Pinterest introduces LinkSage, Google combines Neural Networks with Bayesian theory
AutoBNN, SSR-Encoder, LabML

Articles

Pinterest wrote an article on LinkSage that allows them to do offline content understanding by taking the following problem to solve:
Challenges of Understanding Off-Site Content: Understanding off-site content is challenging because Pinterest doesn't have direct control over the content or the way it is structured. This makes it difficult to use traditional techniques like natural language processing (NLP) to understand the content.

LinkSage addresses this challenge through:
Using a GNN to learn a representation of off-site content that can be used for tasks such as ranking and recommendation.
Further, it leverages Pinterest's machine learning signals, such as user clicks and saves, to understand the relationship between off-site content and Pinterest pins.
It also uses a heterogeneous graph that includes nodes for both Pinterest pins and off-site content. The graph also includes edges that represent the relationships between these nodes. For example, there might be an edge between a Pinterest pin and a piece of off-site content if the pin links to the content.
It ultimately wants to provide a single embedding representation for other applications/systems to consume; a unified semantic embedding of all the Pinterest off-site content. All the landing pages related to downstream models can leverage LinkSage embedding as a key input. By doing so, they can consolidate all of the efforts that are trying to learn for landing pages separately.
Under the hood; the model still leverages a Transformer encoder to learn the cross attention of self landing page features, neighbor landing page features, and graph structure features.
The text and crawled image features are split in the transformer encoder to let the model learn the cross attention of them. The neighbors are reverse sorted by the visited counts so the top neighbors would be more important than the bottom ones. Together with position embeddings, the model can learn the importance of different neighbors. The number of neighbors is chosen to balance computational cost and model performance.

They also provide these embeddings to downstream applications and teams by giving different dimensions of embeddings based on a tradeoff between embedding accuracy and computational cost. Instead of training and serving five different models separately, they leverage the Matryoshka Representation Learning to provide five dimensions of LinkSage in place by training only a single model. Shorter dimensions would capture a coarse representation of the landing pages, and more detailed level representation will be captured in the longer dimension ones.

Google wrote a rather interesting article that fuses Bayesian approaches with neural networks to do time-series forecasting through compositional elements that Bayesian approaches can bring(prior information, posterior computation) and computational flexibility of a neural network.

Compositional is in every sense of the word, they have a very compositional approach to bring bayesian approaches like picking a prior(Dirichlet distribution) as well as certain kernels from Gaussian Process to model the data, while still updating the kernels and posterior through a neural network to leverage scalability and flexibility of the NNs to offer.
They also open-source their library which I covered in below in Libraries section. If you want to use AutoBNN with tensor flow probability library, feel free to check it out.

Netflix wrote about how whey use Sequential Wald Test for validating the new codepath/features as they rollout through canary test/release. Sequential Wald Test is a hypothesis testing procedure used for sequential analysis. It allows for early stopping of the experiment based on the accumulating data.

In order to do so; they do the following computations:
Wald Statistic: At each point in time, the Wald statistic is calculated. This statistic essentially measures the difference between the observed counts in the treatment and control groups, standardized by the expected variability.
Stopping Boundaries: Two pre-defined boundaries are established: an upper bound and a lower bound. These boundaries represent the thresholds for statistical significance.
The upper bound indicates when the new version is performing significantly worse than the control.
The lower bound indicates when the new version is performing significantly better than the control.
How to make a decision?: As data accumulates, the Wald statistic is continuously computed. If the Wald statistic crosses the upper bound, the experiment is stopped, and the new version is rejected due to poor performance. Conversely, if the statistic crosses the lower bound, the experiment is stopped, and the new version is deemed an improvement at that point with statistical significance.
Technical Details

Poisson Distribution: Counts are modeled using the Poisson distribution, which captures the probability of a certain number of events occurring in a fixed interval.
Accounting for Variability: The expected variability in the counts needs to be factored into the Wald statistic calculation. This can be done by estimating the variance of the Poisson distribution based on historical data or the current observed counts.
Adjusting for Multiple Testing: When running multiple A/B tests simultaneously, adjustments to the significance levels may be necessary to control the overall probability of false positives (Type I errors).
Of course, after doing all this work, one has to integrate this into the canary release to integrate the change. Canary release involves deploying the new software version to a small subset of users (the canary group) before rolling it out to a wider audience. This allows for early detection of issues before they impact a large number of users.
Sequential A/B testing can be applied to monitor user behavior within the canary group, enabling faster decisions about rolling out the new version based on observed count metrics.
They claim that this approach had the following benefits:
Reduced Experiment Duration: Sequential A/B testing can significantly reduce the time it takes to reach a conclusion compared to traditional A/B testing. This allows for faster software iteration and improvement cycles.
Statistical Efficiency: By stopping experiments early when results are conclusive, sequential testing reduces the amount of data needed, making it statistically efficient. This also allows them to either stop or promote the changes as they are deemed better or worse.
Libraries

AutoBNN provides a powerful and flexible framework for building sophisticated time series prediction models. By combining the strengths of BNN(Bayesian Neural Network)s and GP(Gaussian Process)s with compositional kernels, AutoBNN opens a world of possibilities for understanding and forecasting complex data.
The AutoBNN package is available within Tensorflow Probability. It is implemented in JAX and uses the flax.linen neural network library. It implements all of the base kernels and operators discussed so far (Linear, Quadratic, Matern, ExponentiatedQuadratic, Periodic, Addition, Multiplication) plus one new kernel and three new operators:
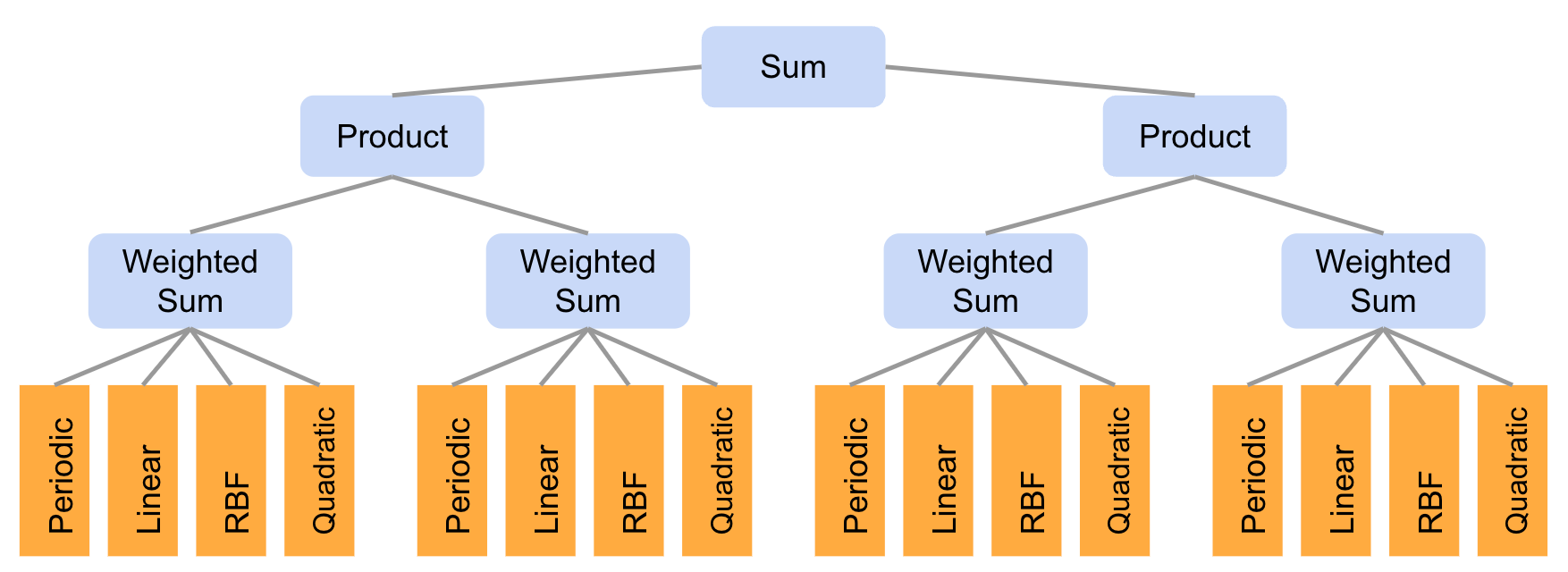
a
OneLayerkernel, a single hidden layer ReLU BNN,a
ChangePointoperator that allows smoothly switching between two kernels,a
LearnableChangePointoperator which is the same asChangePointexcept position and slope are given prior distributions and can be learnt from the data, anda
WeightedSumoperator.

SSR-Encoder is a model generalizable encoder, which is able to guide any customized diffusion models for single subject-driven image generation (top branch) or multiple subject-driven image generation from different images (middle branch) based on the image representation selected by the text query or mask query without any additional test-time finetuning. Furthermore, SSR-Encoder can also be applied for the controllable generation with additional control (bottom branch).
Carnegie Mellon published a rather interesting tutorial “Neural theorem proving” combines neural language models with formal proof assistants.
This tutorial introduces two research threads in neural theorem proving via interactive Jupyter notebooks.
LabML is an open source model monitoring tool that supports both desktop and mobile options.
Monitor running experiments from mobile phone or laptop
Monitor hardware usage on any computer with a single command
Integrate with just 2 lines of code (see examples below)
Keeps track of experiments including infomation like git commit, configurations and hyper-parameters
API for custom visualizations
Pretty logs of training progress
Open source!