

ThunderMLA vs FlashMLA
Libraries: TNN, MTRecLib, Verl, Picotron

Articles
ThunderMLA from Stanford researchers, a new optimization approach for variable-length sequence processing to large language model inference that addresses critical performance bottlenecks in attention mechanisms. ThunderMLA builds upon and substantially improves DeepSeek's FlashMLA through the implementation of a completely fused "megakernel" architecture, achieving performance gains of 20-35% across various workloads.
Background
Large language model inference, particularly in attention mechanisms during the decoding phase, faces challenges when handling variable-prompt workloads. While prefill operations typically allow for efficient GPU utilization by parallelizing across batch and sequence dimensions, the decoding phase encounters significant inefficiencies when processing small batches with limited queries.
The fundamental issues arise from the traditional approach of using multiple kernel launches, which introduces considerable overhead. This overhead manifests in three primary ways:
the computational cost of setting up and tearing down separate kernel launches,
tail effects between kernel executions that lead to suboptimal resource utilization,
limitations in batch sizes when running large reasoning models.
These inefficiencies become particularly pronounced in scenarios with imbalanced inputs. For instance, the researchers describe a representative workload involving a batch of four prompts with lengths ranging from 1,696 to 45,118 tokens, generating four new tokens with 8-way tensor parallelism on DeepSeek R1, resulting in 16 heads per GPU.
In this scenario, FlashMLA achieves only 144 TFLOPS and 1,199 GB/s on an SXM H100, substantially below the hardware's advertised capabilities of 939 TFLOPS and 3,300 GB/s. This is a large gap and main premise of the approach is to cover this performance gap.
ThunderMLA: Core Innovations and Architecture
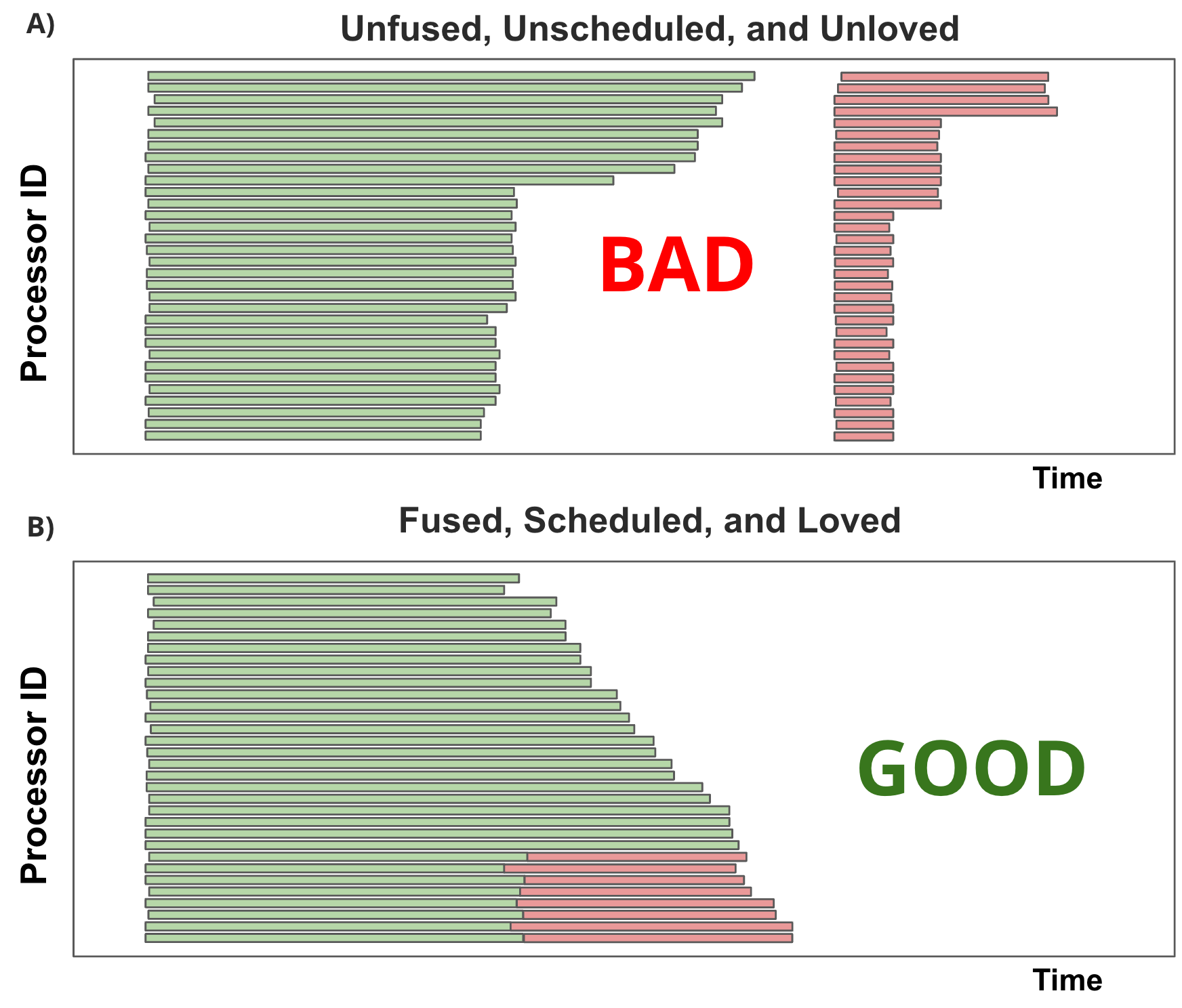
ThunderMLA introduces a completely fused megakernel that eliminates the overhead associated with multiple kernel launches. This approach enables to achieve 183 TFLOPS and 1,520 GB/s on the same representative workload mentioned earlier, reducing execution time from 52 microseconds to 41 microseconds – a substantial 21% improvement.
The architecture consists of four key components:
a novel interpreter template for building megakernels,
the ThunderMLA megakernel implementation itself
two specialized schedulers for work allocation
advanced timing infrastructure for performance analysis.
Traditional GPU programming involves sequences of distinct kernels that exchange data through global memory, whether in L2 cache or HBM. While this approach provides modularity and reusability of kernels, it introduces significant overhead through kernel setup and teardown operations, each potentially consuming several microseconds. Additionally, single-wave tail effects become particularly problematic in fast-decoding scenarios with small batches, and the use of multiple kernels prevents effective data reuse, increasing the GPU's memory bandwidth requirements.

1. ThunderKittens Templates
ThunderKittens template is the framework that provides capability for building megakernels. This approach eliminates kernel launches by creating a virtual instruction set directly on the GPU. Instead of launching separate kernels, the system fuses them into a single megakernel and then passes instructions at runtime through an instruction tensor. Within this megakernel, GPU Streaming Multiprocessors (SMs) read from the instruction tensor, determine the appropriate work to perform, and execute it accordingly.
The implementation involves an interpreter template within ThunderKittens that allows arbitrary simple kernels to be combined into a megakernel, each with its own opcode and instructions. This architecture delivers several key benefits: simplified pipelining within instructions and across loop boundaries, asynchronous fetching of future instructions to minimize overhead, and deep pipelines that effectively hide data fetch latencies both within and across instructions.
What makes this approach particularly efficient is its adaptation of slot attention and token reduction kernels into the interpreter template with minimal device code – just a few hundred lines. The system uses a global tensor as a semaphore to synchronize dependencies across instructions. Once the constituent kernels ("partial" and "reduction") are implemented, the megakernel can be instantiated using a simple template expression: interpreter::kernel<config, partial_template, reduction_template>.
ThunderMLA vs. DeepSeek's FlashMLA
One can compare FlashMLA with DeepSeek’s FlashMLA, which was released on February 24, 2025, during DeepSeek's Open Source Week.
FlashMLA is specifically optimized for NVIDIA's Hopper GPUs and incorporates important features like BF16 support and a paged KV cache with a block size of 64. DeepSeek's implementation draws inspiration from projects such as FlashAttention 2&3 and CUTLASS, making it a strong baseline for comparison.
ThunderMLA achieved a 23.6% speedup compared to FlashMLA in the above workload. The performance advantages extend across diverse workloads: for a batch size of 1 with a sequence length of 65,536 and a single query token, ThunderMLA demonstrated a 23.6% speedup; for 64 batches with random sequence lengths between 256-1024 and 4 query tokens, it showed a 19.0% improvement; and for 64 batches with a sequence length of 512 and 2 query tokens, the advantage increased to 36.3%.
These performance gains derive from ThunderMLA's fundamentally different approach to kernel execution. While FlashMLA excels at handling variable-length sequences through optimized memory usage and computation on Hopper GPUs, ThunderMLA takes this optimization a step further by eliminating the overhead associated with multiple kernel launches and introducing sophisticated scheduling techniques.

Advanced Scheduling Approaches in ThunderMLA
A critical component of ThunderMLA's performance advantages lies in its scheduling strategies. ThunderMLA uses two distinct approaches to scheduling work and generating instruction tensors: a Static Scheduler and a more sophisticated Makespan Backwards Scheduler.
The Static Scheduler employs a straightforward approach that divides jobs into small pieces, synthesizes a k-way reduction tree to merge operations, and utilizes a heap-based priority queue to allocate work to available Streaming Multiprocessors (SMs). This strategy delivers good performance across various scenarios but has limitations in optimally overlapping reduction and compute operations because it doesn't account for task timing when creating instructions.
The Makespan Backwards Scheduler represents a more advanced approach that optimizes the makespan (total execution time) more aggressively. It works backward from the final event of the kernel, which is a single reduction task for each token, and runs heuristic rollouts to determine the optimal execution path, assigning processor IDs to each task. This approach can reduce execution time by an additional 10% compared to the Static Scheduler.
Despite requiring 1-2 milliseconds to compute schedules (which is slower than the kernel execution itself), this approach remains viable for several reasons. Schedules can be reused across multiple layers in large models, generation can occur asynchronously on the CPU while previous batches are running, schedules for similar batch sizes change infrequently, and when changes do occur, they typically require only simple updates.
Novel Profiling Tools and Infrastructure
The development of ThunderMLA revealed limitations in NVIDIA's existing tools for understanding the performance of heterogeneous and dataflow-driven kernels. While NVIDIA Compute Profiler (NCU) is valuable for many applications, it proved inadequate for analyzing kernels where hardware resources are more constraining than thread execution.
To address this gap, researchers also developed custom timing infrastructure that generates detailed Gantt charts of kernel execution. This infrastructure tracks various events, including consumer setup phases, producer load and consumer compute phases, and synchronization delays in the production tree. The resulting visualizations are used for improving kernels, infrastructure, and schedulers.
The timing infrastructure includes a pipeline for writing out timing data with minimal overhead. For example, the team used this tool to remove approximately 2 microseconds of kernel latency from partial operations by optimizing the filling sequence of the three-stage KV cache pipeline – an optimization that would have been difficult to identify without these specialized profiling tools.
Libraries

TNN: A high-performance, lightweight neural network inference framework open sourced by Tencent Youtu Lab. It also has many outstanding advantages such as cross-platform, high performance, model compression, and code tailoring. The TNN framework further strengthens the support and performance optimization of mobile devices on the basis of the original Rapidnet and ncnn frameworks. At the same time, it refers to the high performance and good scalability characteristics of the industry's mainstream open source frameworks, and expands the support for X86 and NV GPUs. On the mobile phone, TNN has been used by many applications such as mobile QQ, weishi, and Pitu. As a basic acceleration framework for Tencent Cloud AI, TNN has provided acceleration support for the implementation of many businesses.
verl is a flexible, efficient and production-ready RL training library for large language models (LLMs).
verl is the open-source version of HybridFlow: A Flexible and Efficient RLHF Framework paper.
verl is flexible and easy to use with:
Easy extension of diverse RL algorithms: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.
Seamless integration of existing LLM infra with modular APIs: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.
Flexible device mapping: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.
Readily integration with popular HuggingFace models
verl is fast with:
State-of-the-art throughput: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.
Efficient actor model resharding with 3D-HybridEngine: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.

MTReclib provides a PyTorch implementation of multi-task recommendation models and common datasets. Currently, we implmented 7 multi-task recommendation models to enable fair comparison and boost the development of multi-task recommendation algorithms. The currently supported algorithms include:
SingleTask:Train one model for each task, respectively
Shared-Bottom: It is a traditional multi-task model with a shared bottom and multiple towers.
OMoE: Adaptive Mixtures of Local Experts (Neural Computation 1991)
MMoE: Modeling Task Relationships in Multi-task Learning with Multi-Gate Mixture-of-Experts (KDD 2018)
PLE: Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations (RecSys 2020 best paper)
AITM: Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising (KDD 2021)
MetaHeac: Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising (KDD 2021)
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation and can work with PyTorch.

The library works as a bridge between natural language processing (NLP) and recommender systems (RecSys) by integrating with one of the most popular NLP frameworks, Hugging Face Transformers (HF). Transformers4Rec makes state-of-the-art transformer architectures available for RecSys researchers and industry practitioners.
Traditional recommendation algorithms usually ignore the temporal dynamics and the sequence of interactions when trying to model user behavior. Generally, the next user interaction is related to the sequence of the user's previous choices. In some cases, it might be a repeated purchase or song play. User interests can also suffer from interest drift because preferences can change over time. Those challenges are addressed by the sequential recommendation task.

In the spirit of NanoGPT, HuggingFace created Picotron: The minimalist & most-hackable repository for pre-training Llama-like models with 4D Parallelism (Data, Tensor, Pipeline, Context parallel). It is designed with simplicity and educational purposes in mind, making it an excellent tool for learning and experimentation.
The code itself is simple and readable:
train.py,model.pyand[data|tensor|pipeline|context]_parallel.pyare all under 300 lines of code.Performance is not the best but still under active development. We observed 38% MFU on a LLaMA-2-7B model using 64 H100 GPUs and nearly 50% MFU on the SmolLM-1.7B model with 8 H100 GPUs. Benchmarks will come soon
Compared to Nanotron, Picotron is primarily for educational purposes, helping people quickly get familiar with all the techniques in distributed training

Researchers and developers are increasingly invoking multiple LLM calls in a compound AI system to solve complex tasks. But which LLM should one select for each call?
LLMSELECTOR is a framework that automatically optimizes model selection for compound AI systems.
Compound AI systems that involve multiple LLM calls are widely studied and developed in academy and industry. But does calling different LLMs in these systems make a difference? As suggested in Figure 1, the difference can be significant, and no LLM is the universally best choice. This leads to an important question: which LLM should be selected for each call in a compound system? The search space is exponential and exhaustive search is cumbersome.
Below The Fold
isd – a better way to work with systemd units
Simplify systemd management with isd! isd is a TUI offering fuzzy search for units, auto-refreshing previews, smart sudohandling, and a fully customizable interface for power-users and newcomers alike.
Checkmate is an open-source, self-hosted monitoring tool for tracking server hardware, uptime, response times, and incidents in real time with beautiful visualizations. Checkmate regularly checks whether a server/website is accessible and performs optimally, providing real-time alerts and reports on the monitored services' availability, downtime, and response time.

rainfrog is to provide a lightweight, terminal-based alternative to pgadmin/dbeaver.
features
efficient navigation via vim-like keybindings and mouse controls
query editor with keyword highlighting and session history
quickly copy data, filter tables, and switch between schemas
shortcuts to view table metadata and properties
cross-platform (macOS, linux, windows, android via termux)

Wan2.1, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
Atom of Thoughts is a lightweight, standalone implementation of the paper Atom of Thoughts for Markov LLM Test-Time Scaling. An implementation under the MetaGPT (ICLR 2024 Oral) framework is also coming soon, which will be suitable for users familiar with that framework and its excellent open-source projects including but not limited to AFlow (ICLR 2025 Oral).

Apache ECharts is a free, powerful charting and visualization library offering easy ways to add intuitive, interactive, and highly customizable charts to your commercial products. It is written in pure JavaScript and based on zrender, which is a whole new lightweight canvas library.