

Stanford CRFM suggests moving to workflows rather than tasks for evaluation!
Google introduces Ro-Vit and Retrieval-VLP

Articles

Stanford CRFM(Center for Foundational Models) wrote an excellent article on the ml evaluation and why ml evaluation on tasks are poised to create a lot of problems.
They argue that the tasks for evaluations that are done are just small steps of much larger pipelines. For example, a doctor could use ML-assisted tools for detecting pneumonia in an X-ray. But it is the combination of this detection with other analyses (patient history, lab results, previous scans, etc.) that determines how the doctor treats the patient.
The problem is that evaluating performance on a specific task is often not a good indicator of the quality of end-to-end workflows (e.g. in medical imaging). In these scenarios, we would want validation protocols that not only evaluate if a model is good for some task(s), but also evaluate how the model impacts a user’s end-to-end workflow.
One way to make ML systems useful in practice is to shift ML validation from being task-centric to being workflow-centric.
Workflow-centric validation shifts the focus from evaluating the ML model to evaluating how successful a user’s workflow would be if they were to use the model. In other words, we care about the quality of the full workflow rather than only the quality of a single or a few tasks. This perspective can give us a realistic working template of how ML models can be used successfully in practice.
However, even with workflow based flows, we will have
Here are some of the challenges that they talk about even when we consider workflows:
Workflows aren’t public: In many cases, clear definitions or code for workflows are seldom available. If they are available, they are rarely built for public use (e.g. not modular, no clear entry points). Like traditional benchmarking, this makes it challenging for creating transparent understanding where the gaps in performance are.
Analysis workflows are not standardized: In any domain, users have particular, often personalized, workflows, which makes it difficult to standardize what workflows warrant benchmarking. In fact, these workflows are so unstandardized that the FDA (and other regulatory agencies) rely on companies asking for ML approval to define their own testing procedure.
Too much work: Frankly, validation can be hard to orchestrate. Labeled data for benchmarking each task of a workflow is not always available and is often expensive to collect. Additionally, evaluating models when the workflows are vague and hard to benchmark make it even less appealing to do.
Metrics != qualitative utility: User interaction is inherently a qualitative process, and it’s no different when we think about how users would interact with ML tools. However, current metrics are not designed to capture the nuances of how users would feel when interacting with these ML systems.
These are some of their recommendations:
Facilitate open-source: Work with domain experts to develop and distribute their workflows and associated user-informed metrics. This can help establish some user-led consensus on end-to-end workflows where ML methods can be helpful for their fields.
Make workflows usable: Build benchmarking suites so that with minimal code, users can get up and running with endpoint-driven workflows. This can reduce the barrier on entry for both ML experts with limited domain knowledge and domain experts with limited ML knowledge.
Show user utility: Demonstrate that evaluating models in a workflow-centric way actually leads to downstream outcomes for patients (less cost, better prognosis, etc.). Making these benchmarks visible to the public ensures there is transparency, which is critical for facilitating ML adoption.
Build interactive tools: Use user interfaces to ground the qualitative nature of user-model interactions in more quantitative metrics (time to success, rate of retention, etc.). Libraries like Streamlit and Gradio have considerably simplified building applications for ML models. More recently, we built Meerkat to focus on bridging the gap between ML models and data interfaces, which can help with large scale data visualization and exploration, and qualitative validation studies for new ML tools.
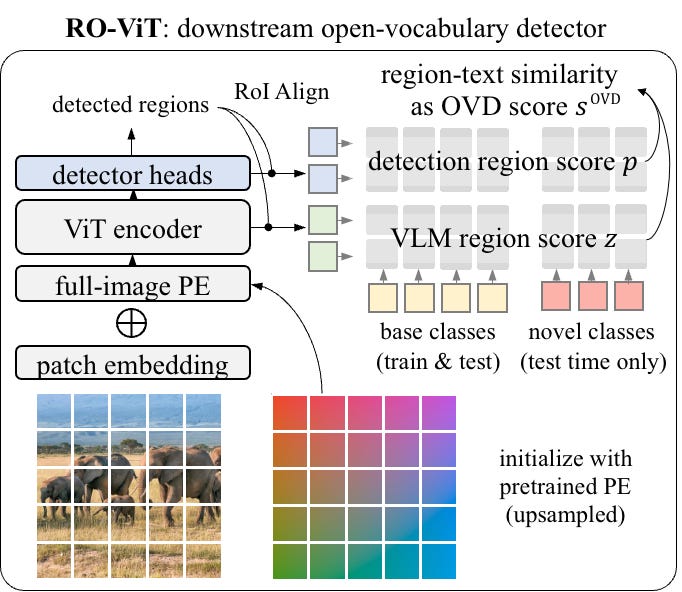
Google Research wrote a blog post explaining introduction of a new method for pre-training vision transformers for open-vocabulary object detection.
They argue that existing methods for pre-training vision transformers for open-vocabulary object detection are not effective because they do not fully leverage the concept of objects or regions during the pre-training phase. To address this, they propose a new method called RO-ViT, which stands for Region-Aware Vision Transformer.
RO-ViT introduces a simple but effective way to incorporate region information into the pre-training of vision transformers. Specifically, RO-ViT uses a positional encoding that is aware of the object regions in the image. This allows the vision transformer to learn to attend to the relevant regions of the image when making predictions.
The authors evaluated RO-ViT on the open-vocabulary object detection task and showed that it outperforms state-of-the-art methods. They also showed that RO-ViT can be used to fine-tune on other object detection tasks, such as object detection in the wild.
Some of the advantages of RO-ViT:
Positional encoding: In vision transformers, positional encoding is used to add information about the spatial position of each patch within the image. This is important because it allows the vision transformer to learn to attend to different parts of the image.
Region-aware positional encoding: RO-ViT uses a region-aware positional encoding that is aware of the object regions in the image. This is done by randomly cropping and resizing regions of the positional embeddings. This ensures that the vision transformer learns to attend to the relevant regions of the image, even when the objects are not located at the center of the image.
Contrastive learning: RO-ViT is trained using a contrastive learning approach. This means that the model is trained to distinguish between positive pairs (images and captions that describe the same object) and negative pairs (images and captions that do not describe the same object).

Google AI introduces a new method for pre-training vision-language models that combines retrieval and language modeling.
They argue that existing methods for pre-training vision-language models are not effective because they do not fully leverage the power of retrieval. To address this, they propose a new method called retrieval-augmented visual-language pre-training (Retrieval-VLP).
Retrieval-VLP works by first retrieving a set of relevant images for a given text query. The text query and the retrieved images are then used to train a language model. This allows the language model to learn to generate text that is relevant to the images.
The authors evaluated Retrieval-VLP on the Visual Genome dataset and showed that it outperforms state-of-the-art methods. They also showed that Retrieval-VLP can be used to fine-tune on other downstream tasks, such as image captioning and visual question answering.
Philipp Schmid wrote a blog post on how to optimize large language models (LLMs) using the GPTQ quantization method and the Hugging Face Optimum platform. GPTQ is a post-training quantization method that can reduce the size of LLMs by up to 8x without significantly impacting performance. Hugging Face Optimum is a platform that makes it easy to deploy and manage quantized LLMs.
The article begins by providing an overview of LLMs and quantization. It then discusses the benefits of using GPTQ and Hugging Face Optimum. The article then provides a step-by-step guide on how to optimize an LLM using GPTQ and Hugging Face Optimum.
GPTQ is a post-training quantization method that works by rounding the weights of an LLM to a lower precision. This can significantly reduce the size of the model without significantly impacting performance. GPTQ is based on the idea of gradual quantization, which means that the weights are rounded gradually from full precision to the desired precision. This helps to minimize the performance loss.
Hugging Face Optimum is a platform that makes it easy to deploy and manage quantized LLMs. It provides a number of features that make it easy to deploy quantized models to production, such as:
A pre-trained model zoo with a variety of quantized LLMs
A cloud-based inference service that can be used to deploy quantized models
A set of tools for managing quantized models
He predicts that GPTQ and Hugging Face Optimum will become increasingly popular tools for optimizing LLMs.
Libraries
Code Llama is a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama was developed by fine-tuning Llama 2 using a higher sampling of code.

Scalene is a high-performance CPU, GPU and memory profiler for Python that does a number of things that other Python profilers do not and cannot do. It runs orders of magnitude faster than many other profilers while delivering far more detailed information. It is also the first profiler ever to incorporate AI-powered proposed optimizations.
Autodistill uses big, slower foundation models to train small, faster supervised models. Using
autodistill, you can go from unlabeled images to inference on a custom model running at the edge with no human intervention in between.VALL-E X is an amazing multilingual text-to-speech (TTS) model proposed by Microsoft. While Microsoft initially publish in their research paper, they did not release any code or pretrained models. Recognizing the potential and value of this technology, Plachtaa took on the challenge to reproduce the results and train their own model.
ChatDev stands as a virtual software company that operates through various intelligent agents holding different roles, including Chief Executive Officer, Chief Technology Officer, Programmer, Tester, and more. These agents form a multi-agent organizational structure and are united by a mission to "revolutionize the digital world through programming." The agents within ChatDev collaborate by participating in specialized functional seminars, including tasks such as designing, coding, testing, and documenting.
The primary objective of ChatDev is to offer an easy-to-use, highly customizable and extendable framework, which is based on large language models (LLMs) and serves as an ideal scenario for studying collective intelligence.
The performance degradation of lithium batteries is a complex electrochemical process, involving factors such as the growth of solid electrolyte interface, lithium precipitation, loss of active materials, etc. Furthermore, this inevitable performance degradation can have a significant impact on critical commercial scenarios, such as causing 'range anxiety' for electric vehicle users and affecting the power stability of energy storage systems. Therefore, effectively analyzing and predicting the performance degradation of lithium batteries to provide guidance for early prevention and intervention has become a crucial research topic.
To this end, Microsoft open sources the BatteryML tool to facilitate the research and development of machine learning on battery degradation. BatteryML can empower both battery researchers and data scientists to gain deeper insights from battery degradation data and build more powerful models for accurate predictions and early interventions.

DialogStudio is a large collection and unified dialog datasets. The figure below provides a summary of the general statistics associated with DialogStudio. DialogStudio unified each dataset while preserving its original information, and this aids in supporting research on both individual datasets and Large Language Model (LLM) training. The full list of all available datasets is here.