Stanford develops Holistic Evaluation of Language Models(HELM), Google identifies disfluencies in Speech
DeepMind's Operating Principles and Best Practices for Data Enrichment

If you are looking for something to do in US for the long weekend, you may want to check out the Pen and Paper Exercises for ML:

Articles

Stanford HAI develops a holistic way to measure/benchmark Foundation Models; called Holistic Evaluation of Language Models (HELM). They have 3 areas that want to establish
Broad coverage and recognition of incompleteness. Given language models’ vast surface of capabilities and risks, we need to evaluate language models over a broad range of scenarios. However, it is not possible to consider all the scenarios, so holistic evaluation should make explicit all the major scenarios and metrics that are missing.
Multi-metric measurement. Societally beneficial systems are characterized by many desiderata, but benchmarking in AI often centers on one (usually accuracy). Holistic evaluation should represent these plural desiderata.
Standardization. Our object of evaluation is the language model, not a scenario-specific system. Therefore, in order to meaningfully compare different LMs, the strategy for adapting an LM to a scenario should be controlled for. Further, we should evaluate all the major LMs on the same scenarios to the extent possible.
The paper goes into much more detail in various sections.
Deepmind shared their best practices for their data enrichment in the following blog post. The following principles are adopted for their use case:
Select an appropriate payment model and ensure all workers are paid above the local living wage.
Design and run a pilot before launching a data enrichment project.
Identify appropriate workers for the desired task.
Provide verified instructions and/or training materials for workers to follow.
Establish clear and regular communication mechanisms with workers.
Their operating principles cover a larger surface on how they operate as a company:
Social benefit: Advancing the development, distribution and use of our technologies for broad social benefit, particularly in those application areas to which AI technologies are uniquely suited, such as advancing science and addressing climate and sustainability;
Scientific excellence & integrity: Achieving and maintaining the highest levels of scientific excellence and integrity through rigorously applying the scientific method and being at the forefront of artificial intelligence research and development;
Safety and ethics: Upholding and contributing to best practices in the fields of AI safety and ethics, including fairness and privacy, to avoid unintended outcomes that create risks of harm;
Accountability to people: Designing AI systems that are aligned with and accountable to people, with appropriate levels of interpretability and human direction and control, and engaging with a wide range of stakeholder groups to gather feedback and insights;
Sharing knowledge responsibly: Sharing scientific advances thoughtfully and responsibly by continuously evaluating our work, including our research and publications, to maximise their potential for social benefit and minimise potential harms; and
Diversity, equity and inclusion: Advancing diversity, equity and inclusion in every part of our organisation and in the AI ecosystem, including advocating for fair and just outcomes as AI technologies are applied.
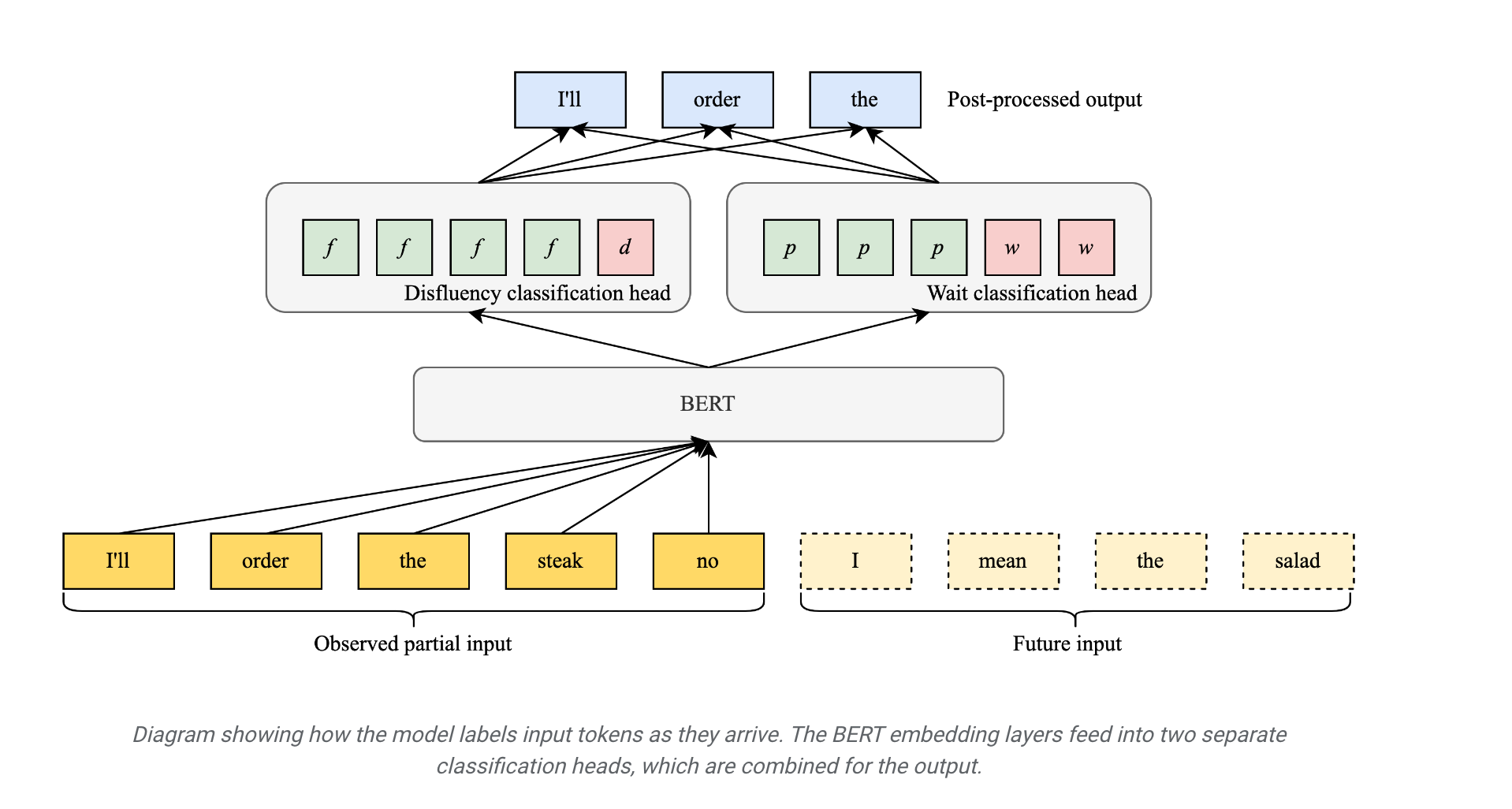
Google wrote a blog post on how they train a model that can identify speech disfluencies.
A speech disfluency, also spelled speech dysfluency, is any of various breaks, irregularities, or non-lexical vocables which occur within the flow of otherwise fluent speech. These include "false starts", i.e. words and sentences that are cut off mid-utterance; phrases that are restarted or repeated and repeated syllables; "fillers", i.e. grunts or non-lexical utterances such as huh, uh, erm, um, well, so, like, and hmm; and "repaired" utterances, i.e. instances of speakers correcting their own slips of the tongue or mispronunciations (before anyone else gets a chance to).
This is very crucial for speech recognition as we communicate a lot more messy in speech than in writing form. We need to remember certain words, but also not saying anything is hard, so we add a number of filler words, repetition and utterance. It is also important to be able to detect and remove these in order to handle speech recognition well.
In the model that is backed by Bert, they train two heads tasks; disfluency head and wait head.
Disfluency task predicts whether the word is disfluency or not and wait task predicts whether the “word” should be used or not in the speech. Disfluency task if more backwards looking and wait head is more future looking.
Libraries
This repository contains all the assets for Holistic Evaluation of Language Models, which includes the following features:
Collection of datasets in a standard format (e.g., NaturalQuestions)
Collection of models accessible via a unified API (e.g., GPT-3, MT-NLG, OPT, BLOOM)
Collection of metrics beyond accuracy (efficiency, bias, toxicity, etc.)
Collection of perturbations for evaluating robustness and fairness (e.g., typos, dialect)
Modular framework for constructing prompts from datasets
Proxy server for managing accounts and providing unified interface to access models
While deep learning models have replaced hand-designed features across many domains, these models are still trained with hand-designed optimizers. In this work, they leverage the same scaling approach behind the success of deep learning to learn versatile optimizers. They train an optimizer for deep learning which is itself a small neural network that ingests gradients and outputs parameter updates. Meta-trained with approximately four thousand TPU-months of compute on a wide variety of optimization tasks, their optimizer not only exhibits compelling performance, but optimizes in interesting and unexpected ways. It requires no hyperparameter tuning, instead automatically adapting to the specifics of the problem being optimized.
VeLO is a learned optimizer: instead of updating parameters with SGD or Adam, the approach is to update them using a learning rule that was meta-learned on thousands of deep learning tasks. The architecture of VeLO consists of a LSTM to aggregate information from each tensor in the deep network being optimized, and per-parameter MLPs that produce the update rule for each parameter with weights generated by the LSTM.
Parti treats text-to-image generation as a sequence-to-sequence modeling problem, analogous to machine translation – this allows it to benefit from advances in large language models, especially capabilities that are unlocked by scaling data and model sizes. In this case, the target outputs are sequences of image tokens instead of text tokens in another language. Parti uses the powerful image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens, and takes advantage of its ability to reconstruct such image token sequences as high quality, visually diverse images.
AutoGluon automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy machine learning and deep learning models on image, text, time series, and tabular data.
MOSAIC is a neural network architecture for efficient and accurate semantic image segmentation on mobile devices. MOSAIC is designed using commonly supported neural operations by diverse mobile hardware platforms for flexible deployment across various mobile platforms. With a simple asymmetric encoder-decoder structure which consists of an efficient multi-scale context encoder and a light-weight hybrid decoder to recover spatial details from aggregated information, MOSAIC achieves better balanced performance while considering accuracy and computational cost. Deployed on top of a tailored feature extraction backbone based on a searched classification network, MOSAIC achieves a 5% absolute accuracy gain on ADE20K with similar or lower latency compared to the current industry standard MLPerf mobile v1.0 models and state-of-the-art architectures.
On Twitter
