State Space Sequence Models over Transformers?
Notion's Data Lake and Warehouse Solution, Melange

Articles
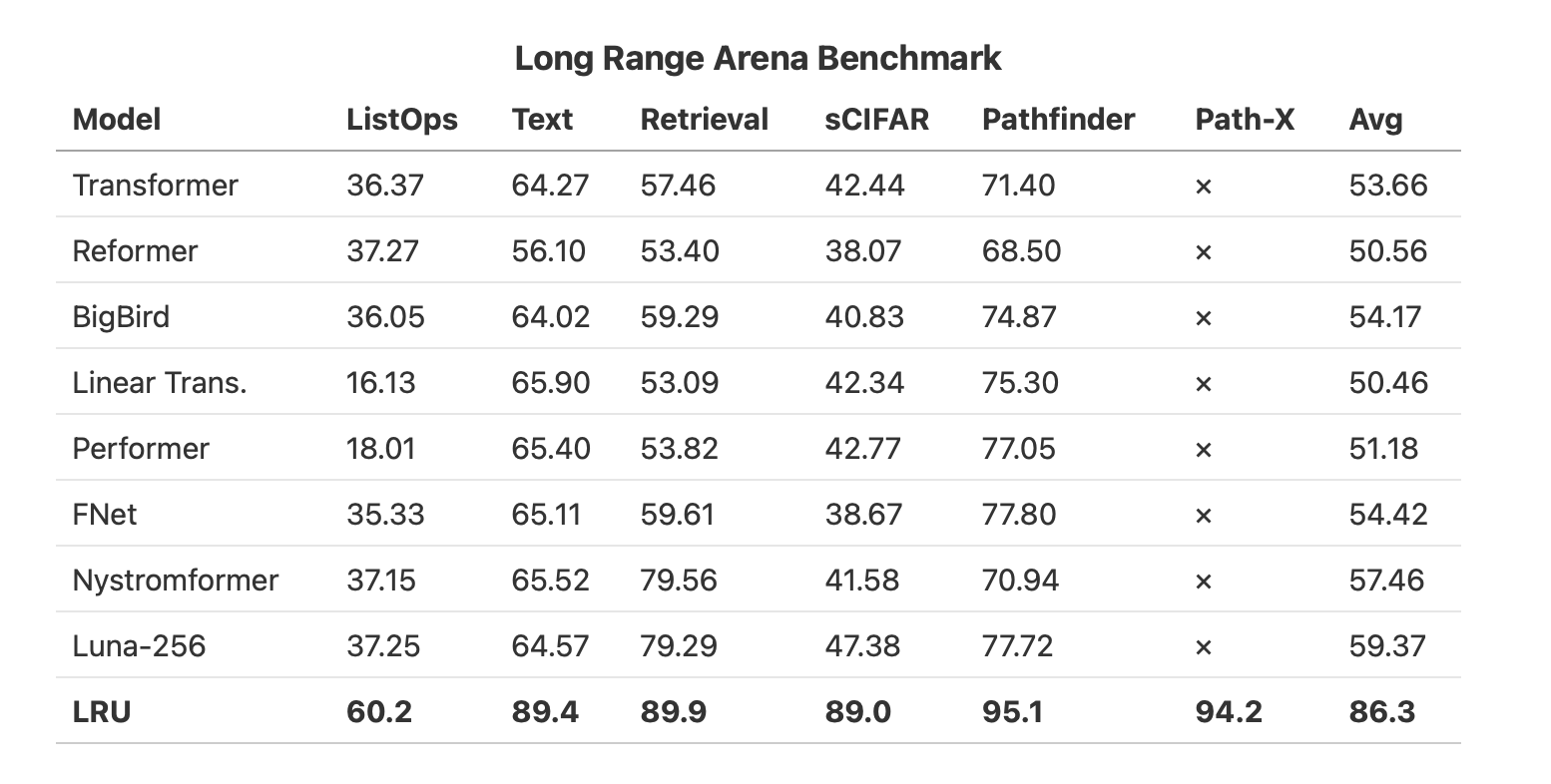
State Space Sequence Models is proposed to be a net iteration on the modeling front to the transformers for some time and Chetan Nichkawde wrote a blog post on some of its properties for State Space Sequence Models.
It starts with some good properties for transformers, and then, afterwards, the blog post talks about the state space sequence models and its properties and other advantages to the existing modeling approaches like Transformers.
What makes Transformers great?
The efficacy of self-attention due to its ability to route information densely within a context window, allowing it to model complex data.
What are the challenges with Transformer models?
Inability to model anything outside of the context window.
Quadratic complexity and scaling for training and inference with respect to the sequence length.
What makes State Space models great?
It has linear complexity with respect to the sequence length during the training time which can easily be parallelized using parallel scans.
Many times faster during inference. It can do inference in constant time using the current state compared to Transformers which requires computation of self-attention over the entire context.
They can easily model very long range context and have been shown to model a context length of about 1 million tokens. The Transformers cannot model long context due to quadratic scaling with respect to the sequence length.
They can do inferences on sequences of any length and longer than the longest sequence in the training data.
More specifically, they have the following advantages/capabilities:
Long-range dependencies: SSMs can effectively model very long sequences, often outperforming Transformers on tasks requiring long-range context. This is particularly useful for continuous time series data such as audio, health signals, and video.
Computational efficiency: SSMs are more computationally efficient than Transformers, especially for long sequences. They can be parallelized efficiently, making them fast at both training and inference time.
Continuous-time modeling: SSMs naturally handle continuous-time data and can work with irregularly sampled sequences. This makes them robust to changes in sampling rates or resolution.
Stability and control: The linear nature of SSMs allows for explicit design of stability characteristics through eigenvalue analysis, ensuring bounded and stable behavior over long sequences.
Memory efficiency: Unlike Transformers, which typically have quadratic memory complexity with sequence length, SSMs can have linear or even constant memory complexity.
The post goes in detail on the building blocks/components as well:
The core building blocks of SSMs are which went into detail in the post:
State-space representation: This is the fundamental mathematical framework underlying SSMs. It consists of:
A state vector x(t)
An input vector u(t)
An output vector y(t)
State transition matrix A
Input matrix B
Output matrix C
Direct transmission matrix D
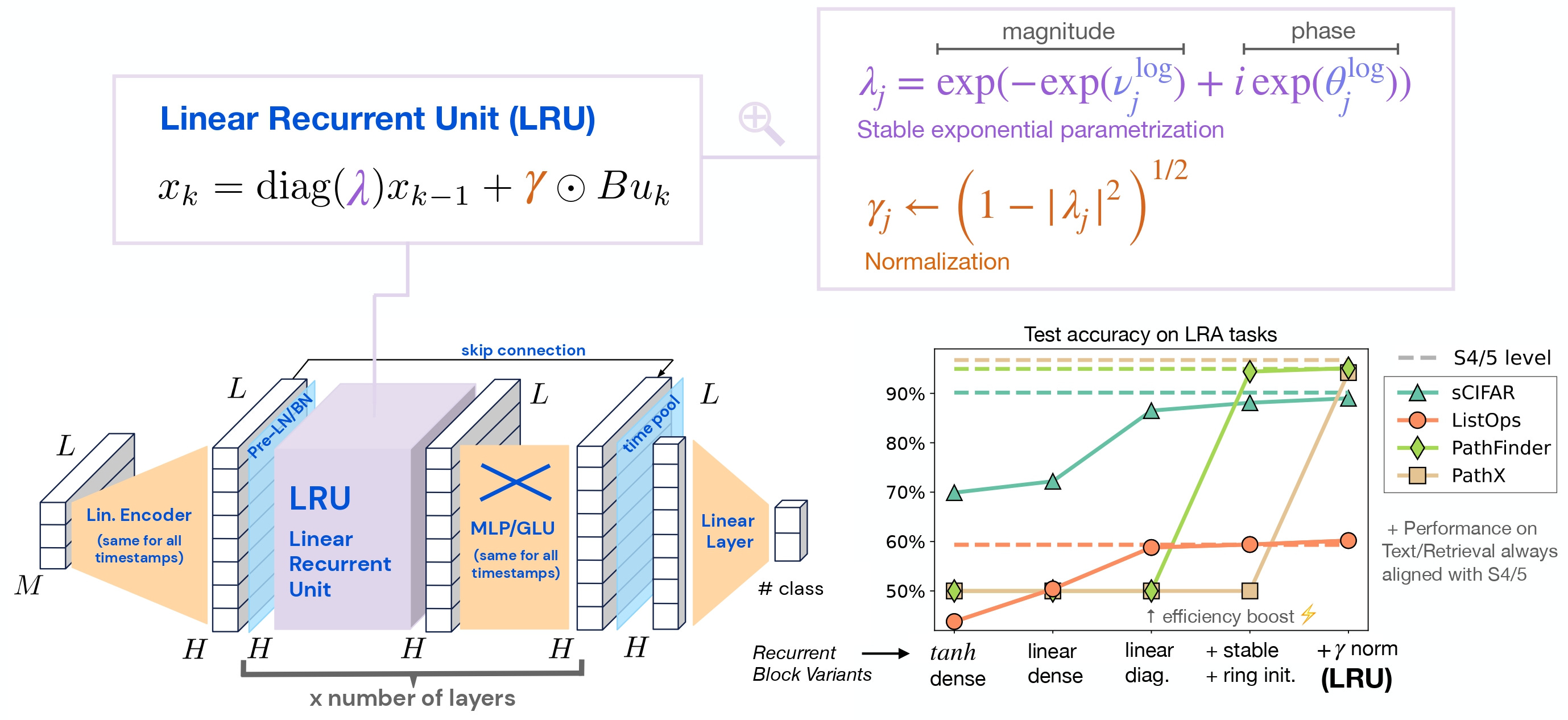
Linear Recurrent Unit (LRU): This is a key component in models like S4. It features:
A diagonal structure for efficient parallel computation
Exponential parameterization to ensure stability
Careful initialization to promote long-range information propagation
HiPPO (High-order Polynomial Projection Operator): This technique, introduced in earlier work, provides a principled way to project continuous functions onto learnable basis functions, enabling effective modeling of long-range dependencies.
Structured matrices: S4 and similar models use specially structured matrices (e.g., diagonal plus low-rank) to enable efficient computation and parameterization.
Discretization methods: To apply SSMs to discrete-time data, various discretization methods are used, such as Zero-Order Hold (ZOH) or bilinear transformations.
Normalization layers: Like many deep learning models, SSMs often incorporate normalization layers (e.g., LayerNorm) to stabilize training.
Skip connections: These are used to facilitate gradient flow in deep SSM architectures, similar to their use in other deep neural networks.
Nonlinear activation functions: While the core of SSMs is linear, nonlinear activations are typically applied between SSM layers to increase model expressivity.
Convolutional layers: Some SSM architectures incorporate convolutional layers to capture local patterns efficiently.
Attention mechanisms: While not a core component of SSMs, some hybrid models combine SSMs with attention mechanisms to leverage the strengths of both approaches.
It is an excellent especially building the intuition of the state space models in general and want to understand the building blocks of these family of models.

Tyler wrote a blog post discusses a new method called Mélange for optimizing the cost efficiency of Large Language Model (LLM) deployments by exploiting GPU heterogeneity.
Main Problems To Solve:
LLM Deployment Challenges:
LLMs are increasingly integrated into online services but their deployment is often cost-prohibitive due to expensive GPU resources.
While many prior works focus on improving inference engine performance, this study emphasizes choosing the most cost-effective GPU type(s) for LLM services
GPU Heterogeneity:
There's a growing variety of AI hardware accelerators available, including different types of GPUs and other specialized hardware.
Higher cost doesn't always equate to higher performance in this diverse landscape
Key Factors Influencing GPU Cost Efficiency:
a) Request Size:Lower-end GPUs are more cost-effective for small request sizes, while higher-end GPUs are better for large request sizes
There's no universally most cost-efficient GPU for a given LLM; it depends on the request size
b) Request Rate:
At low request rates, using more affordable, lower-end GPUs can save costs
A mix of GPU types allows for finer-grained scaling, better matching resources to workload demand.
c) Service-Level Objectives (SLOs):
Strict SLOs require high-performance GPUs, but lower-end GPUs can be used for looser SLOs to reduce costs
Both request size and SLO must be considered together when determining cost efficiency

Melange itself is a scheduler that schedules the GPUs in different capabilities:
Mélange is a GPU allocation framework that determines the minimal-cost GPU allocation for a given LLM service
It uses offline profiling to measure GPU performance across request sizes and rates
The allocation task is framed as a cost-aware bin packing problem and solved using an integer linear program (ILP)
Mélange is heterogeneity-aware and flexible, adapting to various GPU types and service specifications

Experimental Results:
Experiments were conducted using various NVIDIA GPU types (L4, A10G, A100, H100), model sizes (Llama2-7b and Llama2-70b), and SLOs (40ms, 120ms)
Three datasets are selected to represent different service scenarios: short-context tasks, long-context tasks, and mixed-context tasks
Key findings:
For short-context tasks, Mélange achieved 15-77% cost reduction (120ms SLO) and 9-68% reduction (40ms SLO) compared to single-GPU strategies
For long-context tasks, cost reductions of 15-33% (120ms SLO) and 2-22% (40ms SLO) were achieved
In mixed-context scenarios, Mélange delivered 13-51% cost reduction (120ms SLO) and 4-51% reduction (40ms SLO)

Notion has written an excellent post on how they built and scaled their data lake to manage rapid data growth and support critical product and analytics use cases, including their AI features.
Notion experienced a 10x data expansion over three years, with data doubling every 6-12 months. By 2021, they had over 20 billion block rows in Postgres, growing to over 200 billion blocks by 2024. To manage this growth, Notion expanded from a single Postgres instance to a sharded architecture, eventually reaching 96 physical instances with 480 logical shards.

Challenges
In 2021, Notion used Fivetran to ingest data from Postgres to Snowflake, setting up 480 hourly-run connectors.
Operability: Managing 480 Fivetran connectors became burdensome.
Speed and cost: Ingesting data to Snowflake became slower and more expensive due to Notion's update-heavy workload.
Use case support: Complex data transformation needs surpassed standard SQL capabilities.
Requirements for the new System
Notion decided to build an in-house data lake with the following objectives:
Store raw and processed data at scale.
Enable fast, scalable, and cost-efficient data ingestion and computation.
Support AI, Search, and other product use cases requiring denormalized data
and they made the following key design decisions:
Using S3 as the data repository and lake.
Choosing Spark as the main data processing engine.
Preferring incremental ingestion over snapshot dumps.
Using Kafka Debezium CDC connectors for Postgres to Kafka ingestion.
Selecting Apache Hudi for Kafka to S3 ingestion.
Ingesting raw data before processing

Eventual Data Lake Architecture and Setup:
Ingesting incrementally updated data from Postgres to Kafka using Debezium CDC connectors.
Using Apache Hudi to write updates from Kafka to S3.
Performing transformation, denormalization, and enrichment on the raw data.
Storing processed data in S3 or downstream systems for various use cases
CDC connector and Kafka setup: One Debezium CDC connector per Postgres host, deployed in an AWS EKS cluster.
Hudi setup: Using Apache Hudi Deltastreamer for ingestion, with specific configurations for partitioning, sorting, and indexing.
Spark data processing setup: Utilizing PySpark for most jobs and Scala Spark for complex tasks.
Bootstrap setup: A process to initialize new tables in the data lake
They have implemented a nice data warehouse solution that depends on the changelog of the main database to support various writes in the incremental updates and snapshot updates for various havey workloads.
Libraries

Optax is a gradient processing and optimization library for JAX. It is designed to facilitate research by providing building blocks that can be recombined in custom ways in order to optimise parametric models such as, but not limited to, deep neural networks.

Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
a family of vision-centric multimodal LLMs (MLLMs). Cambrian-1 is structured around five key pillars:
Visual Representations: We explore various vision encoders and their combinations.
Connector Design: We design a new dynamic and spatially-aware connector that integrates visual features from several models with LLMs while reducing the number of tokens.
Instruction Tuning Data: We curate high-quality visual instruction-tuning data from public sources, emphasizing the importance of distribution balancing.
Instruction Tuning Recipes: We discuss instruction tuning strategies and practices.
Benchmarking: We examine existing MLLM benchmarks and introduce a new vision-centric benchmark, "CV-Bench".
Cambrian-10M is a comprehensive dataset designed for instruction tuning, particularly in multimodal settings involving visual interaction data. The dataset is crafted to address the scarcity of high-quality multimodal instruction-tuning data and to maintain the language abilities of multimodal large language models (LLMs).
Videos to Watch
CS 3330 from Stanford is an excellent class for Meta Learning
Andrew Yates (Assistant Prof at the University of Amsterdam) Sergi Castella (Analyst at Zeta Alpha), and Gabriel Bénédict (PhD student at the University of Amsterdam) discuss the prospect of using GPT-like models as a replacement for conventional search engines.
Andrej Karpahy(founding member of OpenAI) delivered a keynote speech in a hackahhon. It is short, but it is a good watch if you have 20-30 minutes.
Waterloo university has a graduate level class called Recent Advances in Foundation Models.
HuggingFace has excellent Transformers class.
More to Read
Remove is a good read for reminding us that end of the product/writing is also not just commission, but also omission.