

Pinterest introduces diversity in multi-stage ranking through DPP, Bucketized ANN, Overfetch and Rerank
Lyft to Detect anomalies with unsupervised learning, there is a new language in town called Mojo!

Articles
Pinterest wrote an excellent post in recommender systems on how they introduce diversity in their recommendations stack. They examine various strategies in different parts of the multistage ranking system and introduce different methods based on the constraints of different stages.
For ranking, they talk about two approaches; 1) Round Robin and 2) DPP(Determinantal Point Processes); specifically improving the skin tone diversity of items that they recommend.
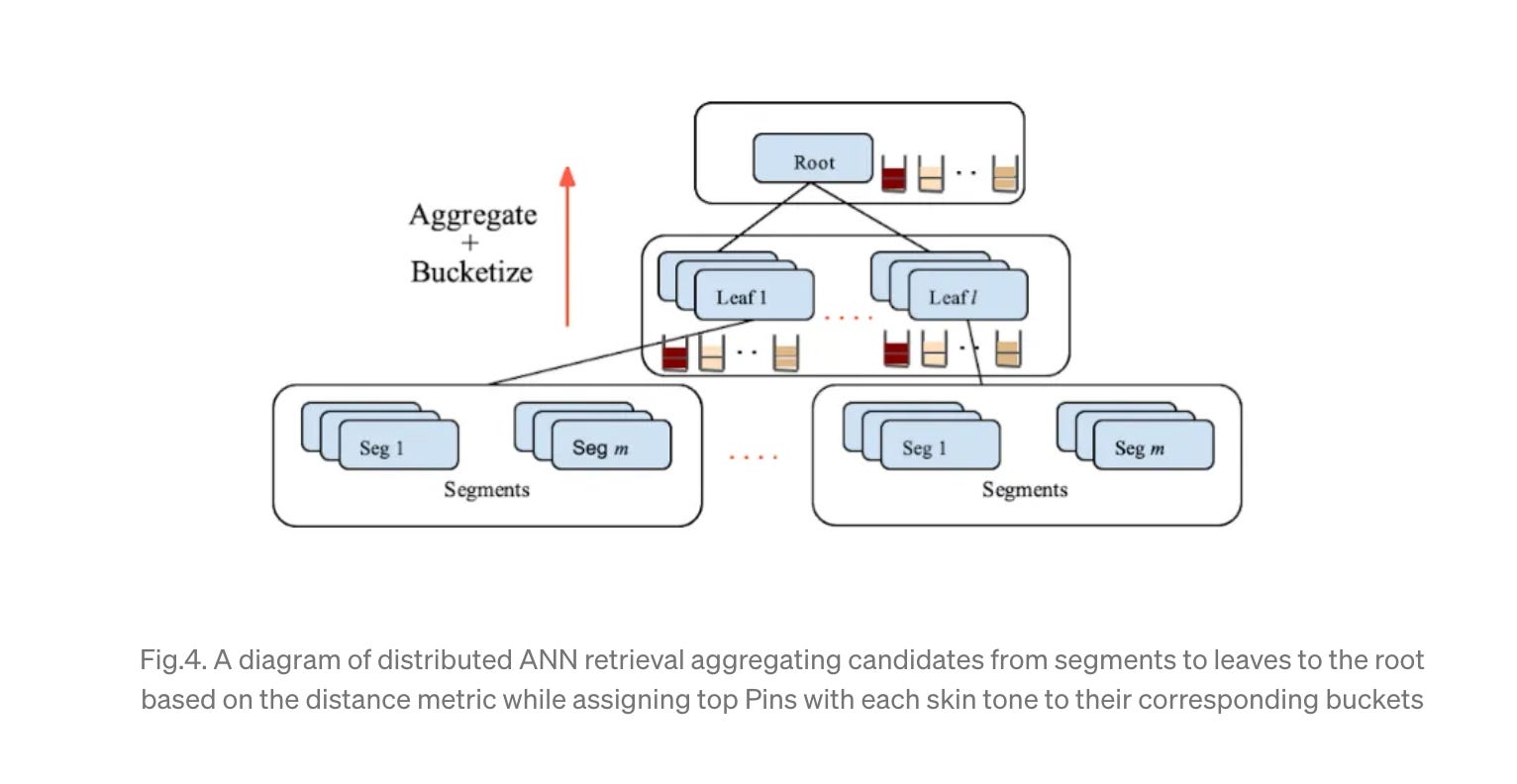
For retrieval, they also talk about two approaches; 1) Overfetch and ReRank at retrieval and 2) Bucketized ANN(Approximate Nearest Neighbor) retrieval.

I highly recommend this post if you have issues around repetitiveness in your recommender/search system as well as how to introduce different utility function outside of engagement for your search/recommender system as these mechanisms can be used for different types of utility functions as well.
Lyft wrote about their efforts to detect anomalies in time-series signals in this following blog post. They adopted using statsforecast due to performance reasons over GreyKite and Prophet.

They have used AutoARIMA algorithm within Statsforecast to measure the accuracy of the predictions. They used this prediction algorithm’s confidence intervals to detect “anomalies”, an example is below:

This is nice as they do not have to build a separate anomaly detection algorithm separately.
Google built a new system called DIDACT(Dynamic Integrated Developer ACTivity), that trains a LLM for all of the software development activities.
DIDACT utilizes interactions among engineers and tools to power ML models that assist Google developers, by suggesting or enhancing actions developers take — in context — while pursuing their software-engineering tasks. To do that, they have defined a number of tasks about individual developer activities: repairing a broken build, predicting a code-review comment, addressing a code-review comment, renaming a variable, editing a file, etc. They use a common formalism for each activity: it takes some State (a code file), some Intent (annotations specific to the activity, such as code-review comments or compiler errors), and produces an Action (the operation taken to address the task). This Action is like a mini programming language, and can be extended for newly added activities. It covers things like editing, adding comments, renaming variables, marking up code with errors, etc.
These systems are very interesting as they can have a very quality label and feedback is human feedback which can be used for a variety of different reinforcement learning applications. Also, it allows you to break-down the engagement and intermediate labeling strategies well if you have a very good tooling to capture variety of activities(time spent, language, and other types of metadata) that are hard to capture otherwise in real world.
Libraries
This repository includes datasets written by language models, used in their paper on "Discovering Language Model Behaviors with Model-Written Evaluations."
They intend the datasets to be useful to:
Those who are interested in understanding the quality and properties of model-generated data
Those who wish to use their datasets to evaluate other models for the behaviors they examined in their work (e.g., related to model persona, sycophancy, advanced AI risks, and gender bias)
The evaluations were generated to be asked to dialogue agents (e.g., a model finetuned explicitly respond to a user's utterances, or a pretrained language model prompted to behave like a dialogue agent). However, it is possible to adapt the data to test other kinds of models as well.
They describe each of their collections of datasets below:
persona/: Datasets testing models for various aspects of their behavior related to their stated political and religious views, personality, moral beliefs, and desire to pursue potentially dangerous goals (e.g., self-preservation or power-seeking).sycophancy/: Datasets testing models for whether or not they repeat back a user's view to various questions (in philosophy, NLP research, and politics)advanced-ai-risk/: Datasets testing models for various behaviors related to catastrophic risks from advanced AI systems (e.g., ). These datasets were generated in a few-shot manner. They also include human-written datasets collected by Surge AI for reference and comparison to their generated datasets.winogender/: Their larger, model-generated version of the Winogender Dataset (Rudinger et al., 2018). They also include the names of occupation titles that they generated, to create the dataset (alongside occupation gender statistics from the Bureau of Labor Statistics)
This repository contains example code on how to combine zero- and few-shot learning with a small annotation effort to obtain a high-quality dataset with maximum efficiency. Specifically, the repository uses large language models available from OpenAI to provide with an initial set of predictions, then spin up a Prodigy instance on our local machine to go through these predictions and curate them. This allows to obtain a gold-standard dataset pretty quickly, and train a smaller, supervised model that fits our exact needs and use-case.
This repository contains examples and best practices for building recommendation systems, provided as Jupyter notebooks. The examples detail our learnings on five key tasks:
Prepare Data: Preparing and loading data for each recommender algorithm
Model: Building models using various classical and deep learning recommender algorithms such as Alternating Least Squares (ALS) or eXtreme Deep Factorization Machines (xDeepFM).
Evaluate: Evaluating algorithms with offline metrics
Model Select and Optimize: Tuning and optimizing hyperparameters for recommender models
Operationalize: Operationalizing models in a production environment on Azure
Surprise is a Python scikit for building and analyzing recommender systems that deal with explicit rating data.
Surprise was designed with the following purposes in mind:
Give users perfect control over their experiments. To this end, a strong emphasis is laid on documentation, which they have tried to make as clear and precise as possible by pointing out every detail of the algorithms.
Alleviate the pain of Dataset handling. Users can use both built-in datasets (Movielens, Jester), and their own custom datasets.
Provide various ready-to-use prediction algorithms such as baseline algorithms, neighborhood methods, matrix factorization-based ( SVD, PMF, SVD++, NMF), and many others. Also, various similarity measures (cosine, MSD, pearson...) are built-in.
Make it easy to implement new algorithm ideas.
Provide tools to evaluate, analyse and compare the algorithms' performance. Cross-validation procedures can be run very easily using powerful CV iterators (inspired by scikit-learn excellent tools), as well as exhaustive search over a set of parameters.
PrimeQA is a public open source repository that enables researchers and developers to train state-of-the-art models for question answering (QA). By using PrimeQA, a researcher can replicate the experiments outlined in a paper published in the latest NLP conference while also enjoying the capability to download pre-trained models (from an online repository) and run them on their own custom data. PrimeQA is built on top of the Transformers toolkit and uses datasets and models that are directly downloadable.
The models within PrimeQA supports End-to-end Question Answering. PrimeQA answers questions via
Information Retrieval: Retrieving documents and passages using both traditional (e.g. BM25) and neural (e.g. ColBERT) models
Multilingual Machine Reading Comprehension: Extract and/ or generate answers given the source document or passage.
Multilingual Question Generation: Supports generation of questions for effective domain adaptation over tables and multilingual text.
Retrieval Augmented Generation: Generate answers using the GPT-3/ChatGPT pretrained models, conditioned on retrieved passages.
Videos
I recommend everyone to watch the following interview from Chris Lattner:
It is a bit of long video, but worth of your time especially if you are interested in programming languages and deep learning. He talks about the landscape of deep learning, Python, why they are coming up a new language that is superset of Python called Mojo.
Although I am skeptical about the language and its adoption over the short/medium term, I can foresee that a language that can make it easy to write middle layer(HW: GPU and model software stack: PyTorch) for different types of HW(NVIDIA GPU, AMD, and other custom chips like Amazon Inferentia) could be useful to improve engineering experience.
The lowering of the models into different HW is a big problem and there are a number of companies that want to build vertically integrated stack which makes sense for their sell strategy and lock-in their customer base, but I can also foresee a world where a modeling engineer can build this model and a middle layer that is HW aware lowers this model into different types of HW with ease. Mojo can fit into this gap to make the model lowering easy no matter what type of HW that is being used under the hood.