

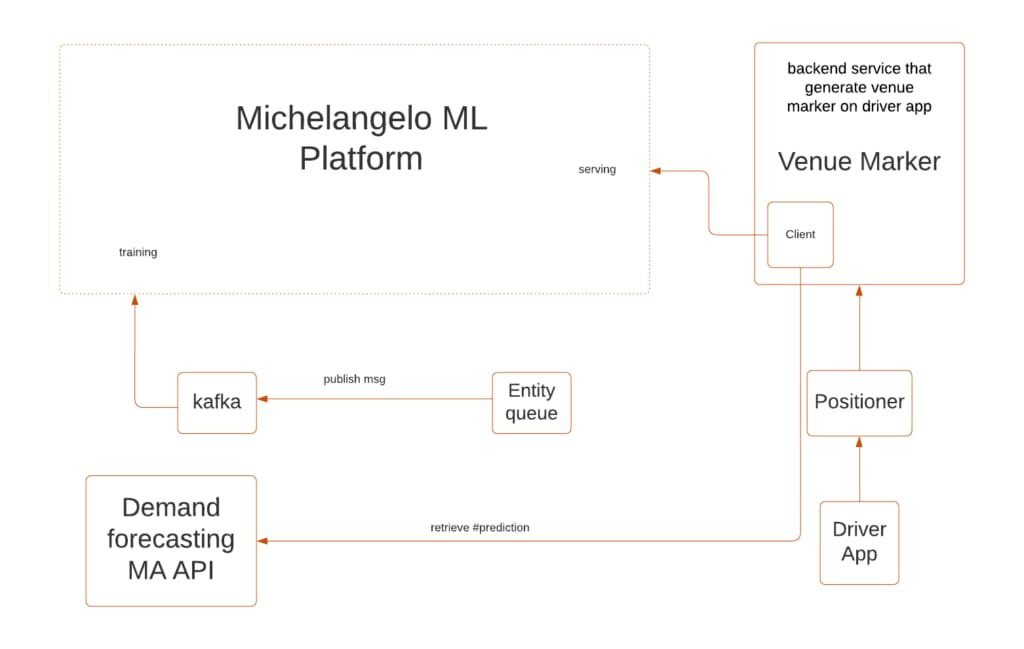
Pinterest builds User Understanding Infrastructure
Uber talks about their forecasting platform, Google introduces no code ML development for media applications called Visual blocks

Articles

Pinterest publishes their user understanding infrastructure to power a variety of recommendations, search products in their platform. Their platform has the following capabilities:
Real-time: on average < 2 seconds latency from a user’s latest action to the service response
Flexibility: data can be fetched and reused by a mix-and-use pattern to enable faster iterations for ML engineers focusing on quick development time
Platform: serve all different needs and requests with a uniform data API layer
Cost Efficient: improve infra shareability and reusability, and avoid duplications in storage or computation wherever possible
And their KV store as it is commonly used to store user interactions, their requirements were:
Allows inserts. We need each dataset to store the last N events for a user. However, when we process a new event for a user, we do not want to read the existing N events, update them, and then write them all back to the respective dataset. This is inefficient (processing each event takes O(N) time instead of O(1)), and it can lead to concurrent modification issues if two hosts process two different events for the same user at the same time. Therefore, our most important requirement for our storage layer was to be able to handle inserts.
Handles out-of-order inserts. We want our datasets to store the events for each user ordered in reverse chronological order (newest events first), because then we can fetch them in the most efficient way. However, we cannot guarantee the order in which our real-time indexing job will process the events, and we do not want to introduce an artificial processing delay (to order the events), because we want an infrastructure that allows us to immediately react to any user action. Therefore, it was imperative that the storage layer is able to handle out-of-order inserts.
Handles duplicate values. Delegating the deduplication responsibility to the storage layer has allowed us to run our real-time indexing job with “at least once” semantic, which has greatly reduced its complexity and the number of failure scenarios we needed to address.
Uber wrote how they respond to demand in the airports and forecast ETR(estimating the time to request) in the following blog post. They actually go in detail how they model the time of arrivals and the supply around airports to guide drivers on whether they will have a less wait time or not. I can imagine that they went into detail of this due to a good portion of their revenue and demand is coming from the airports. They do this through two stage approach; (1) Supply and (2) Demand:
They estimate the “true” position of the last person in the FIFO queue, accounting for queue dynamics (e.g., abandonment, joining of priority pass holders, etc.). They refer to this as our “supply” model.
They estimate the queue consumption rate in 15 minute intervals, up to one hour into the future. They refer to this as our “demand” model.
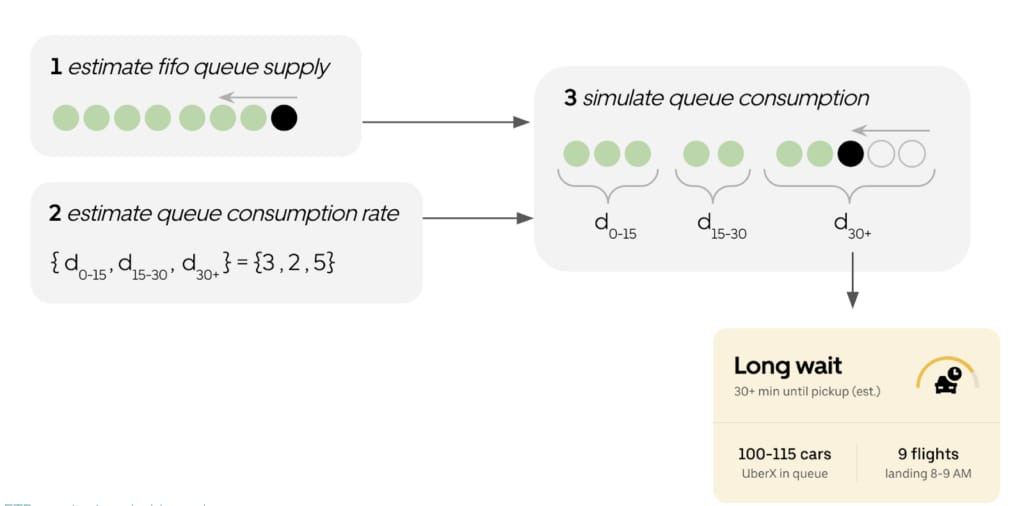
Simulation of consumption of queue up to drivers estimated position becomes an easy simple algorithm and results in wait time classification.

Google built a no-code end to end ML based framework called Visual blocks and published a post on this.

They describe a visual programming platform for rapid and iterative development of end-to-end ML-based multimedia applications. Visual Blocks for ML, formerly called Rapsai, provides a no-code graph building experience through its node-graph editor. Users can create and connect different components (nodes) to rapidly build an ML pipeline, and see the results in real-time without writing any code. They demonstrate how this platform enables a better model evaluation experience through interactive characterization and visualization of ML model performance and interactive data augmentation and comparison. They have released the Visual Blocks for ML framework, along with a demo and Colab examples.
Libraries
Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, autonomously develops and manages businesses to increase net worth. As one of the first examples of GPT-4 running fully autonomously, Auto-GPT pushes the boundaries of what is possible with AI.
Padl is a pipeline builder for PyTorch.
can be used with all of the great PyTorch functionality you’re used to for writing layers.
allows users to build pre-processing, forward passes, loss functions and post-processing into the pipeline.
models may have arbitrary topologies and make use of arbitrary packages from the python ecosystem.
allows for converting standard functions to PADL components using a single keyword
transform.
Bark is a transformer-based text-to-audio model created by Suno. Bark can generate highly realistic, multilingual speech as well as other audio - including music, background noise and simple sound effects. The model can also produce nonverbal communications like laughing, sighing and crying. To support the research community, we are providing access to pretrained model checkpoints ready for inference.
Whisper-Jax contains optimised JAX code for OpenAI's Whisper Model, largely built on the 🤗 Hugging Face Transformers Whisper implementation. Compared to OpenAI's PyTorch code, Whisper JAX runs over 70x faster, making it the fastest Whisper implementation available.
Track-Anything is a flexible and interactive tool for video object tracking and segmentation. It is developed upon Segment Anything, can specify anything to track and segment via user clicks only. During tracking, users can flexibly change the objects they wanna track or correct the region of interest if there are any ambiguities. These characteristics enable Track-Anything to be suitable for:
Video object tracking and segmentation with shot changes.
Visualized development and data annnotation for video object tracking and segmentation.
Object-centric downstream video tasks, such as video inpainting and editing.
The Python scientific visualisation landscape is huge. It is composed of a myriad of tools, ranging from the most versatile and widely used down to the more specialised and confidential. Some of these tools are community based while others are developed by companies. Some are made specifically for the web, others are for the desktop only, some deal with 3D and large data, while others target flawless 2D rendering. In this landscape, Matplotlib has a very special place. It is a versatile and powerful library that allows you to design very high quality figures, suitable for scientific publishing. It also offers a simple and intuitive interface as well as an object oriented architecture that allows you to tweak anything within a figure. Finally, it can be used as a regular graphic library in order to design non‐scientific figures. This book is organized into four parts. The first part considers the fundamental principles of the Matplotlib library.

Semantic Kernel (SK) is a lightweight SDK enabling integration of AI Large Language Models (LLMs) with conventional programming languages. The SK extensible programming model combines natural language semantic functions, traditional code native functions, and embeddings-based memory unlocking new potential and adding value to applications with AI.
Semantic Kernel supports and encapsulates several design patterns from the latest in AI research, such that developers can infuse their applications with complex skills like prompt chaining, recursive reasoning, summarization, zero/few-shot learning, contextual memory, long-term memory, embeddings, semantic indexing, planning, retrieval-augmented generation and accessing external knowledge stores as well as your own data.
A skill refers to a domain of expertise made available to the kernel as a single function, or as a group of functions related to the skill. The design of SK skills has prioritized maximum flexibility for the developer to be both lightweight and extensible.

A function is the basic building block for a skill. A function can be expressed as either:
an LLM AI prompt — also called a "semantic" function
native computer code -- also called a "native" function
When using native computer code, it's also possible to invoke an LLM AI prompt — which means that there can be functions that are hybrid LLM AI × native code as well.
Functions can be connected end-to-end, or "chained together," to create more powerful capabilities. When they are represented as pure LLM AI prompts in semantic functions, the word "function" and "prompt" can be used interchangeably.
The ChatGPT Retrieval Plugin repository provides a flexible solution for semantic search and retrieval of personal or organizational documents using natural language queries.
Videos
A really good video for advantages and disadvantages of recent AI developments from Yen Choi; she talks about why recent developments in ChatGPT and more broadly in LLMs make them so powerful, yet they can fail very basic(she calls common sense mistakes):