Speculative Decoding for LLM
GPUStack, WordLlama, Magika, Sillytavern!

Articles

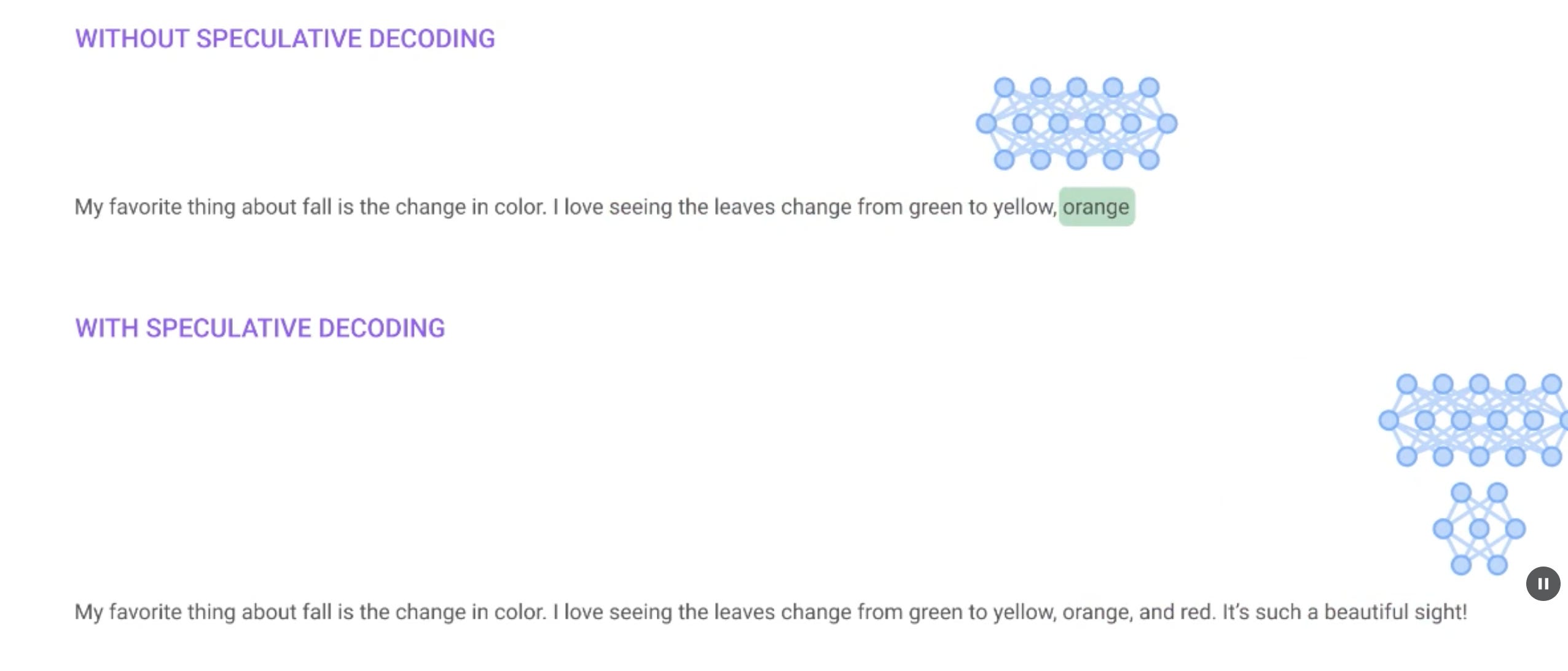
Speculative decoding is a technique that can significantly improve the inference for large language models (LLMs) by reducing latency and improving efficiency without compromising output quality. Google has written a nice article on how they are using this technique to improve the snippets that they show in the beginning of the search page.
Speculative decoding applies the principle of speculative execution to LLM inference. The process involves two main components:
A smaller, faster "draft" model
The larger target LLM
The draft model generates multiple tokens in parallel, which are then verified by the target model. This approach guarantees an output distribution identical to traditional decoding methods.
Phases
Drafting Phase: The smaller model efficiently generates a sequence of draft tokens, speculating on future decoding steps of the target LLM
Verification Phase: The larger target model verifies all drafted tokens in parallel.
Token Acceptance: Only tokens meeting the LLM's verification criterion are accepted as final outputs, ensuring generation quality.
The process can be formalized as follows:
Given an input sequence x and the target LLM P_LLM, the draft model P_draft decodes the next K drafted tokens:
::: y_draft = (y_1, ..., y_K) ~ P_draft(·|x)
where P_draft(·|x) is the conditional probability distribution calculated by the draft model.
Drafting Process
Various drafting strategies can be employed, including:
Using a smaller version of the target LLM
Employing a specialized non-autoregressive Transformer
Utilizing knowledge distillation from the target to the draft model
Verification Process
The verification step is crucial for maintaining output quality. It involves comparing the probabilities assigned by the target LLM to the drafted tokens against a threshold or sampling from the LLM's distribution
Advantages Over Traditional Approaches
Speculative decoding offers several significant advantages over traditional autoregressive decoding:
Reduced Latency: By generating multiple tokens in parallel, speculative decoding can achieve 2x-3x improvements in inference speed for tasks like translation and summarization.
Energy Efficiency: Faster results with the same hardware mean fewer machines are needed for serving the same amount of traffic, reducing energy costs.
Maintained Quality: The method preserves the same quality of responses as traditional decoding.
Reduced Computational Overhead: Unlike autoregressive decoding, which requires K iterations of the model to generate K tokens, speculative decoding reduces the need for constant full-model passes.
Memory Efficiency: The approach allows for less frequent access to LLM parameters, alleviating memory bottlenecks present in previous inference methods.
Comparison with Other Approaches
It has many other advantages to other decoding techniques, I will give an overview and main advantages of this approach over other types of techniques.
Traditional Autoregressive Decoding
In traditional autoregressive decoding, tokens are generated sequentially, with each token depending on all previous tokens. This approach, while effective, suffers from high latency due to its sequential nature.
Beam Search Decoding
Beam search decoding maintains multiple candidate sequences at each step, potentially improving output quality but not addressing the fundamental latency issue of sequential generation.
Non-Autoregressive Decoding
Non-autoregressive methods aim to generate all tokens in parallel but often struggle with maintaining coherence and quality in longer sequences. Speculative decoding strikes a balance between these approaches, offering the quality of autoregressive methods with improved efficiency.
Recent Developments and Variations
Since its introduction, several innovative applications and ideas using the speculative decoding paradigm have emerged:
Large-scale Distributed Setups: Implementing speculative decoding across distributed computing environments for even greater efficiency gains.
Multiple Draft Guesses: Instead of a single draft sequence, generating multiple candidate drafts to increase the likelihood of acceptance.
Knowledge Distillation: Transferring knowledge from the target model to the draft model to improve draft quality and increase acceptance rates.
Partial Use of Target Model: Allowing the draft model to access certain layers or components of the target model for improved accuracy.
Single Model Serving as Both Draft and Target: Developing models that can efficiently perform both drafting and verification roles.
Batch Verification of Draft Tokens: Optimizing the verification process by evaluating multiple drafted sequences simultaneously.
Application to Other Domains: Extending the concept to image and speech generation tasks.
I highly recommend checking out the following survey paper for a comprehensive technique overview of speculative coding as well.
Libraries
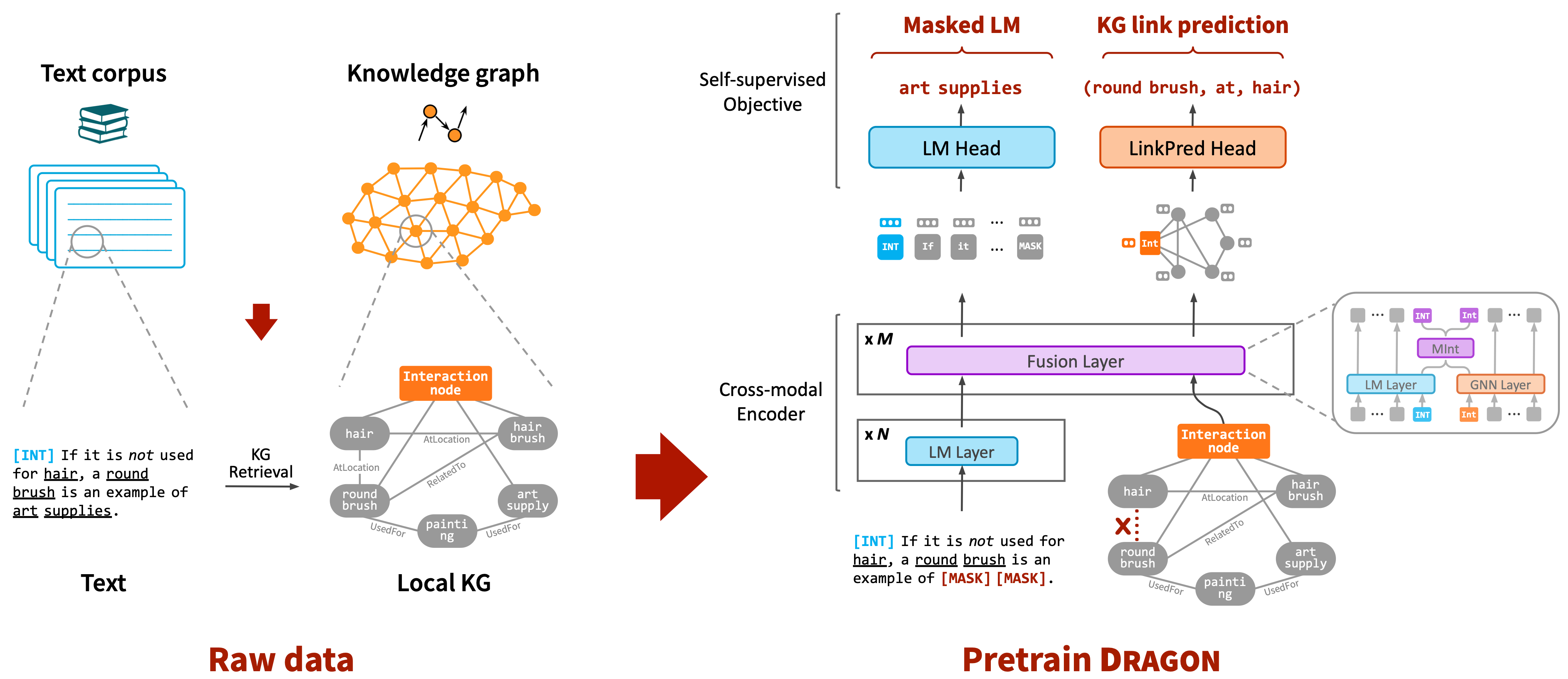
DRAGON is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. Specifically, it was trained with two simultaneous self-supervised objectives, language modeling and link prediction, that encourage deep bidirectional reasoning over text and knowledge graphs.
DRAGON can be used as a drop-in replacement for BERT. It achieves better performance in various NLP tasks, and is particularly effective for knowledge and reasoning-intensive tasks such as multi-step reasoning and low-resource QA.

GPUStack is an open-source GPU cluster manager for running large language models(LLMs).
Key Features
Supports a Wide Variety of Hardware: Run with different brands of GPUs in Apple MacBooks, Windows PCs, and Linux servers.
Scales with Your GPU Inventory: Easily add more GPUs or nodes to scale up your operations.
Distributed Inference: Supports both single-node multi-GPU and multi-node inference and serving.
Multiple Inference Backends: Supports llama-box (llama.cpp) and vLLM as the inference backends.
Lightweight Python Package: Minimal dependencies and operational overhead.
OpenAI-compatible APIs: Serve APIs that are compatible with OpenAI standards.
User and API key management: Simplified management of users and API keys.
GPU metrics monitoring: Monitor GPU performance and utilization in real-time.
Token usage and rate metrics: Track token usage and manage rate limits effectively.

WordLlama is a fast, lightweight NLP toolkit designed for tasks like fuzzy deduplication, similarity computation, ranking, clustering, and semantic text splitting. It operates with minimal inference-time dependencies and is optimized for CPU hardware, making it suitable for deployment in resource-constrained environments.
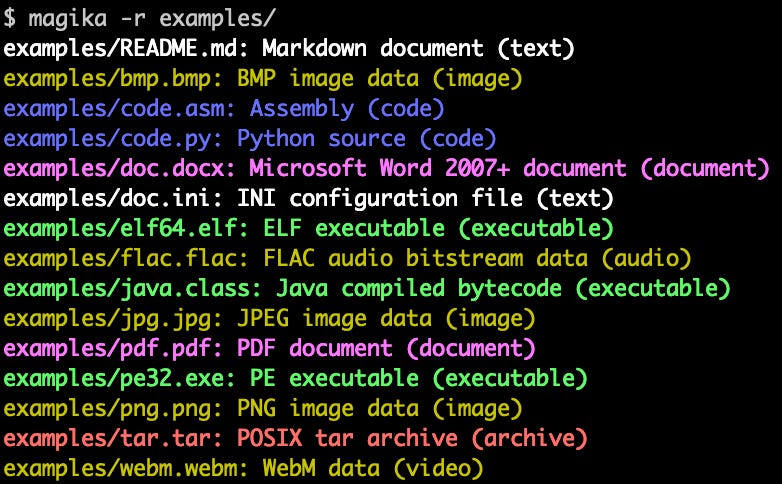
Magika is a novel AI powered file type detection tool that relies on the recent advance of deep learning to provide accurate detection. Under the hood, Magika employs a custom, highly optimized Keras model that only weighs about a few MBs, and enables precise file identification within milliseconds, even when running on a single CPU.
In an evaluation with over 1M files and over 100 content types (covering both binary and textual file formats), Magika achieves 99%+ precision and recall. Magika is used at scale to help improve Google users’ safety by routing Gmail, Drive, and Safe Browsing files to the proper security and content policy scanners.

SillyTavern provides a single unified interface for many LLM APIs (KoboldAI/CPP, Horde, NovelAI, Ooba, Tabby, OpenAI, OpenRouter, Claude, Mistral and more), a mobile-friendly layout, Visual Novel Mode, Automatic1111 & ComfyUI API image generation integration, TTS, WorldInfo (lorebooks), customizable UI, auto-translate, more prompt options than you'd ever want or need, and endless growth potential via third-party extensions.

TinyTroupe is an experimental Python library that allows the simulation of people with specific personalities, interests, and goals. These artificial agents - TinyPersons - can listen to us and one another, reply back, and go about their lives in simulated TinyWorld environments. This is achieved by leveraging the power of Large Language Models (LLMs), notably GPT-4, to generate realistic simulated behavior. This allow us to investigate a wide range of convincing interactions and consumer types, with highly customizable personas, under conditions of our choosing. The focus is thus on understanding human behavior and not on directly supporting it (like, say, AI assistants do) -- this results in, among other things, specialized mechanisms that make sense only in a simulation setting. Further, unlike other game-like LLM-based simulation approaches, TinyTroupe aims at enlightening productivity and business scenarios, thereby contributing to more successful projects and products. Here are some application ideas to enhance human imagination:
Advertisement: TinyTroupe can evaluate digital ads (e.g., Bing Ads) offline with a simulated audience before spending money on them!
Software Testing: TinyTroupe can provide test input to systems (e.g., search engines, chatbots or copilots) and then evaluate the results.
Training and exploratory data: TinyTroupe can generate realistic synthetic data that can be later used to train models or be subject to opportunity analyses.
Product and project management: TinyTroupe can read project or product proposals and give feedback from the perspective of specific personas (e.g., physicians, lawyers, and knowledge workers in general).
Brainstorming: TinyTroupe can simulate focus groups and deliver great product feedback at a fraction of the cost!
Nexa SDK is a local on-device inference framework for ONNX and GGML models, supporting text generation, image generation, vision-language models (VLM), audio-language models, speech-to-text (ASR), and text-to-speech (TTS) capabilities. Installable via Python Package or Executable Installer.
Features
Device Support: CPU, GPU (CUDA, Metal, ROCm), iOS
Server: OpenAI-compatible API, JSON schema for function calling and streaming support
Local UI: Streamlit for interactive model deployment and testing
inferit is a visual take on llm inference. Most inference frontends are limited to a single visual input/output "thread". This makes it hard to compare output from different models, prompts and sampler settings. inferit solves this with its UI that allows for an unlimited number of side-by-side generations. This makes it a perfect fit to compare and experiment with different models, prompts and sampler settings.
Other Goodies

dstack is a streamlined alternative to Kubernetes and Slurm, specifically designed for AI. It simplifies container orchestration for AI workloads both in the cloud and on-prem, speeding up the development, training, and deployment of AI models.

AutoKitteh is a developer platform for workflow automation and orchestration. It is an easy-to-use, code-based alternative to no/low-code platforms (such as Zapier, Workato, Make.com, n8n) with unlimited flexibility.
You write in vanilla Python, we make it durable 🪄
In addition, it is a durable execution platform for long-running and reliable workflows. It is based on Temporal, hiding many of its infrastructure and coding complexities.
Karate is the only open-source tool to combine API test-automation, mocks, performance-testing and even UI automation into a single, unified framework. The syntax is language-neutral, and easy for even non-programmers. Assertions and HTML reports are built-in, and you can run tests in parallel for speed.
There's also a cross-platform stand-alone executable for teams not comfortable with Java. You don't have to compile code. Just write tests in a simple, readable syntax - carefully designed for HTTP, JSON, GraphQL and XML. And you can mix API and UI test-automation within the same test script.
A Java API also exists for those who prefer to programmatically integrate Karate's rich automation and data-assertion capabilities.
SeqiLog provides building blocks to simulate hardware at the register transfer level (RTL) of abstraction:
Hierarchical, parameterized
Moduledesign elementFour-state
bitsmultidimensional array data typeDiscrete event simulation using
async/awaitsyntax
SeqiLog is declarative. To the extent possible, the designer should only need to know what components to declare, not how they interact with the task scheduling algorithm.
SeqiLog is strict. Functions should raise exceptions when arguments have inconsistent types. Uninitialized or metastable state should always propagate pessimistically.