Reducing carbonfootprint in AI/ML Workloads
Federated Learning with Formal Differential Privacy Guarantees

Libraries
tbparse is a library that allows you to load tensorboard event logs as pandas DataFrames for scientific plotting. It supports both PyTorch and TensorFlow.
anomalib is a deep learning library that aims to collect state-of-the-art anomaly detection algorithms for benchmarking on both public and private datasets, it provides several ready-to-use implementations of anomaly detection algorithms described in the recent literature, as well as a set of tools that facilitate the development and implementation of custom models.
textlesslib is a library aimed to facilitate research in Textless NLP. The goal of the library is to speed up the research cycle and lower the learning curve for those who want to start. We provide highly configurable, off-the-shelf available tools to encode speech as sequences of discrete values and tools to decode such streams back into the audio domain.
lightseq is a high performance training and inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, Sentiment Analysis, and other related tasks with sequence data.
FILM: Frame Interpolation for Large Motion is a Tensorflow2 implementation of our high quality frame interpolation neural network. They present a unified single-network approach that doesn't use additional pre-trained networks, like optical flow or depth, and yet achieve state-of-the-art results. They use a multi-scale feature extractor that shares the same convolution weights across the scales.
Wikipedia-based Image Text (WIT) Dataset is a large multimodal multilingual dataset. WIT is composed of a curated set of 37.6 million entity rich image-text examples with 11.5 million unique images across 108 Wikipedia languages. Its size enables WIT to be used as a pretraining dataset for multimodal machine learning models.
Articles
Google wrote about their efforts to reduce their carbon emissions for their AI/ML workloads in this blog post. They define the following “4M”s:
Machine. Using processors and systems optimized for ML training, versus general-purpose processors, can improve performance and energy efficiency by 2x–5x.
Mechanization. Computing in the Cloud rather than on premise reduces energy usage and therefore emissions by 1.4x–2x. Cloud-based data centers are new, custom-designed warehouses equipped for energy efficiency for 50,000 servers, resulting in very good power usage effectiveness (PUE). On-premise data centers are often older and smaller and thus cannot amortize the cost of new energy-efficient cooling and power distribution systems.
Map Optimization. Moreover, the cloud lets customers pick the location with the cleanest energy, further reducing the gross carbon footprint by 5x–10x. While one might worry that map optimization could lead to the greenest locations quickly reaching maximum capacity, user demand for efficient data centers will result in continued advancement in green data center design and deployment.
Model. Selecting efficient ML model architectures, such as sparse models, can advance ML quality while reducing computation by 3x–10x.

Amazon wrote about what is next for deep learning in this blog post. They call out two areas; symbolic reasoning and interactive learning.
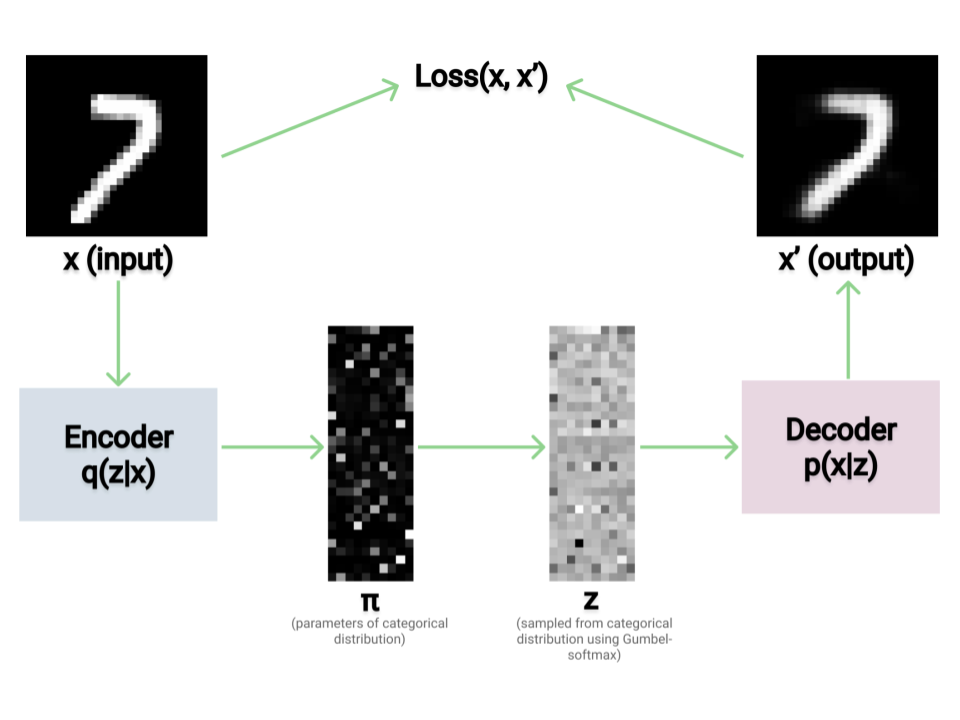
Jack Morris wrote about Variational Autoencoders in this blog post. The code that is written in PyTorch is also available in this collab notebook.

Google published a blog post where they propose a training strategy, named CoVeR, that leverages both image and video data to jointly learn a single general-purpose action recognition model. First, disparate video datasets cover a diverse set of activities, and training them together in a single model could lead to a model that excels at a wide range of activities. Second, video is a perfect source for learning motion information, while images are great for exploiting structural appearance. Leveraging a diverse distribution of image examples may be beneficial in building robust spatial representations in video models.

Google published a blog post on Federated Learning with Formal Differential Privacy Guarantees.
Achieving a formal privacy guarantee requires a protocol that does all of the following:
Makes progress on training even as the set of devices available varies significantly with time.
Maintains privacy guarantees even in the face of unexpected or arbitrary changes in device availability.
For efficiency, allows client devices to locally decide whether they will check in to the server in order to participate in training, independent of other devices.

Google wrote another blog post of TFRT(Tensorflow Runtime). TFRT aims to:
Deliver faster and cheaper execution for ML models
Enable more flexible deployment
Provide more modular and extensible infrastructure to facilitate innovations in ML infra and modeling
This post is a good way to show the similarities between data infrastructure and ML infrastructure.