
Highlight of the week
Google published the paper for Pathways from ML Infra perspective in here. It is a great if you are into heterogeneous computing, asynchronous execution and distributed systems overall. However, there is not much information around the modeling and models that have been deployed to this infrastructure.
My guess is that they first laid out the ML Infra components that support modeling, and they will be doing a follow up to the paper on the models that have been supported and deployed to this ecosystem.
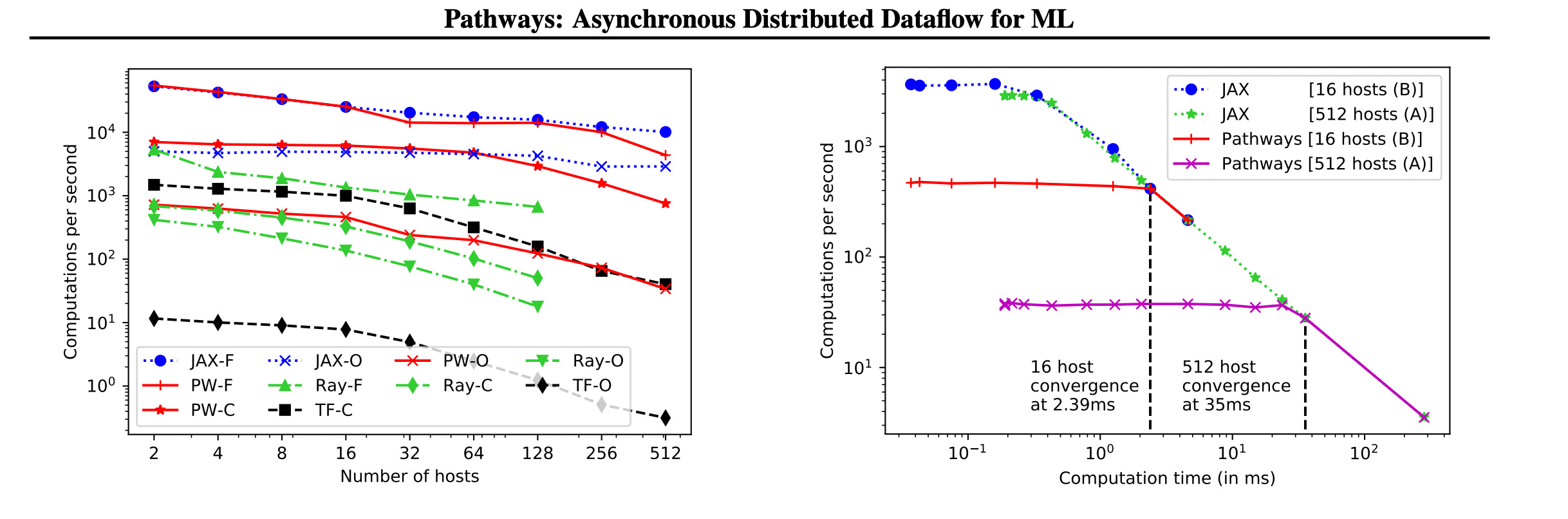
Another interesting thing from the paper that caught my eye is that, some of the benchmarks are now using Jax along with Tensorflow. Jax is becoming more and more important for internal use cases even though it started as research first focus.
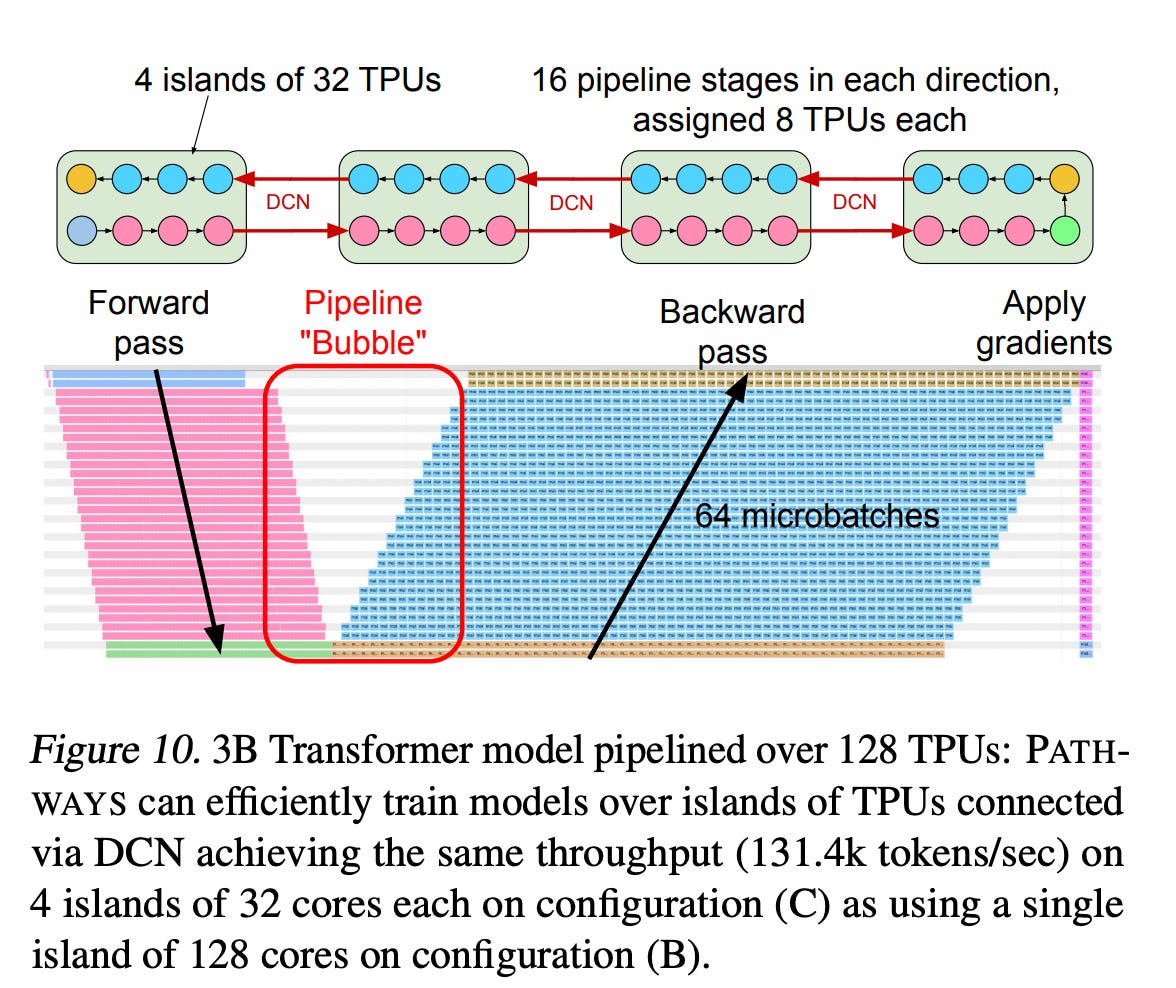
The paper is a very good read in terms of how everything comes together by leveraging a lot of data infrastructure work that has happened over couple of decades now to solve ML based computation problems.
Libraries
PointNet Lightning implements PointNet paper in PyTorch Lightning.
Archai is a platform for Neural Network Search (NAS) that allows you to generate efficient deep networks for your applications. Archai aspires to accelerate NAS research by enabling easy mix and match between different techniques while ensuring reproducibility, self-documented hyper-parameters and fair comparison.
Easy Parallel Library (EPL) is a general and efficient library for distributed model training.
Usability - Users can implement different parallelism strategies with a few lines of annotations, including data parallelism, pipeline parallelism, tensor model parallelism, and their hybrids.
Memory Efficient - EPL provides various memory-saving techniques, including gradient checkpoint, ZERO, CPU Offload, etc. Users are able to train larger models with fewer computing resources.
High Performance - EPL provides an optimized communication library to achieve high scalability and efficiency.
Mephisto makes crowdsourcing easier. We provide a platform for launching, monitoring, and reviewing your crowdsourcing tasks. Tasks made on Mephisto can easily be open sourced as part of other projects. Like the chess-playing automaton we've adopted the name from, Mephisto hides the complexity of projects that need human interaction or input.
Articles

Rishabh Anand wrote a blog post on mathematics for Graph Neural Networks. It represents graphs into matrices first and then explain how a model training can be done to update the weights through back propagation.

How to build a machine learning demo in 2022 outlines various libraries/tools to build a ML based application with minimal UI.

It shows a notebook, full-stack and an app library approach and examines in multiple dimensions above. If you want to build an ML application and do not know where to start, it is a good blog post to start with.
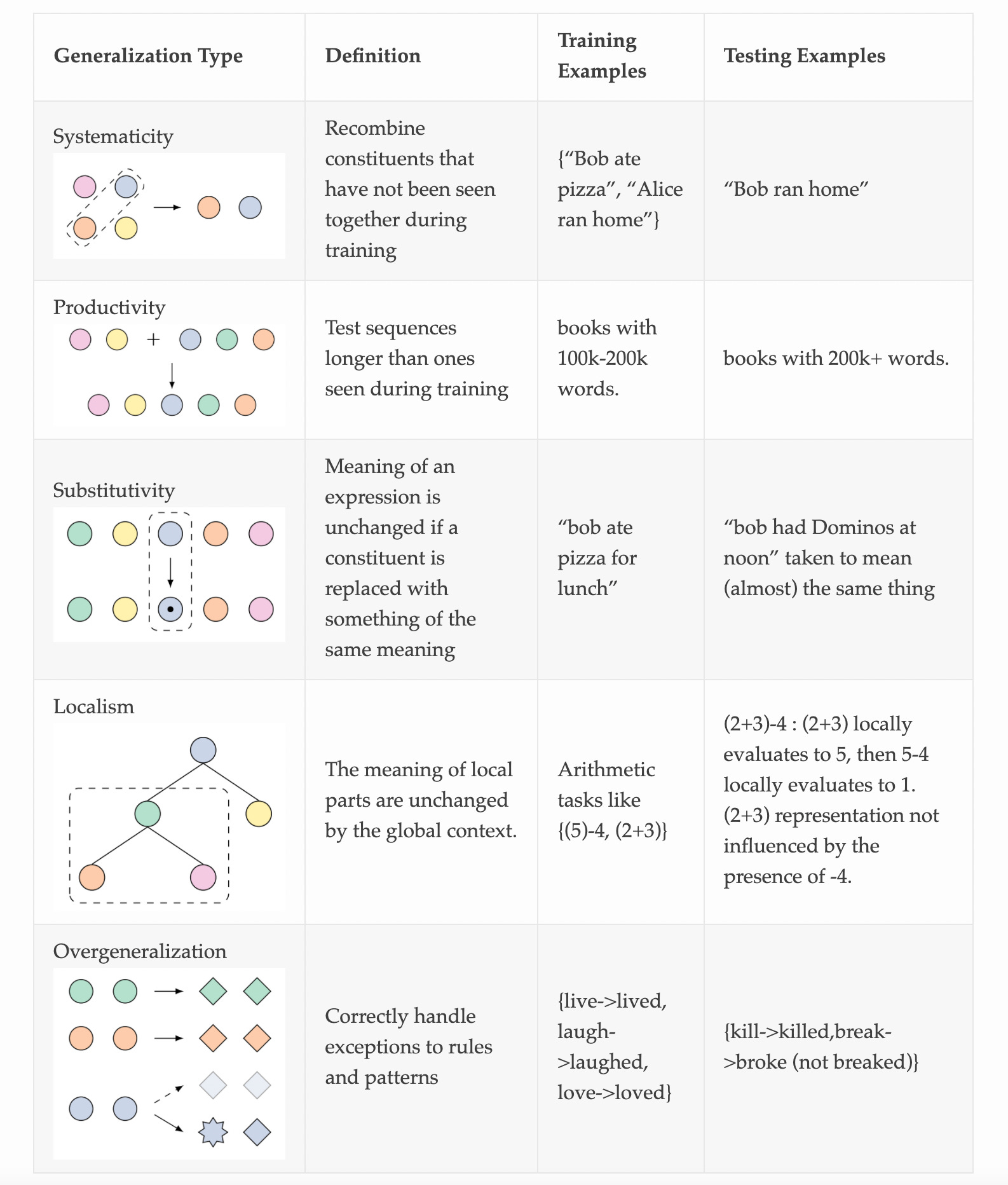
Eric Jang wrote a blog post on generalization and how to think about improving ML models with respect to generalization.
TLDR:
Language Models are far from perfect even when restricted to NLP tasks, and I don’t mean to suggest that they are ready today for solving ML once and for all. Rather, I am optimistic that language models will continue to get better, and with improved linguistic capability comes better generalization in other non-NLP domains.
The structure of language is the structure of generalization.
Formal grammars for language run up against a “semantic uncertainty principle”, so let’s rely on language models to represent language (and therefore, the structure of generalization).
Let’s use large language models to “bolt on generalization” to non-NLP domains. Some preliminary evidence (the Universal Computation Engines paper) suggests that it can work.
Notebooks
This is a PyTorch implementation of the paper Improving language models by retrieving from trillions of tokens. It builds a database of chunks of text. It is a key-value database where the keys are indexed by the BERT embeddings of the chunks. They use a frozen pre-trained BERT model to calculate these embeddings. The values are the corresponding chunks and an equal length of text proceeding that chunk. Then the model retrieves text similar (nearest neighbors) to the input to the model from this database. These retrieved texts are used to predict the output. Notebook is here.
The multi-headed attention notebook is in here.
Videos
Mingsheng Hong from Tensorflow talks about building an ML Infra and draws a number of similarities between ML Infra and data infrastructure in the following video: