

Pinterest incorporates real-time user actions into their Recommender Systems
Netflix's ML Fact Store, Mozilla open-sources Youtube Video Similarity Model

Articles

Pinterest wrote a very good/lengthy post on how they are incorporating short-term interest and real-time user actions.
Some of the use cases that they are going after:
Model pinners’ short-term interest: PinnerSAGE is trained using thousands of user actions over a long term, so it mostly captures long-term interest. On the other hand, realtime user action sequence models short-term user interest and is complementary to PinnerSAGE embedding.
More responsive: Instead of other static features, realtime signals are able to respond faster. This is helpful, especially for new, casual, and resurrected users who do not have much past engagement.
End-to-end optimization for recommendation model objective: We use a user action sequence feature as a direct input feature to the recommendation model and optimize directly for model objectives. Unlike PinnerSAGE, we can attend the pin candidate features with each individual sequence action for more flexibility.
They adopt a version of a Transformer architecture in the following that incorporates both long-term and short-term interest in their recommendation engine.

They did also an extensive study for various architectures and here is the comparison:

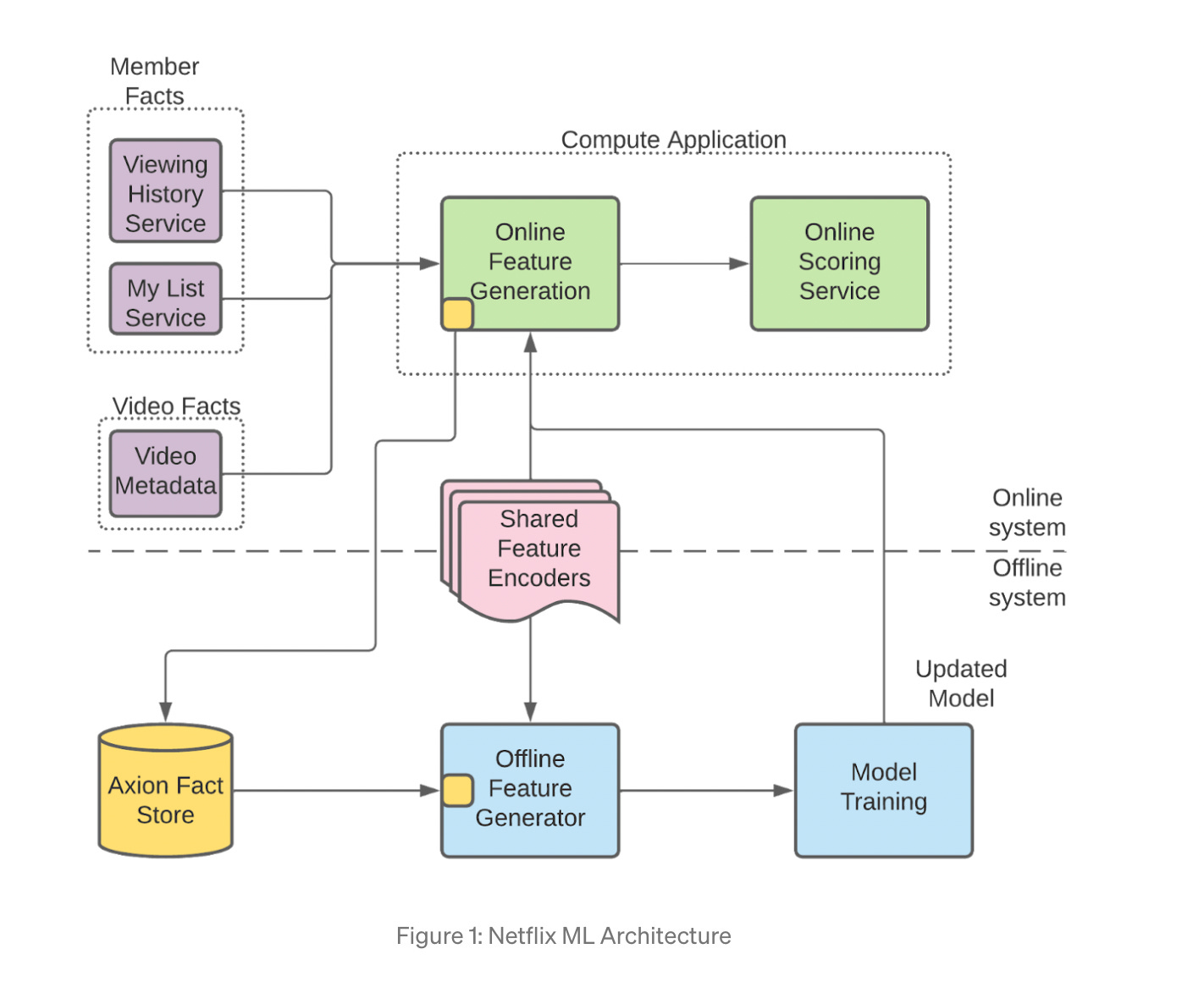
Netflix wrote about their ML Fact Store Axion in this blog post.
They built fact store in order to allow experimentation in the feature logging:
An alternative to feature logging is to regenerate the features with updated feature encoders. If we can access the historical facts, we can regenerate the features using updated feature encoders. Regeneration takes hours compared to weeks taken by the feature logging. Thus, we decided to go this route and started storing facts to reduce the time it takes to run an experiment with new or modified features.
The terminology dissects this blog post in various components with different responsibilities:
Fact: A fact is data about our members or videos. An example of data about members is the video they had watched or added to their My List. An example of video data is video metadata, like the length of a video. Time is a critical component of Axion — When we talk about facts, we talk about facts at a moment in time. These facts are managed and made available by services like viewing history or video metadata services outside of Axion.
Compute application: These applications generate recommendations for our members. They fetch facts from respective data services, run feature encoders to generate features and score the ML models to eventually generate recommendations.
Offline feature generator: We regenerate the values of the features that were generated for inferencing in the compute application. Offline Feature Generator is a spark application that enables on-demand generation of features using new, existing, or updated feature encoders.
Shared feature encoders: Feature encoders are shared between compute applications and offline feature generators. We make sure there is no training/serving skew by using the same data and the code for online and offline feature generation.

Zilliz wrote a good overview article on the vector databases and cover various different approaches in the following article.
Quantization-based indexes
Quantization-based indexes work by dividing a large set of points into a desired number of clusters and ensuring that the sum of distances between points and their centroids is the smallest minimum. The centroid is calculated by taking arithmetic average of all points in the cluster.
Graph-based indexes
Graphs, per se, contains nearest neighbor information. Take the image below as an example, the pink point is our query vector. We need to find its nearest vertex. The entry point is selected on a random basis. Sometimes the entry point could be the first vector inserted into the database
Hash-based indexes
Hash-based indexes use a series of hash functions. The probability of a collision among multiple hash functions represents the similarity of the vectors. Each vector in the database is placed into multiple buckets. During a nearest neighbor search, to have enough number of buckets, the search radius is continuously increased. Then the distance between the query vector and vectors in the buckets are further calculated.
Tree-based indexes
Most of the tree-based indexes divide the entire high-dimensional space from top to bottom with specific rules. For example, KD-tree selects the dimension with the largest variance and divides the vectors in the space into two subspaces based on the median on that dimension.
The following two approaches are the most popular ones:
HNSW: A high-speed, high-recall index
HNSW (Hierarchical Navigable Small World Graph) is a graph-based indexing algorithm that incrementally builds a multi-layer structure consisting of a hierarchical set of proximity graphs (layers) for nested subsets of the stored elements.
ANNOY: A tree-based index on low-dimensional vectors
ANNOY (Approximate Nearest Neighbors Oh Yeah) is an index that uses a hyperplane to divide a high-dimensional space into multiple subspaces, and then stores them in a tree structure.
E2LSH: Highly efficient index for extremely large volumes of data.
E2LSH constructs LSH functions based on p-stable distributions. E2LSH uses a set of LSH functions to increase the conflict probability of similar vectors and reduce the conflict probability of dissimilar vectors.The LSH function partitions an object into a bucket by first projecting object along the random line, then giving the projection a random shift, and finally using the floor function to locate the interval of width w in which the shifted projection falls.
The following papers go to much more detail for these indices:
“Encyclopedia of database systems”, Ling Liu and M. Tamer Özsu.
“A Survey of Product Quantization”, Yusuke Matsui, Yusuke Uchida, Herve Jegou, Shinichi Satoh.
“Milvus: A Purpose-Built Vector Data Management System”, Jianguo Wang, Xiaomeng Yi, Rentong Guo et al.
“Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs”, Yu. A. Malkov, D. A. Yashunin.

Mozilla open-sourced their Youtube video similarity model in the following post. The model and details are available in HuggingFace.
As illustrated above, the unified model replaces the bi-encoders from the first model with a set of cross-encoders for determining the similarity of each of the text components of the videos, which are then connected directly, along with a channel-equality signal into a single linear layer with a sigmoid output. This final layer is equivalent to the logistic regression from their first model.
The motivation for the unified model was twofold:
Cross-encoders tend to have better accuracy than bi-encoders, so they wanted to switch from bi-encoders to cross-encoders
They wanted to individually fine-tune the cross-encoders, as video titles, descriptions, and transcripts tend to each have different sorts of text and are all probably quite different from the sort of text that most language models are trained on.
Fine-tuning is most effective with labeled data. If they have a set of text pairs that are labeled as similar or dissimilar, they can use them for fine-tuning. In their case, They have labeled data, but they have labeled video pairs, not labeled text pairs. They may know that two videos are similar, but that does not necessarily mean that the titles of those two videos are similar. This means that they can’t directly fine-tune a cross-encoder. But with their unified model, they can train the whole model based on the labeled video pairs and the training process will fine-tune the cross-encoder for each text type simultaneously as part of the larger model. That’s why they call the whole model the “unified model”. The more details on the labeling and other details can be found in the other post.

Pinterest wrote about their embedding based retrieval system, called Manas in detail in terms of system design and architecture design for the following blog post. Embedding-based retrieval is a core center piece of Pinterest’s recommendations engine at Pinterest. They support a myriad of use cases, from retrieval based on content similarity to learned retrieval. It’s powered by our in-house search engine — Manas — which provides Approximate Nearest Neighbor (ANN) search as a service, primarily using Hierarchical Navigable Small World graphs (HNSW).
Libraries

To help users enhance low quality videos in real time, on edge equipment and with limited computing power, researchers from Microsoft Research Asia launched a set of intelligent image/video enhancement tools called DaVinci. This toolkit aims to solve the pain points of existing video enhancement and restoration tools, give full play to the advantages of AI technology and lower the threshold for users to process video footage.
The targeted features of the DaVinci toolkit include low-level image and video enhancement tasks, real-time image and video filters, and visual quality enhancement such as super-resolution, denoising, and video frame interpolation. The backend technology of the DaVinci toolkit is supported by the industry-leading large-scale, low-level vision pre-training technology, supplemented by a large amount of data training. To maximize the robustness of the model, researchers use four million publicly available images and video data, with contents covering landscapes, buildings, people, and so on.
To ensure an adequate amount of training data and rich data types, researchers synthesized data with various degradations, so that the entire model training could cover more actual user application scenarios. The DaVinci toolkit has been packaged and released on GitHub.
Daft is a fast and scalable Python dataframe for Complex Data and Machine Learning workloads.
Aim is an open-source, self-hosted ML experiment tracking tool. It's good at tracking lots (1000s) of training runs and it allows you to compare them with a performant and beautiful UI.
Embetter implements scikit-learn compatible embeddings for computer vision and text. It should make it very easy to quickly build proof of concepts using scikit-learn pipelines and, in particular, should help with bulk labelling. It's a also meant to play nice with bulk and scikit-partial.





