Personalizing Heart Rate Prediction
Do Machine Learning Models Memorize or Generalize?

Articles

Apple wrote a blog post that presents a hybrid machine learning approach for personalizing heart rate prediction during exercise by combining a physiological model based on ordinary differential equations (ODEs) with neural networks and representation learning. The key idea is to learn low-dimensional personalized representations that capture an individual's unique heart rate dynamics in response to exercise. The physiological model is based on the Tan and Ingpen ODE model for heart rate dynamics during exercise, which models heart rate as a function of an exogenous drive signal representing exercise intensity. The ODE has several parameters (A, B, α, β) that control the rise and decay rates of heart rate, as well as a drive function f(I) and minimum/maximum heart rate bounds. Instead of directly learning these ODE parameters for each individual, which is computationally expensive, the authors assume each person's "health state" can be represented by a low-dimensional latent vector z. The ODE parameters are then modeled as neural networks that take z as input, e.g. α(z), f(z, I). This allows sharing of parameters across the population while still personalizing to each individual. The model is trained on data from the Apple Heart and Movement Study, which includes workout data from over 100,000 participants wearing Apple Watches. The input is a sequence of past workouts for an individual, and the goal is to predict their future heart rate trajectory during a new workout. The model architecture has mainly three components:
An encoder LSTM that takes the past workout sequence and outputs the personalized latent representation z.
A neural ODE solver that takes z and the future exercise intensity I(t) as input, and solves the personalized ODE to predict the heart rate trajectory HR(t).
A decoder LSTM that maps the solved ODE trajectory to a final heart rate prediction sequence.
The model is trained end-to-end by minimizing the mean absolute percentage error between predicted and true heart rates across all workouts in the dataset. Results show the hybrid model significantly outperforms baselines like sequence-to-sequence models and heuristic approaches in predicting personalized heart rate trajectories, with a median absolute percentage error of around 5%. Performance improves after observing the first few "warm-up" minutes of a workout.Interestingly, the learned personalized representations z correlate well with metrics of cardiorespiratory fitness like VO2max, even though the model was only trained to predict heart rates. This suggests z captures meaningful health information about each individual.The authors also extend the model to incorporate environmental factors like weather, by augmenting the ODE with additional terms modeling the effects of temperature, humidity, etc. on heart rate dynamics. This improves prediction accuracy further.

Google wrote a rather interesting blog post titled"Do Machine Learning Models Memorize or Generalize?" explores the concept of "grokking" in machine learning models, which refers to the phenomenon where a model initially memorizes the training data before transitioning to generalization.

Grokking is a contingent phenomenon that occurs when certain conditions are met, such as appropriate model size, weight decay, data size, and other hyperparameters. It involves two distinct phases:
Memorization Phase: In the early stages of training, the model memorizes or overfits the training data, leading to high training accuracy but poor generalization to unseen data.
Generalization Phase: As training progresses, the model transitions from memorization to generalization, where it learns to capture the underlying patterns and relationships in the data, improving its performance on unseen data.
There are several factors that can influence the occurrence and characteristics of grokking:
Weight Decay: Weight decay is a regularization technique that helps prevent overfitting. With too little weight decay, the model may remain stuck in the memorization phase. Increasing weight decay can push the model towards generalization after the memorization phase. However, excessive weight decay may cause the model to generalize prematurely without fully leveraging the training data.
Model Size: Grokking is more likely to occur in models of appropriate size, neither too small nor too large. Smaller models may struggle to capture complex patterns, while larger models may generalize more easily without exhibiting the memorization phase.
Data Size: The amount of training data can also impact grokking. With limited data, the model may memorize the entire dataset without transitioning to generalization. Increasing the data size can facilitate the generalization phase.
The blog post discusses also techniques for visualizing and understanding the grokking phenomenon in small models:
Connectome Visualization: For small models (e.g., with 67 parameters), it is feasible to extract and visualize the complete connectome, or the network of connections between neurons, synapse-by-synapse. This can provide insights into the model's internal representations and how they evolve during the memorization and generalization phases.
Loss Curve Analysis: Analyzing the training loss curve can potentially reveal patterns indicative of grokking. Certain characteristics in the loss curve may help predict when a model is transitioning from memorization to generalization.
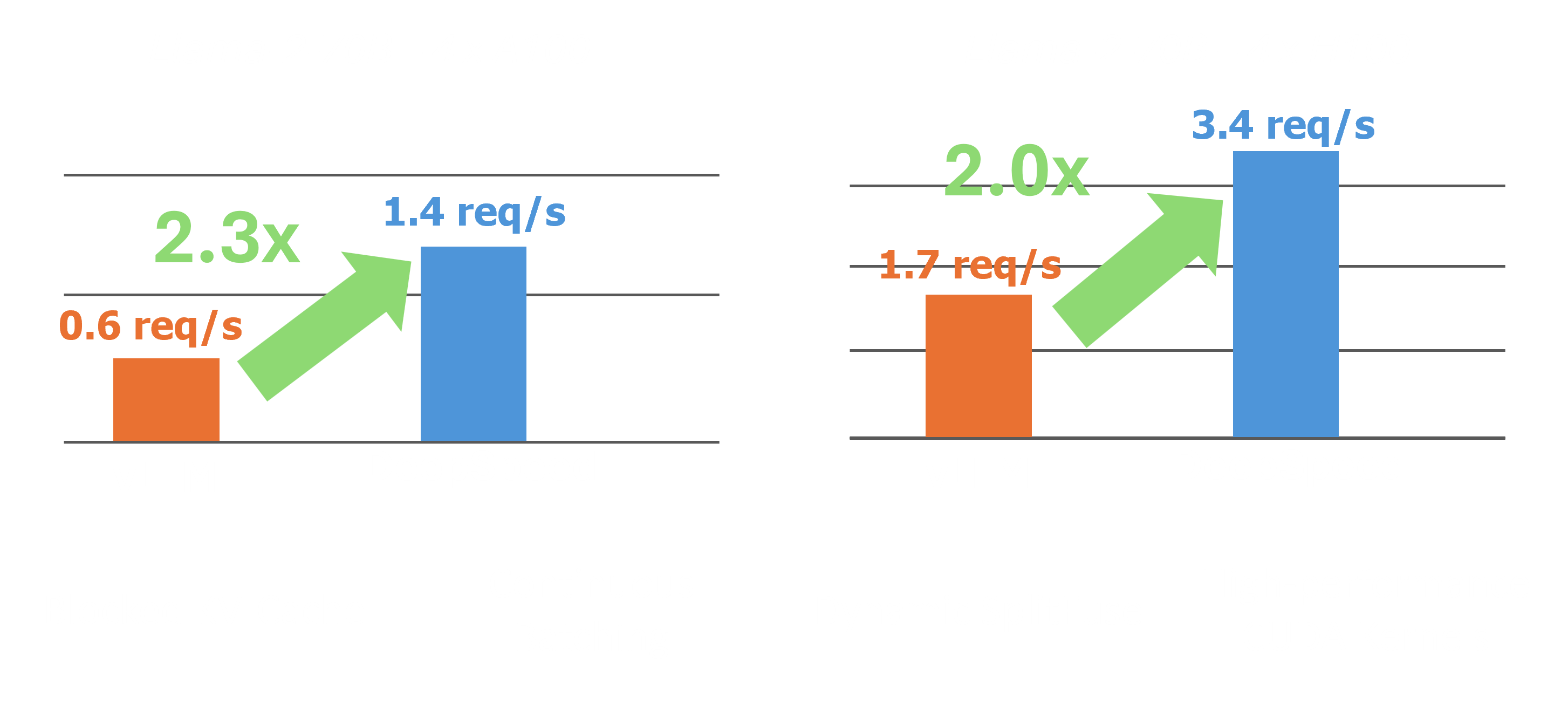
DeepSpeed-FastGen is a system developed by Microsoft to revolutionize the deployment and serving of large language models (LLMs). It combines two powerful components: DeepSpeed-MII and DeepSpeed-Inference, leveraging a novel technique called Dynamic SplitFuse. This innovative approach enables DeepSpeed-FastGen to achieve up to 2.3 times higher effective throughput compared to existing systems like vLLM, making it a game-changer in the field of natural language processing (NLP).

Dynamic SplitFuse technique, a token composition strategy that allows for efficient and responsive text generation. This technique enables DeepSpeed-FastGen to run at a consistent forward size by intelligently combining partial tokens from prompts with the generated text.
The Dynamic SplitFuse technique operates by splitting the input prompt into smaller chunks or tokens. These tokens are then fused or composed with the generated text during the inference process. This approach ensures that the model can process a consistent number of tokens at each step, regardless of the length of the input prompt or the generated text.By dynamically adjusting the composition of tokens, DeepSpeed-FastGen can maintain a consistent forward size, resulting in improved responsiveness, efficiency, and lower variance. This translates into lower latency and higher throughput for streaming text generation, benefiting all clients interacting with the system.
DeepSpeed-FastGen's performance advantages over existing systems like vLLM are significant. It outperforms vLLM in both throughput and latency, offering either equivalent latency with greater throughput or more responsive latency at the same throughput level.
In terms of throughput, DeepSpeed-FastGen demonstrates impressive gains. For example, when running the Llama-2 70B model on 4 A100x80GB GPUs, DeepSpeed-FastGen achieves up to 2 times higher throughput compared to vLLM. This means that DeepSpeed-FastGen can process a larger volume of text generation requests in a given time, making it more efficient and scalable for high-demand applications.
Deployment Options
DeepSpeed-FastGen offers two deployment options to cater to different use cases:
Interactive Non-Persistent Pipeline: This option is suitable for interactive scenarios where users can engage with the system in real-time. The pipeline is non-persistent, meaning that it is created and destroyed for each user interaction, ensuring efficient resource utilization.
Persistent Serving Deployment: For applications that require continuous availability and low-latency responses, DeepSpeed-FastGen provides a persistent serving deployment option. In this mode, the system remains active and ready to serve requests, minimizing startup overhead and ensuring consistent performance.
Performance Optimization Techniques
To achieve its impressive performance gains, DeepSpeed-FastGen employs several optimization techniques beyond the Dynamic SplitFuse strategy. These techniques include:
Tensor Parallelism
DeepSpeed-FastGen leverages tensor parallelism, a technique that distributes the computational load across multiple GPUs or accelerators. By splitting the model's tensors and distributing them across multiple devices, DeepSpeed-FastGen can effectively utilize the combined computational power and memory resources of multiple GPUs, enabling efficient processing of large language models.
Efficient Memory Management
Memory management is a critical aspect of deploying and serving large language models. DeepSpeed-FastGen incorporates efficient memory management strategies to optimize memory usage and reduce the overall memory footprint. This includes techniques such as activation checkpointing, which trades off computation for memory savings, and offloading, which moves tensors to CPU or disk when not in use.
Optimized Kernels and Operators
DeepSpeed-FastGen takes advantage of optimized kernels and operators specifically designed for efficient tensor operations on GPUs. These optimizations leverage hardware-specific features and instructions, enabling faster computations and reducing the overall inference time.
Datasets
The OpenDAC project is a collaborative research project between Fundamental AI Research (FAIR) at Meta and Georgia Tech, aimed at significantly reducing the cost of Direct Air Capture (DAC).
Direct Air Capture (DAC) involves directly capturing carbon dioxide from the atmosphere and has been widely recognized as a crucial tool in combating climate change. Despite its potential, the broad implementation of DAC has been impeded by high capture costs. Central to overcoming this hurdle is the discovery of novel sorbents — materials that pull carbon dioxide from the air. Discovering new sorbents holds the key to reducing capture costs and scaling DAC to meaningfully impact global carbon emissions.
The DAC space is growing rapidly with many companies entering the space. To engage the broader research community as well as the budding DAC industry, they have released the OpenDAC 2023 (ODAC23) dataset to train ML models. ODAC23 contains nearly 40M DFT calculations from 170K DFT relaxations involving Metal Organic Frameworks (MOFs) with carbon dioxide and water adsorbates. They have also released baseline ML models trained on this dataset.
MS MARCO Web Search is a large-scale information-rich Web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks. It incorporates the largest open web document dataset, ClueWeb22, as our document corpus. ClueWeb22 includes about 10 billion high-quality web pages, sufficiently large to serve as representative web-scale data. It also contains rich information from the web pages, such as visual representation rendered by web browsers, raw HTML structure, clean text, semantic annotations, language and topic tags labeled by industry document understanding systems, etc. MS MARCO Web Search further contains 10 million unique queries from 93 languages with millions of relevant labeled query-document pairs collected from the search log of the Microsoft Bing search engine to serve as the query set.
It offers a retrieval benchmark on 100 million document set with three web retrieval challenge tasks that demands innovations in both machine learning and information retrieval system research domains: embedding model, embedding retrieval, and end-to-end retrieval challenges. The main goal of the leaderboard is to study what retrieval methods work best and what retrieval methods are cost-efficient when a large amount of data is available.
Libraries
🗂️ LlamaIndex 🦙
LlamaIndex is a framework for building context-augmented LLM applications. Context augmentation refers to any use case that applies LLMs on top of your private or domain-specific data. Some popular use cases include the following:
Question-Answering Chatbots (commonly referred to as RAG systems, which stands for "Retrieval-Augmented Generation")
Document Understanding and Extraction
Autonomous Agents that can perform research and take actions
LlamaIndex provides the tools to build any of these above use cases from prototype to production. The tools allow you to both ingest/process this data and implement complex query workflows combining data access with LLM prompting.

StoryDiffusion can create a story by generating consistent images and videos. They use two approaches:
Consistent self-attention for character-consistent image generation over long-range sequences. It is hot-pluggable and compatible with all SD1.5 and SDXL-based image diffusion models. For the current implementation, the user needs to provide at least 3 text prompts for the consistent self-attention module. At least 5 - 6 text prompts for better layout arrangement is recommended.
Motion predictor for long-range video generation, which predicts motion between Condition Images in a compressed image semantic space, achieving larger motion prediction.

The proposed CLLM4Rec is the first recommender system that tightly combines the ID-based paradigm and LLM-based paradigm and leverages the advantages of both worlds.
With the following mutually-regularized pretraining with soft+hard prompting strategy, language modeling can be effectively conducted on recommendation-oriented corpora with heterogenous user/item tokens.

Animals perceive the world to plan their actions and interact with other agents to accomplish complex tasks, demonstrating capabilities that are still unmatched by AI systems. To advance our understanding and reduce the gap between the capabilities of animals and AI systems, Berkeley researchers introduce a dataset of pet egomotion imagery with diverse examples of simultaneous egomotion and multi-agent interaction. Current video datasets separately contain egomotion and interaction examples, but rarely both at the same time. EgoPet offers a radically distinct perspective from existing egocentric datasets of humans or vehicles. They define two in-domain benchmark tasks that capture animal behavior, and a third benchmark to assess the utility of EgoPet as a pretraining resource to robotic quadruped locomotion, showing that models trained from EgoPet outperform those trained from prior datasets. This work provides evidence that today's pets could be a valuable resource for training future AI systems and robotic assistants.
The implementation of the model and dataset are available in here. Dataset separately can be downloaded in here.

LangProp is a framework for generating code using ChatGPT, and evaluate the code performance against a dataset of expected outputs in a supervised/reinforcement learning setting. Usually, ChatGPT generates code which is sensible but fails for some edge cases, and then you need to go back and prompt ChatGPT again with the error. This framework saves you the hassle by automatically feeding in the exceptions back into ChatGPT in a training loop, so that ChatGPT can iteratively improve the code it generates.
Accompanying paper can be found in here.

ocp is the Open Catalyst Project's library of state-of-the-art machine learning algorithms for catalysis. ocp provides training and evaluation code for tasks and models that take arbitrary chemical structures as input to predict energies / forces / positions / stresses, and can be used as a base scaffold for research projects. For an overview of tasks, data, and metrics, please read the documentations and respective papers:

Xmake is a cross-platform build utility based on the Lua scripting language.
Xmake is very lightweight and has no dependencies outside of the standard library.
Uses the
xmake.luafile to maintain project builds with a simple and readable syntax.
Xmake can be used to directly build source code (like with Make or Ninja), or it can generate project source files like CMake or Meson. It also has a built-in package management system to help users integrate C/C++ dependencies.

imgsys is an open source replication attempt for the project Chatbot Arena by lmsys.org. It is a platform for evaluating open source text-guided image generation while also collecting (and open sourcing) extremely valuable preference data.
python-pptx is a Python library for creating, reading, and updating PowerPoint (.pptx) files.
A typical use would be generating a PowerPoint presentation from dynamic content such as a database query, analytics output, or a JSON payload, perhaps in response to an HTTP request and downloading the generated PPTX file in response. It runs on any Python capable platform, including macOS and Linux, and does not require the PowerPoint application to be installed or licensed.
It can also be used to analyze PowerPoint files from a corpus, perhaps to extract search indexing text and images.
In can also be used to simply automate the production of a slide or two that would be tedious to get right by hand, which is how this all got started.python-pptx is a Python library for creating, reading, and updating PowerPoint (.pptx) files.
A typical use would be generating a PowerPoint presentation from dynamic content such as a database query, analytics output, or a JSON payload, perhaps in response to an HTTP request and downloading the generated PPTX file in response. It runs on any Python capable platform, including macOS and Linux, and does not require the PowerPoint application to be installed or licensed.
It can also be used to analyze PowerPoint files from a corpus, perhaps to extract search indexing text and images.
In can also be used to simply automate the production of a slide or two that would be tedious to get right by hand, which is how this all got started.

Codebook Features is a method for training neural networks with a set of learned sparse and discrete hidden states, enabling interpretability and control of the resulting model.
Codebook features work by inserting vector quantization bottlenecks called codebooks into each layer of a neural network. The library provides a range of features to train and interpret codebook models, including by analyzing the activations of codes, searching for codes that activate on a pattern, and performing code interventions to verify the causal effect of a code on the output of a model. Many of these features are also available through an easy-to-use webapp that helps in analyzing and experimenting with the codebook models.
Conferences
Bay Area Robotics Symposium made the 2023 videos available in here.