

Pinterest introduces query rewards for retrieval
Google introduces Knowledge Transfer Network, OpenAI wrotes about their AGI principles

Articles

OpenAI wrote about principles for AGI:
They want AGI to empower humanity to maximally flourish in the universe. They don’t expect the future to be an unqualified utopia, but they want to maximize the good and minimize the bad, and for AGI to be an amplifier of humanity.
They want the benefits of, access to, and governance of AGI to be widely and fairly shared.
They want to successfully navigate massive risks. In confronting these risks, they acknowledge that what seems right in theory often plays out more strangely than expected in practice. They believe we have to continuously learn and adapt by deploying less powerful versions of the technology in order to minimize “one shot to get it right” scenarios.
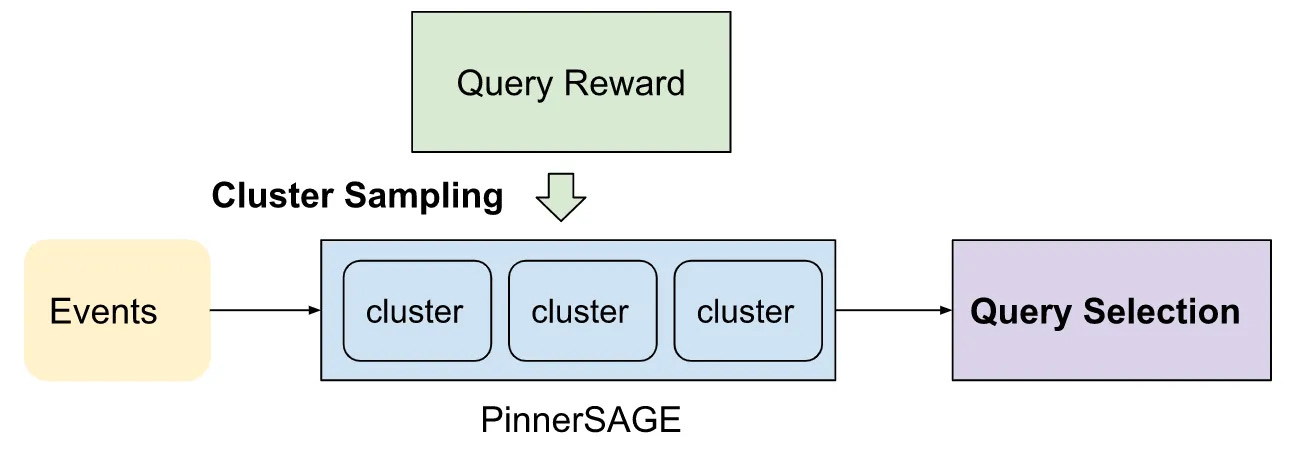
Pinterest wrote about how they incorporate query rewards in the query selection of their recommendation systems.
Main motivation for query rewards:
The query selection is relatively static if no new engagements happen. The main reason is that we only consider the action amount when we sample the clusters. Unless the user takes a significant number of new actions, the sampling distribution remains roughly the same.
No feedback is used for the future query selection. During each cluster sampling, we don’t consider the downstream engagements from the last request’s sampling results. A user may have had positive or negative engagement on the previous request, but don’t take that into account for their next request.
It cannot differentiate between the same action types aside from their timestamp. For example, if the actions inside the same cluster all happened around the same time, the weight of each action will be the same.
Through query rewards, they are able to incorporate user feedback much more faster and in a more responsive manner to be able to respond user request.
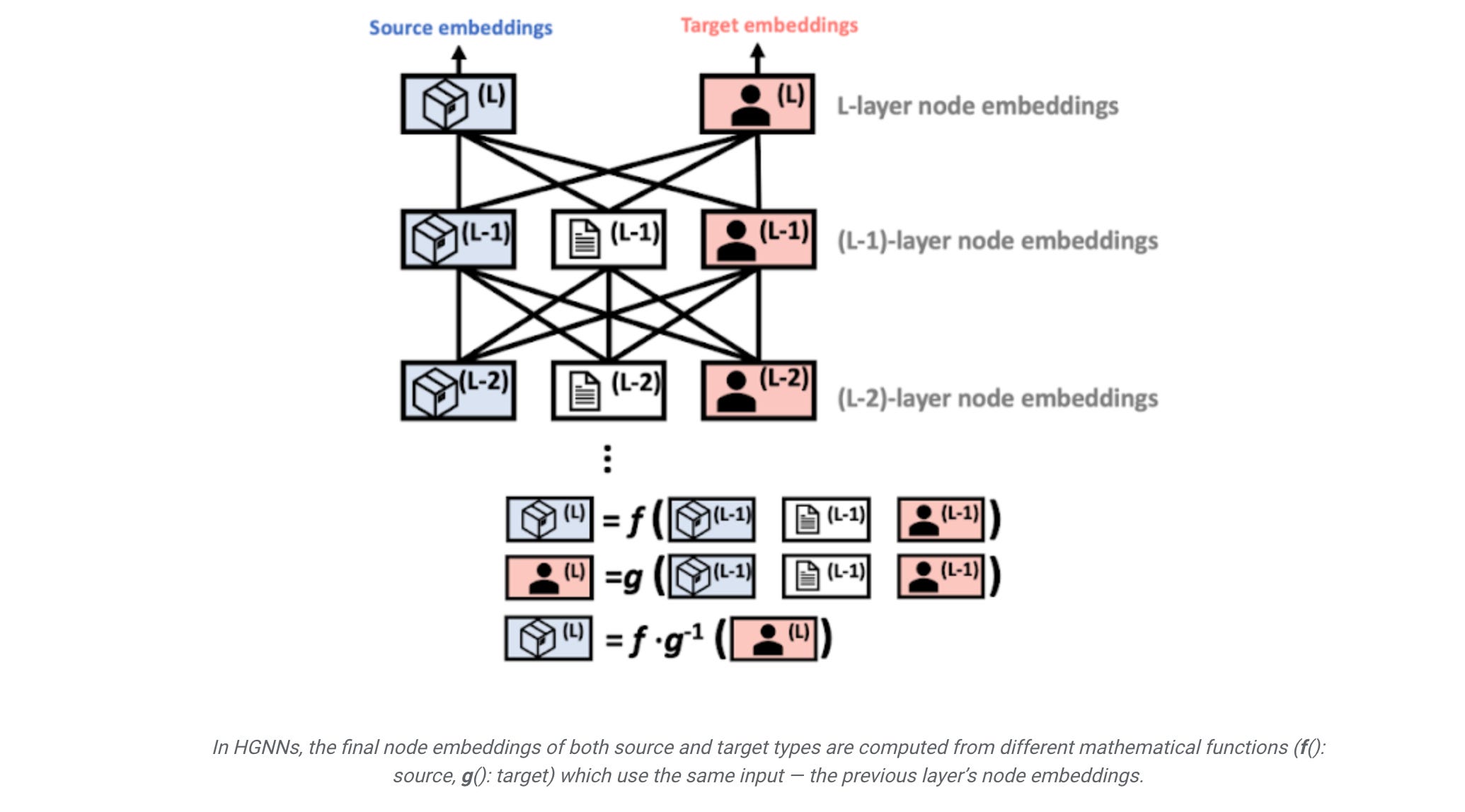
Google wrote about they built Knowledge Transfer Network(KTN) for Heteregenous Graph Neural Networks(HGNN)s.
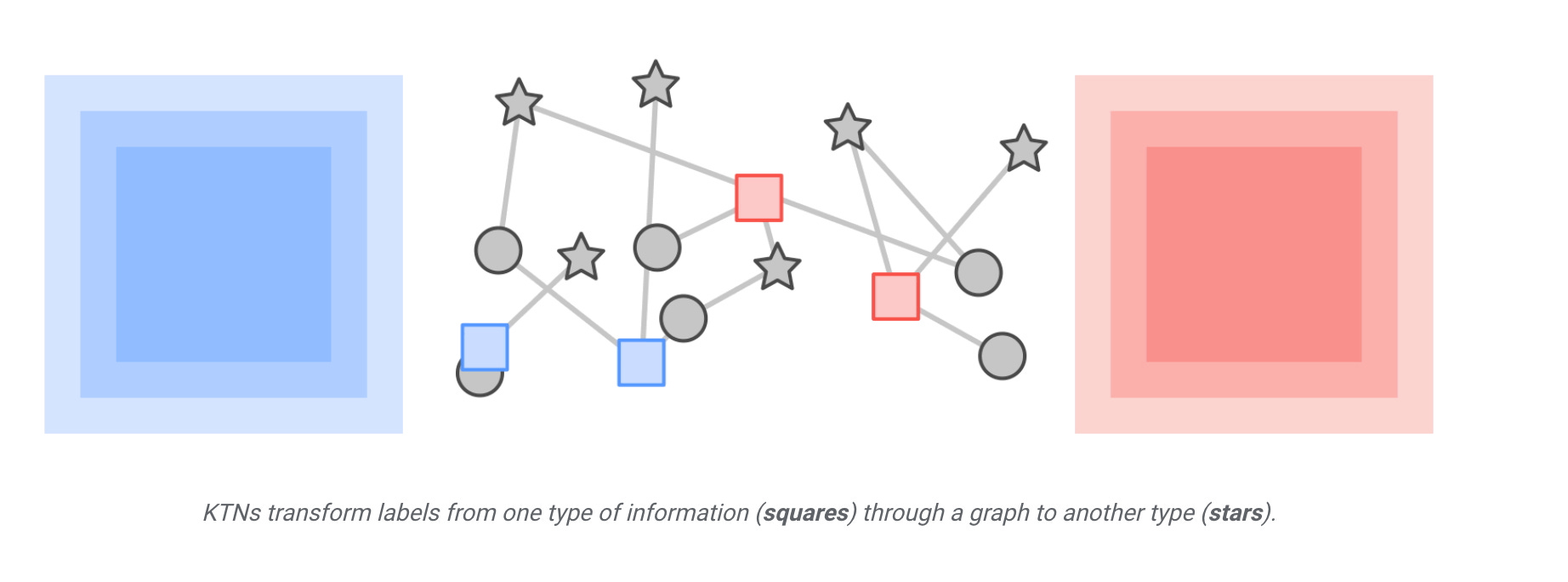
Main problem it solves:
Industrial applications of deep learning is label scarcity, and with their diverse node types, HGNNs are even more likely to face this challenge. For instance, publicly available content node types (e.g., product nodes) are abundantly labeled, whereas labels for user or account nodes may not be available due to privacy restrictions. This means that in most standard training settings, HGNN models can only learn to make good inferences for a few label-abundant node types and can usually not make any inferences for any remaining node types (given the absence of any labels for them).
The solution:
HGNNs aggregate connected node embeddings to augment a target node’s embeddings in each layer. In other words, the node embeddings for both source and target node types are updated using the same input — the previous layer’s node embeddings of any connected node types. This means that they can be represented by each other. Based on this theorem, they introduce an auxiliary neural network, which we refer to as a Knowledge Transfer Network (KTN), that receives the target node embeddings and then transforms them by multiplying them with a (trainable) mapping matrix. They then define a regularizer that is minimized along with the performance loss in the pre-training phase to train the KTN. At test time, they map the target embeddings computed from the pre-trained HGNN to the source domain using the trained KTN for classification.

Google wrote about their dataset search functionality. If you are looking for structured dataset, you should check it out. The schema is from schema.org and more details on the metadata and structure is here.
Libraries
Conditional text-to-image generation has seen countless recent improvements in terms of quality, diversity and fidelity. Nevertheless, most state-of-the-art models require numerous inference steps to produce faithful generations, resulting in performance bottlenecks for end-user applications. Paella, a novel text-to-image model requiring less than 10 steps to sample high-fidelity images, using a speed-optimized architecture allowing to sample a single image in less than 500 ms, while having 573M parameters. The model operates on a compressed & quantized latent space, it is conditioned on CLIP embeddings and uses an improved sampling function over previous works. Aside from text-conditional image generation, model is able to do latent space interpolation and image manipulations such as inpainting, outpainting, and structural editing.
Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator's assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties' privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights.
Simsity simple tools to help in similarity retrieval scenarios by making a convenient wrapper around hnswlib. Typical usecases include early stage bulk labelling and duplication discovery. It integrates well with another library embetter that we covered a while ago.
A fully featured audio diffusion library, written in Pytorch, includes models for unconditional audio generation, text-conditional audio generation, diffusion autoencoding, upsampling, and vocoding. The provided models are waveform-based, however, the U-Net (built using
a-unet),DiffusionModel, diffusion method, and diffusion samplers are both generic to any dimension and highly customizable to work on other formats.Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. But using these LLMs in isolation is often not enough to create a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge.
langchain is aimed at assisting in the development of those types of applications. Common examples of these types of applications include: