TPU Deep Dive
Tokasaurus and LLM Inference Library Comparisons


Stanford Scaling Intelligence group wrote a blog post on Tokasaurus, a new LLM inference engine optimized for throughput-intensive workloads.
It can do batch processing tasks such as codebase scanning, synthetic data generation, and reinforcement learning pipelines. The main motivation comes from that unlike traditional chatbot applications where individual response latency is important, modern AI workflows often require processing thousands of sequences efficiently, making throughput optimization the primary concern where Tokasaurus is aiming to achieve fill this need.
Comparing to vLLM and SGLang across various throughput-focused benchmarks, researchers claim that Tokasaurus shows 3x throughput. This performance gain stems from optimizations tailored for both small and large models, addressing different bottlenecks that emerge at various scales. The project's influence extends beyond raw performance metrics, as it demonstrates how specialized design choices can dramatically improve efficiency for specific use cases which is one of the main theme in the blog post.

Tokasaurus adopts significantly different approach to LLM inference by prioritizing throughput over latency, leading to architectural decisions that is different from general-purpose inference engines. Further, it is implemented in pure Python, leveraging PyTorch's compilation capabilities and the FlashInfer library for attention operations. This design choice prioritizes flexibility and extensibility, following the philosophy of projects like GPT-fast.
The engine's architecture centers around an adaptive CPU manager that maintains deep input queues for GPU computation. This manager operates asynchronously and adaptively, monitoring queue depths and automatically adjusting its behavior to prevent GPU starvation. When the input queue approaches depletion, the manager dynamically skips optional operations like stop string checking and new sequence onboarding until sufficient queue depth is restored.
The system supports flexible parallelization strategies within single nodes, accommodating any combination of data, tensor, and pipeline parallelism. Currently, Tokasaurus supports models from the Llama-3 and Qwen-2 families, with plans for broader model support.
Small Model Optimizations
For small models, CPU overhead becomes a critical bottleneck that can significantly impact overall throughput. Traditional inference engines attempt to mitigate this through asynchronous processing, where CPU tasks for batch N+1 are prepared while the GPU processes batch N. Tokasaurus extends this concept with an adaptive management system that goes beyond simple asynchrony.
The adaptive manager continuously monitors the depth of the input queue and implements dynamic prioritization of tasks. When the system detects potential GPU starvation, it automatically reduces CPU overhead by temporarily suspending non-critical operations. This approach ensures that GPU utilization remains high even under varying workload conditions, a crucial factor for maximizing throughput in small model deployments.
The effectiveness of this optimization is demonstrated through benchmarks using the ShareGPT dataset, where Tokasaurus consistently outperforms competing engines. The adaptive nature of the system allows it to maintain high performance across different request patterns and batch sizes, making it particularly suitable for variable workloads.
Dynamic Prefix Identification and Hydragen Integration
One of Tokasaurus's features is its dynamic implementation of Hydragen (also known as cascade attention or bifurcated attention), which optimizes attention computation for sequences with shared prefixes. Prefix sharing occurs frequently in practical LLM applications, including repeated sampling for mathematical problems, document-based question answering, and system prompt reuse across different conversations.
The challenge in implementing Hydragen in a production inference engine lies in detecting shared prefixes dynamically as sequences continuously start and finish. Tokasaurus solves this through a greedy depth-first search algorithm executed before each model forward pass. This algorithm iteratively identifies the longest possible shared prefixes among active sequences, maximizing the efficiency gains from shared computation.
The impact of this optimization is particularly pronounced for small models, which dedicate a relatively larger fraction of their computational budget to attention mechanisms compared to larger models. In benchmarks reproducing the Large Language Monkeys experiment—where 128 GSM8K problems each receive 1024 answer attempts—Tokasaurus achieves over 2x throughput improvement compared to other engines. This dramatic improvement demonstrates the practical value of dynamic prefix detection in real-world scenarios with high degrees of sequence overlap.
Large Model Optimizations
Tokasaurus was originally motivated by the need to efficiently run large model inference on L40S GPUs, which lack high-bandwidth NVLink connections between GPUs. Without NVLink, the communication costs of tensor parallelism across multiple GPUs become prohibitive, making pipeline parallelism a more attractive option. Pipeline parallelism requires much less inter-GPU communication by partitioning the model across different stages rather than distributing each layer.
The engine's pipeline parallelism implementation excels in throughput-focused scenarios because it naturally requires large batch sizes to achieve efficiency. Batches from the manager are subdivided into microbatches distributed across pipeline stages, and since throughput optimization typically involves using the largest batch size that fits in memory, this aligns perfectly with pipeline parallelism requirements.
Benchmarking results using Llama-3.1-70B on eight L40S GPUs demonstrate the effectiveness of this approach, with Tokasaurus achieving over 3x throughput improvement compared to vLLM and SGLang's pipeline parallel implementations. This significant performance gain makes high-end inference accessible to organizations with more modest GPU infrastructure, democratizing access to large model capabilities.
Asynchronous Tensor Parallelism for High-End Hardware
For users with access to NVLink-enabled GPUs such as B200s, H100s, and A100s, Tokasaurus offers a different optimization strategy through Asynchronous Tensor Parallelism (Async-TP). This feature leverages PyTorch's relatively new capability to overlap inter-GPU communication with other computations, effectively hiding communication costs.
The implementation maintains both torch-compiled versions of models with and without Async-TP enabled, allowing the system to automatically switch between configurations based on batch size. Through benchmarking, the team discovered that Async-TP introduces significant CPU overhead and only provides benefits at very large batch sizes (6,000+ tokens).The automatic switching mechanism ensures optimal performance across the full range of operational conditions.
This dual-optimization approach demonstrates Tokasaurus's adaptability to different hardware configurations, maximizing performance whether users have access to premium interconnects or more standard GPU setups. The torch compilation integration also enables end-to-end optimization, further improving performance through advanced compiler optimizations.
FlashInfer Integration and Attention Optimization
Tokasaurus leverages the FlashInfer library for attention and sampling operations, providing state-of-the-art kernel performance across diverse inference scenarios. FlashInfer implements efficient attention kernels for both sparse and dense KV-cache storage formats, supporting single-request and batch operations across prefill, decode, and append stages.
The integration with FlashInfer enables Tokasaurus to achieve significant performance improvements in attention computation, which often represents a substantial portion of inference time. FlashInfer's block-sparse format for KV cache management optimizes memory access patterns and reduces redundancy. The library's customizable attention templates and Just-In-Time compilation capabilities allow adaptation to various attention variants and hardware configurations.
FlashInfer's load-balanced scheduling algorithm adjusts to the dynamic nature of user requests while maintaining compatibility with CUDA Graph requirements for static configuration. Comprehensive evaluations demonstrate FlashInfer's ability to achieve 29-69% inter-token latency reduction compared to compiler backends, 28-30% latency reduction for long-context inference, and 13-17% speedup for parallel generation scenarios.
Benchmarking Methodology and Results
The Tokasaurus team implemented benchmarking protocols to ensure fair comparisons with existing engines.All engines were configured with identical KV cache sizes and maximum running request limits, with careful tuning of remaining parameters for each system. The benchmarks report average throughput across multiple runs after completing warmup phases, and all experiments were conducted on identical hardware configurations.
Two primary workload types were used for evaluation: ShareGPT dataset completion (a standard benchmark for inference engines) and reproduction of the Large Language Monkeys experiment using GSM8K mathematical problems. The latter workload particularly highlights the benefits of prefix sharing optimization, as it involves sampling 1024 answers for each of 128 problems.
All experiments utilized the OpenAI API interface to standardize interactions across different engines, though additional testing with vLLM's Python API showed modest additional improvements. The team made benchmarking scripts and commands publicly available, enabling reproducibility and independent verification of results.
The benchmark results demonstrate Tokasaurus's superior performance across multiple scenarios. For small models using the ShareGPT dataset, Tokasaurus consistently outperformed both vLLM and SGLang. The most significant improvements appeared in the Large Language Monkeys benchmark, where the prefix sharing optimization enabled over 2x throughput gains.
For large model evaluation using Llama-3.1-70B on eight L40S GPUs, Tokasaurus's pipeline parallelism implementation achieved over 3x throughput improvement compared to existing solutions. These results demonstrate the engine's effectiveness across different model sizes and hardware configurations.
The benchmarking also revealed interesting insights about the relationship between batch size and optimization effectiveness. Async-TP only becomes beneficial at very large batch sizes, while the adaptive CPU management provides consistent benefits across varying load conditions. These findings inform optimal deployment strategies for different use cases.
Competitive Landscape
The LLM inference engine landscape includes several very good libraries, each with different strengths and optimization focuses. vLLM pioneered continuous batching and PagedAttention for memory-efficient serving, achieving dramatic improvements over naive implementations. SGLang focuses on structured generation and efficient request scheduling, often achieving superior throughput in specific scenarios.
Tokasaurus differentiates itself through its specialized focus on throughput-intensive workloads and dynamic optimization capabilities. While vLLM excels in general-purpose serving and SGLang provides strong structured generation support, Tokasaurus's adaptive management and dynamic prefix detection offer unique advantages for batch processing scenarios.
The comparison reveals that no single engine dominates all scenarios, with performance varying based on model size, hardware configuration, and workload characteristics. Tokasaurus' contribution lies in pushing the boundaries of throughput optimization for specific use cases where batch processing efficiency is very important.

Henry H.M. Ko provides a comprehensive, exploration of TPUs, focusing on their architectural philosophy, hardware-software co-design, and scalability from single-chip to multi-host deployments in his TPU Deep Dive blog post. It compares different aspects of TPU with GPUs.
Early Considerations: Google began exploring specialized hardware for machine learning in 2006, initially weighing GPUs, FPGAs, and custom ASICs. Early workloads didn’t justify the investment, so CPUs sufficed.
Turning Point: By 2013, neural networks powered features like voice search, and internal projections showed that scaling with CPUs alone would be infeasible. This spurred the development of a custom ASIC: the TPU.
Current Role: Today, TPUs underpin Google’s AI services, powering both training and inference for models like Gemini and Veo, as well as high-throughput recommendation models (DLRMs).
The post specifically focuses on the TPUv4 architecture, which is representative of the latest generations (e.g., TPUv6p "Trillium", TPUv7 "Ironwood"). Each TPUv4 chip contains:
Two TensorCores: Responsible for all computation (inference-specialized chips have one).
Shared Memory Units:
CMEM (128 MiB): General on-chip memory.
HBM (32 GiB): High Bandwidth Memory for large data storage.
Each TensorCore comprises several specialized units:
Matrix Multiply Unit (MXU):
128x128 Systolic Array: The heart of the TPU’s compute capability, optimized for dense matrix multiplications.
Vector Processing Unit (VPU):
Handles elementwise operations (e.g., ReLU, add, multiply, reductions).
Vector Memory (VMEM, 32 MiB):
Acts as a buffer for data fetched from HBM, staging it for computation.
Scalar Unit and Scalar Memory (SMEM, 10 MiB):
Manages control flow, scalar ops, and memory address generation.
Instruction and Control Logic:
Directs the operation of the VPU and MXU.
How does it compare with GPUs?
Memory: TPUs have much larger on-chip memory (CMEM, VMEM, SMEM) but smaller HBM compared to GPUs (e.g., NVIDIA H100: 256 KB L1, 50 MB L2, 80 GB HBM).
Compute Cores: TPUs have fewer, but much more specialized compute cores comparing to GPUs.
Throughput: TPU v5p achieves 500 TFLOPs/sec per chip; a full pod (8960 chips) reaches ~4.45 ExaFLOPs/sec. TPUv7 "Ironwood" claims up to 42.5 ExaFLOPS/sec per pod (9216 chips).


Systolic Array:
A grid of interconnected processing elements (PEs), each performing simple operations (e.g., multiply-accumulate) and passing results to neighbors.
Advantages: Once data enters the array, no further control logic is needed. There are minimal memory reads/writes except for input and output, maximizing efficiency.
Ideal Use Cases: Matrix multiplications and convolutions, which dominate deep learning workloads, map perfectly onto systolic arrays.
Downsides
Sparsity Handling: Systolic arrays excel with dense matrices but don’t benefit from sparsity—PEs still process zeros, leading to wasted cycles for sparse workloads. This is a big downside and limitation as models like Mixture-of-Experts (MoE) become more common and ubiquitous especially in GenAI workflows.

Memory Hierarchy Comparison with GPUs
GPUs: Rely on caches to handle unpredictable memory access patterns, enhancing flexibility but increasing energy consumption.
TPUs:
Predictable Access Patterns: Most ML workloads have regular, predictable access patterns.
Scratchpad Memory: By using ahead-of-time compilation (via the XLA compiler), TPUs can precompute memory accesses and use scratchpad buffers instead of caches.
Energy Efficiency: Arithmetic operations are much cheaper than memory accesses. By minimizing memory operations, TPUs achieve both speed and substantial energy savings.
XLA Compiler
Role: The XLA compiler analyzes computation graphs ahead of time, generating highly optimized binaries that minimize memory traffic and maximize data reuse.
JAX Integration: JAX uses XLA under the hood. When a function is jitted, JAX traces it to a static computation graph, which XLA compiles for the TPU. However, different input shapes require recompilation, making JAX less suitable for dynamic workloads.
Flexibility: The heavy reliance on AoT compilation sacrifices flexibility—dynamic models or variable-length loops are less efficient.
Compiler Dependency: The system’s performance hinges on compiler quality and static analysis.
Memory vs. Compute: On modern chips, memory operations consume orders of magnitude more energy than arithmetic. HBM3 (used in TPUs) is more efficient than older DDR3/4 DRAM, but memory remains the dominant energy cost.
Scaling Laws: Increasing FLOPs (compute) is preferable to increasing memory operations, as it improves both speed and energy efficiency.

Multi-Chip and System-Level Architecture
Tray (Board) Level
Composition: A tray contains 4 TPU chips (8 TensorCores), each with its own CPU host (for inference, one host per two trays).
Interconnects:
Host to Chip: PCIe.
Chip to Chip: Inter-Core Interconnect (ICI), offering higher bandwidth than PCIe.
Rack Level
Structure: 64 TPUs per rack, connected in a 4x4x4 3D torus topology.
Interconnects: ICI and Optical Circuit Switching (OCS).
Scalability: The modular design allows racks to be combined into larger systems.
Terminology
TPU Rack: Physical unit with 64 chips ("cube").
TPU Pod: Maximum number of TPUs connected via ICI and OCS (e.g., 4096 chips for TPUv4).
TPU Slice: Any subset of TPUs within a pod, not necessarily contiguous.
Topology and Communication
3D Torus and OCS
3D Torus: Each chip connects to neighbors in three dimensions, reducing hops and latency.
OCS (Optical Circuit Switching): Used for wraparound connections, turning each axis into a ring (1D torus). This reduces worst-case communication hops from N−1N−1 to (N−1)/2(N−1)/2 per axis, crucial for scaling.
Benefits of OCS
Wraparound: Faster communication and reduced latency.
Noncontiguous Slices: OCS allows logical grouping of non-adjacent chips, enabling flexible resource allocation and higher utilization.
Scalability: Fewer physical wires and more flexible configurations support larger pod sizes.
Topology Choices
Cube (e.g., 8x8x8): Maximizes bisection bandwidth, ideal for all-to-all communication (data/tensor parallelism).
Cigar (e.g., 4x4x32): Favors pipeline parallelism, reducing sequential layer communication time.
Rectangle (e.g., 4x8x16): Intermediate trade-offs.
Superpod
Definition: The largest configuration of interconnected chips via ICI and OCS (e.g., 4096 chips for TPUv4, 9216 for TPUv7).
Physical Layout: Multiple racks interconnected, forming a massive, unified compute resource.
Slices and Flexibility
Dynamic Slicing: Thanks to OCS, slices can be noncontiguous, allowing for flexible job scheduling and resource allocation.
Performance Impact: The chosen slice topology directly affects communication bandwidth and parallelism efficiency.
Beyond the Pod
Multi-Pod: Connecting multiple pods requires slower interconnects, but enables even larger clusters for the most demanding workloads.
TPU Limitations
While TPUs are great for a variety of different use cases, it still has a number of limitations that are in following:
Sparsity: Systolic arrays are inefficient for sparse workloads, a growing concern as models evolve.
Flexibility: AoT compilation and static memory layouts hinder dynamic model architectures.
Compiler Reliance: Performance and efficiency depend heavily on the XLA compiler’s ability to optimize computation graphs.
Topology Tuning: Selecting the optimal slice topology is non-trivial and model-dependent.
Libraries
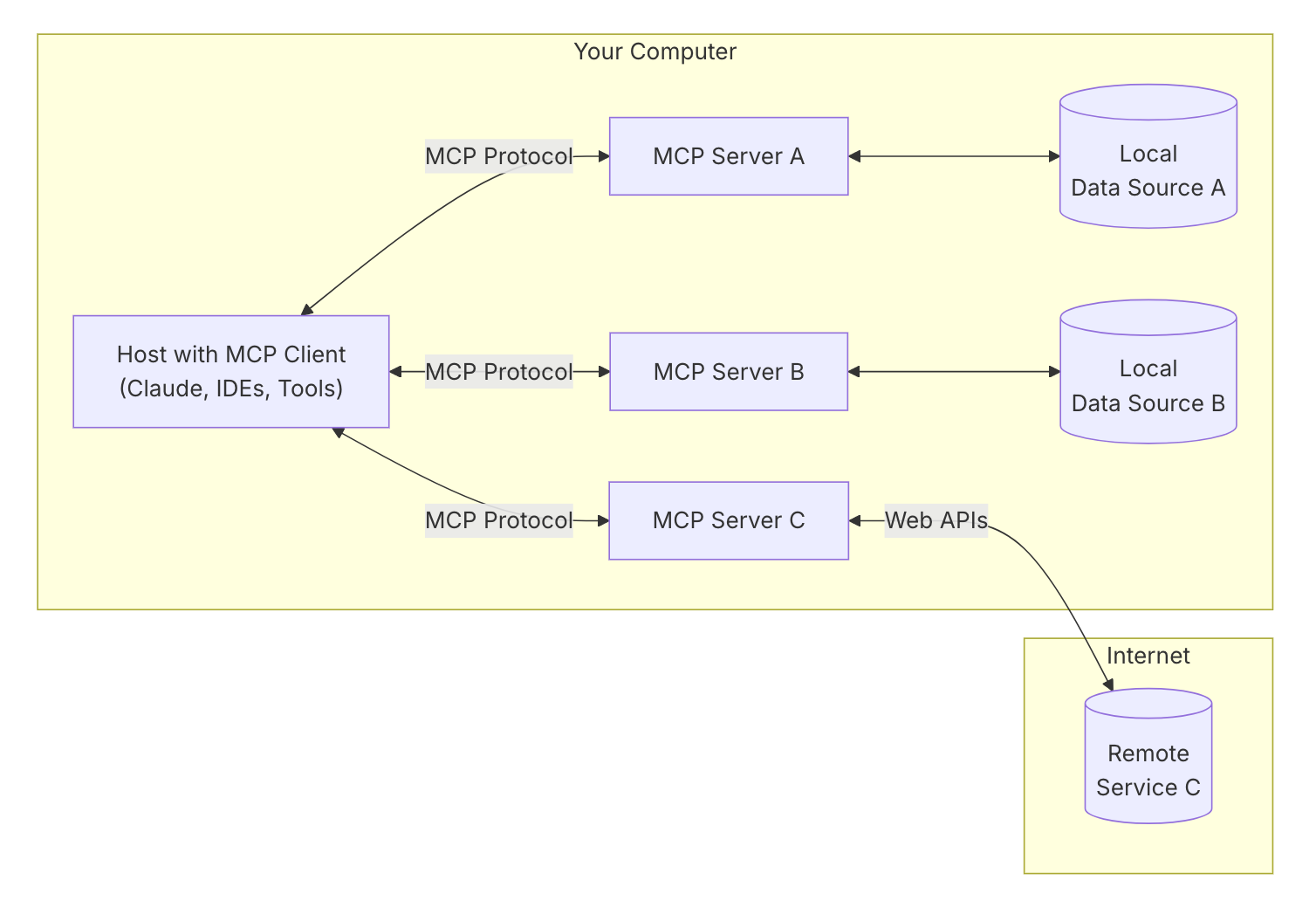
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
MCP helps you build agents and complex workflows on top of LLMs. LLMs frequently need to integrate with data and tools, and MCP provides:
A growing list of pre-built integrations that your LLM can directly plug into
The flexibility to switch between LLM providers and vendors
Best practices for securing your data within your infrastructure

Meta Lingua is a minimal and fast LLM training and inference library designed for research. Meta Lingua uses easy-to-modify PyTorch components in order to try new architectures, losses, data, etc. We aim for this code to enable end to end training, inference and evaluation as well as provide tools to better understand speed and stability.

Protenix — a trainable, open-source PyTorch reproduction of AlphaFold 3.
Protenix is built for high-accuracy structure prediction. It serves as an initial step in our journey toward advancing accessible and extensible research tools for the computational biology community.

dattri is a PyTorch library for developing, benchmarking, and deploying efficient data attribution algorithms. You may use dattri to
Deploy existing data attribution methods to PyTorch models
e.g., Influence Function, TracIn, RPS, TRAK, ...
Develop new data attribution methods with efficient implementation of low-level utility functions
e.g., Hessian (HVP/IHVP), Fisher Information Matrix (IFVP), random projection, dropout ensembling, ...
Benchmark data attribution methods with standard benchmark settings
e.g., MNIST-10+LR/MLP, CIFAR-10/2+ResNet-9, MAESTRO + Music Transformer, Shakespeare + nanoGPT, ...
If you have time to watch one video last week, make sure it is this one:
Below The Fold(BTF)

Bun is an all-in-one toolkit for JavaScript and TypeScript apps. It ships as a single executable called bun.
At its core is the Bun runtime, a fast JavaScript runtime designed as a drop-in replacement for Node.js. It's written in Zig and powered by JavaScriptCore under the hood, dramatically reducing startup times and memory usage.

Foam is a personal knowledge management and sharing system inspired by Roam Research, built on Visual Studio Code and GitHub.
You can use Foam for organising your research, keeping re-discoverable notes, writing long-form content and, optionally, publishing it to the web.
Foam is free, open source, and extremely extensible to suit your personal workflow. You own the information you create with Foam, and you're free to share it, and collaborate on it with anyone you want.

Hurl is a command line tool that runs HTTP requests defined in a simple plain text format.
It can chain requests, capture values and evaluate queries on headers and body response. Hurl is very versatile: it can be used for both fetching data and testing HTTP sessions.
Hurl makes it easy to work with HTML content, REST / SOAP / GraphQL APIs, or any other XML / JSON based APIs.

Kan is the open-source project management alternative to Trello.
👁️ Board Visibility: Control who can view and edit your boards
🤝 Workspace Members: Invite members and collaborate with your team
🚀 Trello Imports: Easily import your Trello boards
🔍 Labels & Filters: Organise and find cards quickly
💬 Comments: Discuss and collaborate with your team
📝 Activity Log: Track all card changes with detailed activity history
🎨 Templates (coming soon) : Save time with reusable board templates
⚡️ Integrations (coming soon) : Connect your favourite tools

Quarkdown is a modern Markdown-based typesetting system, designed around the key concept of versatility, by seamlessly compiling a project into a print-ready book or an interactive presentation. All through an incredibly powerful Turing-complete extension of Markdown, ensuring your ideas flow automatically into paper.
PGQueuer is a minimalist, high-performance job queue library for Python, leveraging PostgreSQL's robustness. Designed with simplicity and efficiency in mind, PGQueuer offers real-time, high-throughput processing for background jobs using PostgreSQL's LISTEN/NOTIFY and FOR UPDATE SKIP LOCKED mechanisms.
Istio is an open source service mesh that layers transparently onto existing distributed applications. Istio’s powerful features provide a uniform and more efficient way to secure, connect, and monitor services. Istio is the path to load balancing, service-to-service authentication, and monitoring – with few or no service code changes.