_engaged_by_author: The probability the user replies to the Tweet and this reply is engaged by the Tweet author.
recap.engagement.is_report_tweet_clicked: The probability the user will click Report Tweet.
recap.engagement.is_retweeted: The probability the user will ReTweet the Tweet.
recap.engagement.is_video_playback_50: The probability (for a video Tweet) that the user will watch at least half of the video
Most of the actions are actually engagement labels that anyone can guess well if they are using Twitter actively, their click label requires not only user to click, but stay there 2 minutes which I found very long. I would like to learn their time of stay on a tweet for an authentic user(assuming that this number is put in place to eliminate bot activity).
I found that they do not predict bookmark relatively surprising, it is an action I generally tend to use a lot more than favorite/retweet.
They have a lot of matching related features on the tweet activity; is_replied and is_replied_and_reply_engaged also makes sense and I would imagine, they might be using a similar approach to rank tweets for power users on the tweets as they might be receiving more than thousands of replies. This also balances relatively well if the power user is interacting with responses. Also, this type of matching labels creates an ELO like mechanism where power users can distribute some of their ELO score to users that do not have the same reach/distribution to other people given that they will be getting more attention through the power users through their similarity score/user clusters.
The main ranking model does not consider tweets if they are coming from in-network or out-network resources which still optimizes for “relevance” through the tasks that the model is trying to predict. Further, they have more control of composition of tweets in the mixing stage as well. Due to that, they consider all of the tweets at a similar mechanism and rank.
Outputs and their “value model” to combine these various tasks into a single score to produce the final final ranking:
recap.engagement.is_favorited: 0.5 recap.engagement.is_good_clicked_convo_desc_favorited_or_replied: 11* (the maximum prediction from these two "good click" features is used and weighted by 11, the other prediction is ignored).
recap.engagement.is_good_clicked_convo_desc_v2: 11* recap.engagement.is_negative_feedback_v2: -74 recap.engagement.is_profile_clicked_and_profile_engaged: 12 recap.engagement.is_replied: 27 recap.engagement.is_replied_reply_engaged_by_author: 75 recap.engagement.is_report_tweet_clicked: -369
recap.engagement.is_retweeted: 1
recap.engagement.is_video_playback_50: 0.005
The value model is more art than science, but again pleasantly surprised that they consider negative responses much more heavily than positive engagements.
Filtering/Business Logics
They have further filtering/business logic rules after the ranking and value model stage:
Visibility Filtering: Filter out Tweets based on their content and your preferences. For instance, remove Tweets from accounts you block or mute.
Author Diversity: Avoid too many consecutive Tweets from a single author.
Content Balance: Ensure we are delivering a fair balance of In-Network and Out-of-Network Tweets.
Feedback-based Fatigue: Lower the score of certain Tweets if the viewer has provided negative feedback around it.
Social Proof: Exclude Out-of-Network Tweets without a second degree connection to the Tweet as a quality safeguard. In other words, ensure someone you follow engaged with the Tweet or follows the Tweet’s author.
Conversations: Provide more context to a Reply by threading it together with the original Tweet.
Edited Tweets: Determine if the Tweets currently on a device are stale, and send instructions to replace them with the edited versions.
The filters/scorers can be found in here and here. You will see that they still have a very much in-network focus in various scorers.
Final Commentary
Without knowing anything, I always thought that Twitter would have more understanding of user to tweets, but as you will see in the above stages, their recommendation is very user centric.
They consider users to be an excellent pooling of their tweets and through that first, they interpret the problem as user to user problem in candidate generation stages. One can consider even the graph based approach as two-hop based approach to understand the similarities of users and using to recommend various tweets afterwards.
I also found out that they do not have Graph Neural Networks(GNN) or mentioning them in both code and post. They have a lot of papers in this area and I always thought that they are using GNNs in production. Their ranking model is a multi-task multi-tower neural network and their data is graph based.
Some of their recent work on GNNs can be found in here, here and here.
Instead of solving user to tweet recommendation problem in candidate generation, first they go after solving recommending user to user problem and then afterwards, they rank the tweets per the short-term labels(retweets, likes, replied, replied_and_engaged) and then bringing everything together in a single ranking stage.
The blog post goes much more in detail on how the overall system works.
Libraries
ChatGDB is a tool designed to superpower your debugging experience with GDB, a debugger for compiled languages. Use it to accelerate your debugging workflow by leveraging the power of ChatGPT to assist you while using GDB!
It allows you to explain in natural language what you want to do, and then automatically execute the relevant command. Optionally, you can ask ChatGPT to explain the command it just ran or even pass in any question for it to answer. Focus on what's important - figuring out that nasty bug instead of chasing down GDB commands at the tip of your tongue.
Today's models are notoriously bad at understanding their own risks -- they are biased on underrepresented data, brittle on challenging out-of-distribution scenarios, and can fail without warning when insufficiently trained. Ensuring awareness of not one, but all of these risks, requires a tedious process involving changes to your model, its architecture, loss function, optimization procedure, and more. Capsa automatically wraps your model (i.e., like a capsule!) and makes all of the internal changes so it can be end-to-end risk-aware. Capsa abstracts away all of those changes so you don't have to modify any of your existing training or deployment pipelines in order to build state-of-the-art trustworthy machine learning solutions.
POT: Python Optimal Transport provides several solvers for optimization problems related to Optimal Transport for signal, image processing and machine learning.
LLM Section
This week, this section under Libraries will go over more details on the various libraries for LLM and embedding databases:

LMQL generalizes natural language prompting, making it more expressive while remaining accessible. For this, LMQL builds on top of Python, allowing users to express natural language prompts that also contain code. The resulting queries can be directly executed on language models like OpenAI's GPT models. Fixed answer templates and intermediate instructions allow the user to steer the LLM's reasoning process.

In LMQL, users can specify high-level, logical constraints over the language model output. These constraints are then automatically converted into token-level prediction masks, which can be enforced eagearly during text generation. This allows to enforce many constraints strictly, making it impossible for the model to generate content that does not satisfy the requirements. This simplifies multi-part prompting and integration, as it provides better guarantees about the output format.
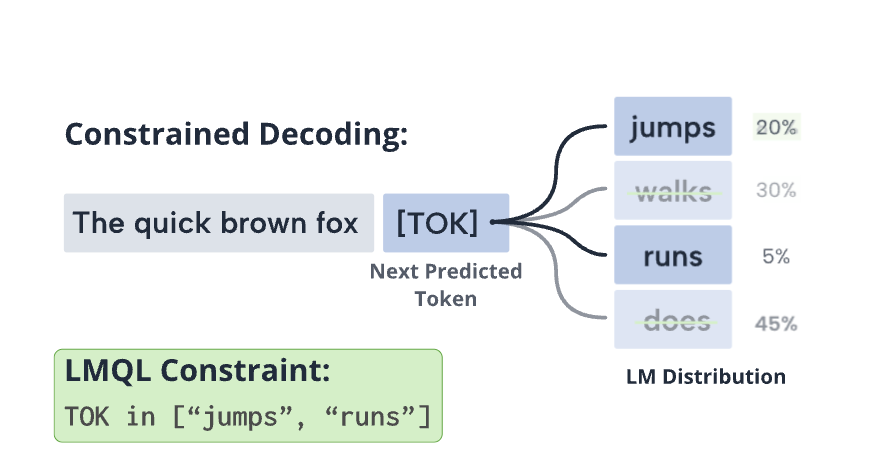
The paper goes into more details.
Chroma - is an open-source embedding database library that supports both Python and Javascript. Its API is very similar to MongoDB and very easy to use.
LangChain is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model via an API, but will also:
Be data-aware: connect a language model to other sources of data
Be agentic: allow a language model to interact with its environment
DocArray is a library for nested, unstructured, multimodal data in transit, including text, image, audio, video, 3D mesh, etc. It allows deep-learning engineers to efficiently process, embed, search, recommend, store, and transfer multimodal data with a Pythonic API.
🚪 Door to multimodal world: super-expressive data structure for representing complicated/mixed/nested text, image, video, audio, 3D mesh data. The foundation data structure of Jina, CLIP-as-service, DALL·E Flow, DiscoArt etc.
🧑🔬 Data science powerhouse: greatly accelerate data scientists’ work on embedding, k-NN matching, querying, visualizing, evaluating via Torch/TensorFlow/ONNX/PaddlePaddle on CPU/GPU.
🚡 Data in transit: optimized for network communication, ready-to-wire at anytime with fast and compressed serialization in Protobuf, bytes, base64, JSON, CSV, DataFrame. Perfect for streaming and out-of-memory data.
🔎 One-stop k-NN: Unified and consistent API for mainstream vector databases that allows nearest neighbor search including Elasticsearch, Redis, AnnLite, Qdrant, Weaviate.
👒 For modern apps: GraphQL support makes your server versatile on request and response; built-in data validation and JSON Schema (OpenAPI) help you build reliable web services.
🐍 Pythonic experience: as easy as a Python list. If you can Python, you can DocArray. Intuitive idioms and type annotation simplify the code you write.
🛸 IDE integration: pretty-print and visualization on Jupyter notebook and Google Colab; comprehensive autocomplete and type hints in PyCharm and VS Code.