

RLHF made easy: AlpacaFarm
Plex: Robust, Generalizable pre-trained Foundation Models from Google

Articles

Stanford published a blog post on how Reinforcement Learning Human Feedback(RLHF) can be made available in a low cost, more reliable and reproducible. Specifically, they introduce a system called “AlpacaFarm” makes the RLHF process accessible to everyone by providing a simulator that replicates the RLHF process quickly (24h) and cheaply ($200). They do this by constructing simulated annotators, automatic evaluations, and working implementations of state-of-the-art methods. In contrast to AlpacaFarm, collecting human feedback from crowdworkers can take up to weeks and thousands of dollars. As shown in the figure above, with AlpacaFarm, researchers can use the simulator to confidently develop new methods that learn from human feedback and transfer the best method to actual human preference data.
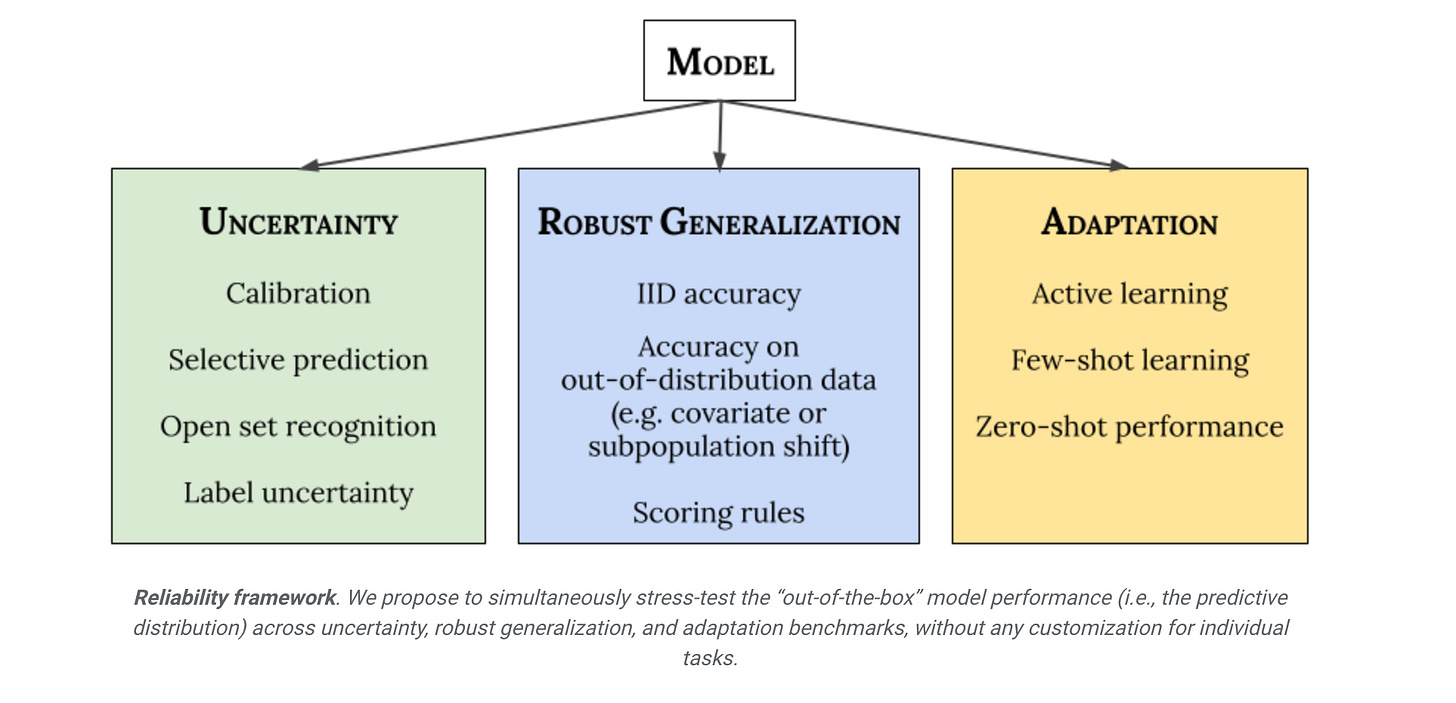
Google published a comprehensive framework(called Plex) for reliable deep learning model architectures in the following blog post. They broke down the framework into 3 main dimensions; Uncertainty, Robust Generalization and Adaptation.
Uncertainty reflects the imperfect or unknown information that makes it difficult for a model to make accurate predictions. Predictive uncertainty quantification allows a model to compute optimal decisions and helps practitioners recognize when to trust the model’s predictions, thereby enabling graceful failures when the model is likely to be wrong.
Robust Generalization involves an estimate or forecast about an unseen event. We investigate four types of out-of-distribution data: covariate shift (when the input distribution changes between training and application and the output distribution is unchanged), semantic (or class) shift, label uncertainty, and subpopulation shift.
Adaptation refers to probing the model’s abilities over the course of its learning process. Benchmarks typically evaluate on static datasets with pre-defined train-test splits. However, in many applications, we are interested in models that can quickly adapt to new datasets and efficiently learn with as few labeled examples as possible.
In “Plex: Towards Reliability Using Pre-trained Large Model Extensions”, they present a framework for reliable deep learning as a new perspective about a model’s abilities; this includes a number of concrete tasks and datasets for stress-testing model reliability. They also introduce Plex, a set of pre-trained large model extensions that can be applied to many different architectures. They illustrate the efficacy of Plex in the vision and language domains by applying these extensions to the current state-of-the-art Vision Transformer and T5 models, which results in significant improvement in their reliability. They are also open-sourcing the code to encourage further research into this approach.



Stanford published a post on how they introduce a new model architecture called Backpack to make the transformer based LLMs to be more interpretable. A Backpack is a drop-in replacement for a Transformer that provides new tools for interpretability-through-control while still enabling strong language models. Backpacks decompose the predictive meaning of words into components non-contextually, and aggregate them by a weighted sum, allowing for precise, predictable interventions. The name “Backpack” is inspired by the fact that a backpack is like a bag—but more orderly. Like a bag-of-words, a Backpack representation is a sum of non-contextual senses, but a Backpack is more orderly, because the weights in this sum depend on the ordered sequence.
Libraries
Guidance enables you to control modern language models more effectively and efficiently than traditional prompting or chaining. Guidance programs allow you to interleave generation, prompting, and logical control into a single continuous flow matching how the language model actually processes the text. Simple output structures like Chain of Thought and its many variants (e.g. ART, Auto-CoT, etc.) have been shown to improve LLM performance. The advent of more powerful LLMs like GPT-4 allows for even richer structure, and
guidancemakes that structure easier and cheaper.LMQL is a query language for large language models (LLMs). It facilitates LLM interaction by combining the benefits of natural language prompting with the expressiveness of Python. With only a few lines of LMQL code, users can express advanced, multi-part and tool-augmented LM queries, which then are optimized by the LMQL runtime to run efficiently as part of the LM decoding loop.
Open-Llama is an open-source project that offers a complete training pipeline for building large language models, ranging from dataset preparation to tokenization, pre-training, prompt tuning, lora, and the reinforcement learning technique RLHF.
WebLLM is a modular, customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and accelerated with WebGPU. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.
Awful AI is a curated list to track current scary usages of AI - hoping to raise awareness to its misuses in society. Artificial intelligence in its current state is unfair, easily susceptible to attacks and notoriously difficult to control. Often, AI systems and predictions amplify existing systematic biases even when the data is balanced. Nevertheless, more and more concerning uses of AI technology are appearing in the wild. This list aims to track all of them.
AI2 Tango replaces messy directories and spreadsheets full of file versions by organizing experiments into discrete steps that can be cached and reused throughout the lifetime of a research project.
The Meliad library is collection of models which are being developed as part of ongoing research into various architectural improvements in deep learning. The name "meliad" is the Greek word for a tree nymph; a long-term goal of this research is to design architectures that can understand recursive and compositional structures, i.e. trees.
The library currently consists of several transformer variations, which explore ways in which the popular transformer architecture can be extended to better support language modeling over long sequences.
Transformer-XL with sliding window
This model is provided as a baseline. It is similar to the Transformer-XL architecture, but uses a T5-style relative position bias. A long sequence, such as a book, is divided into segments of fixed length, e.g. 4096 tokens. The segments are processed in order, with one segment per training step.
Attention within a segment is done locally using sliding window that is typically smaller than the segment length.
Memorizing Transformer
The Memorizing Transformer equips one layer of the transformer with a large external memory that stores prior (key,value) pairs. Typical memory sizes are 32k or 64k tokens. In addition to local attention, the model can do k-nearest-neighbor lookup into the external memory, which allows it to handle long-range dependencies; the range is limited only by the size of the memory.
Block-Recurrent Transformer
The Block-Recurrent Transformer equips one layer of the transformer with a recurrent cell. The cell is structured similarly to an LSTM cell, but it is several orders of magnitude larger, and operates on blocks of tokens and blocks of recurrent state vectors.
Visual Blocks is a framework that allows any platform or application to easily integrate a visual and user-friendly interface for ML creation. Visual Blocks aims to help applications & platforms accelerate many stages of the ML product cycle including pipeline authoring, model evaluation, data pipelining, model & pipeline experimentation, and more. Visual Blocks enables these behaviors through a JavaScript front-end library for low/no code editing and a separate JS library embedding the newly created experience. The library is available in GitHub.
Conferences
Google has a Recommender Systems Summit which they will talk about practical recommender systems with an emphasis on Tensorflow and Jax ecosystem on how to use them.