Pathscopes: Inspect Hidden Representation of Neural Networks!
Machine Unlearning and different unlearning strategies

Articles

Pathscopes is a new framework from Google for inspecting the hidden representations of language models. Language models, such as BERT and GPT-3, have become increasingly powerful and widely used in natural language processing tasks. However, the inner workings of these models are often opaque, making it challenging to understand how they process and represent language. PatchScopes aims to address this challenge by providing a comprehensive and standardized approach to analyzing the hidden representations of language models.
Understanding Hidden Representations
The hidden representations of a language model refer to the intermediate outputs produced by the model's neural network layers as it processes input text. These representations capture various linguistic and semantic features, such as word meanings, syntactic structures, and contextual information. Understanding the nature and evolution of these representations as the input passes through the model's layers is crucial for interpreting the model's behavior and improving its performance.
Existing Approaches
Previous approaches to inspecting language model representations have faced several limitations. Visualization techniques, such as attention maps and activation heatmaps, provide a high-level view of the model's attention patterns or activation intensities, but they lack the granularity to reveal the detailed information captured in the representations. Probing tasks, which involve training separate models to predict specific linguistic properties from the hidden representations, have provided more quantitative insights, but they often rely on predefined tasks and may not capture the full breadth of information present in the representations.

PatchScopes Advantages
Patch-based Visualization: PatchScopes breaks down the hidden representations into small "patches" that can be visualized and analyzed. This approach provides a more granular view of the representations, allowing researchers to identify and interpret the specific features captured at different locations within the representations.
Probing Tasks: PatchScopes includes a comprehensive set of probing tasks that can be used to quantify the information present in the hidden representations. These tasks cover a wide range of linguistic properties, such as named entity recognition, sentiment analysis, and syntactic structure detection. By applying these probing tasks to the hidden representations, researchers can gain a deeper understanding of the types of information captured by the language model.
Unifying Framework: PatchScopes provides a standardized and consistent approach to inspecting language model representations. This allows researchers to compare the representations across different models and layers, enabling a more systematic and comprehensive analysis of language models.
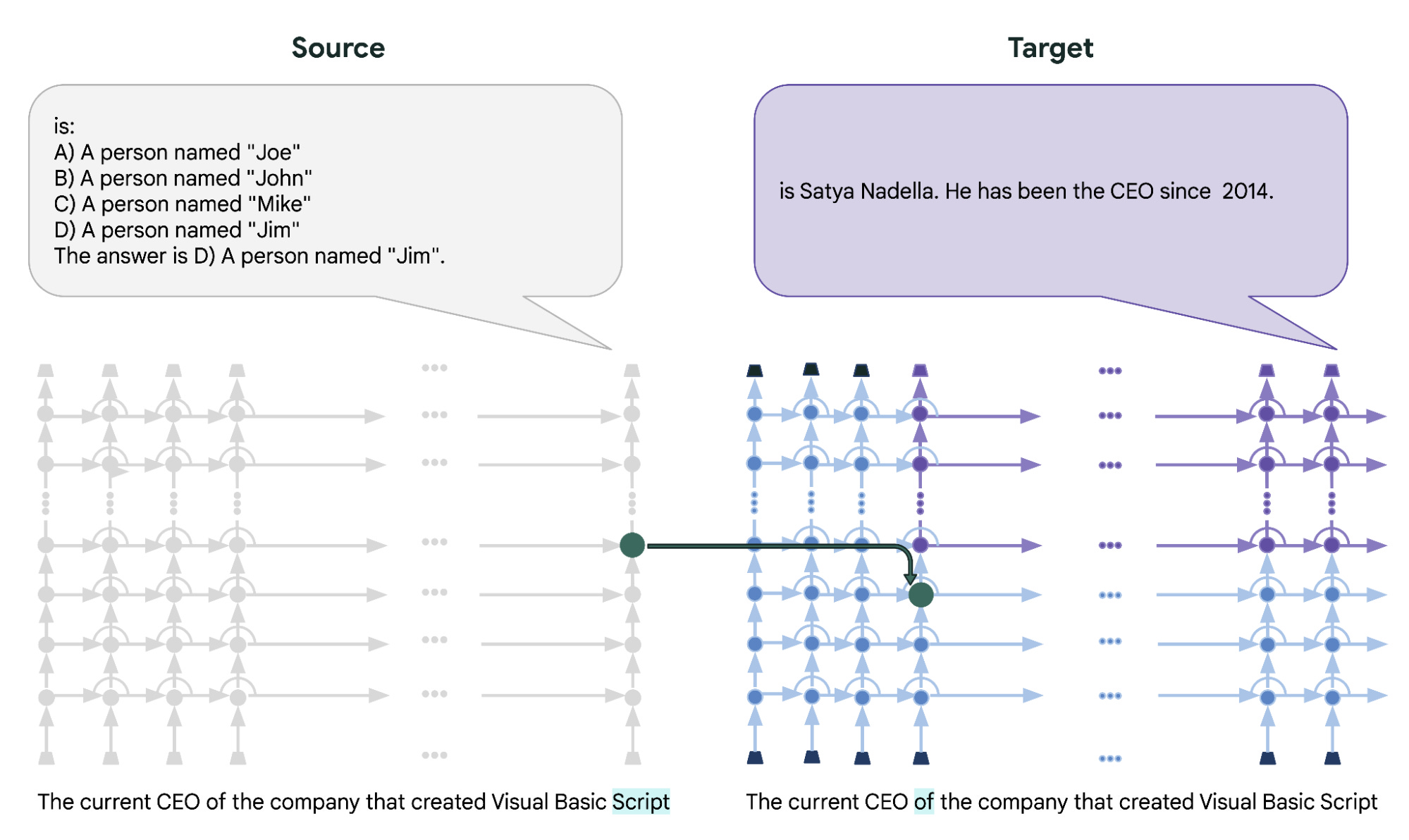
Some interesting findings
Layered Representations: The hidden representations of language models evolve across different layers, with earlier layers capturing more low-level features (e.g., word meanings) and later layers capturing more complex, higher-level features (e.g., syntactic structures and semantic relationships).
This itself is not too new as we know that CNN and other types neural networks generally learn well in an hierarchical manner where the first layer learns basic relations and later, more complex relations.
Specialized Patches: Within the hidden representations, PatchScopes identifies specialized patches that are particularly responsive to specific linguistic properties, such as named entities or sentiment. These specialized patches suggest that language models develop specialized sub-components to process different aspects of language.
Machine Unlearning
Machine Unlearning refers to the ability of ML models to selectively forget or remove certain information from their learned representations. This is an important challenge as ML models are increasingly being deployed in real-world applications where the ability to control and manage the learned knowledge is crucial. Ken Liu wrote a post on the machine unlearning and how to unlearn the ML models without a need for retraining the overall model without the data samples that are to be removed or want to be forgotten.
Reasons for why we want to do unlearning
Retraining Cost: Retraining an ML model from scratch to remove certain information can be computationally expensive, especially for large-scale models. This is a significant concern as the size and complexity of ML models continue to grow, making the cost of full retraining prohibitive.
Identifying Undesired Knowledge: It can be challenging to precisely identify the specific information that needs to be removed from a trained model, akin to "finding all Harry Potter references in a trillion tokens". This is particularly problematic when the undesired knowledge is not easily identifiable, such as subtle biases or implicit associations learned by the model.
Techniques for Exact Unlearning
The post discusses two key techniques for "exact unlearning", where the goal is to remove the influence of certain data points from the model while preserving the performance on the remaining data:
Submodel Isolation and Selective Retraining (SISA): In this approach, the training data is split into N non-overlapping subsets, and a separate model is trained for each subset. Unlearning can then be achieved by retraining only the model corresponding to the data points to be unlearned, which reduces the cost by a factor of 1/N compared to full retraining.The key idea behind SISA is to isolate the influence of different subsets of the training data, allowing for targeted retraining of only the relevant submodels. This approach can be particularly effective when the data points to be unlearned are concentrated in a specific subset of the training data.
Cao and Yang's Approach: This technique involves modifying the optimization problem during training to explicitly account for the data points that need to be unlearned. Specifically, the training objective is augmented with a term that penalizes the model's ability to predict the labels of the data points to be unlearned, effectively reducing their influence on the final model.By incorporating the unlearning requirement directly into the training process, this approach can achieve exact unlearning without the need for full retraining. The modified optimization problem ensures that the final model minimizes the influence of the undesired data points while maintaining performance on the remaining data.
These exact unlearning techniques can provide strong guarantees about the removal of specific data points from the learned model. However, the post notes that the evaluation of such unlearning techniques is challenging, as it requires quantifying aspects like efficiency, model utility, and the quality of forgetting.
Limitations of Unlearning
Messy and ill-defined: The post argues that unlearning is "messy for many reasons", and the precise definitions, techniques, and evaluation metrics depend on the specific ML task, data, and unlearning algorithm. This lack of a unified framework makes it difficult to compare and assess different unlearning approaches.
Evaluation Challenges: Quantifying the efficiency, model utility, and forgetting quality of unlearning techniques is non-trivial and an active area of research. Existing evaluation metrics may not capture the nuances of unlearning, and new, more comprehensive evaluation frameworks are needed.
Applicability Limitations: The exact unlearning techniques discussed, such as SISA and Cao and Yang's approach, are primarily designed for set-structured or graph-structured data. Extending these techniques to handle more complex data types, such as text, speech, and multimedia, remains a significant challenge.
As an alternative to unlearning, the article suggests the idea of "not learning at all", where the ML model is designed to avoid learning certain types of information in the first place. This could be achieved, for example, by carefully curating the pre-training data for large language models to exclude certain content, or by incorporating explicit constraints or regularization terms during the training process to discourage the model from learning undesired patterns.
For some other types of methods to not include various data structures and non-convex models, post also goes over different dimensions of the unlearning as well:
Unlearning for Diverse Data Structures: Extending unlearning techniques to handle complex data types like text, speech, and multimedia, beyond the traditional set-structured and graph-structured data. This would involve developing new unlearning algorithms that can effectively operate on these more complex data representations.
Unlearning for Non-convex Models: Developing efficient and effective unlearning algorithms for modern neural network architectures, such as CNNs, RNNs, and Transformers. The non-convex nature of these models poses additional challenges compared to the more traditional, convex models.
User-Specified Granularity of Unlearning: Exploring interactive and interpretable unlearning algorithms that allow users to selectively remove specific semantic components or patterns from the learned model. This could involve techniques for identifying and isolating the relevant parts of the model that need to be unlearned, as well as intuitive interfaces for users to specify their unlearning requirements.
Unlearning Evaluation Frameworks: Designing comprehensive evaluation frameworks that can assess the efficiency, model utility, and forgetting quality of unlearning techniques. This could include developing new metrics and benchmarks that capture the nuances of unlearning, as well as exploring the use of human evaluation and case studies to complement the quantitative assessments.
Unlearning for Federated and Distributed Learning: Investigating unlearning techniques that can be applied in the context of federated and distributed learning, where the training data is spread across multiple devices or organizations. This would involve addressing challenges related to privacy, communication, and coordination in the unlearning process.
Unlearning for Continual Learning: Exploring the intersection of unlearning and continual learning, where the goal is to update the model's knowledge over time while selectively forgetting or mitigating the influence of outdated or irrelevant information.
Libraries

LLooM is an interactive data analysis tool for unstructured text data, such as social media posts, paper abstracts, and articles. Manual text analysis is laborious and challenging to scale to large datasets, and automated approaches like topic modeling and clustering tend to focus on lower-level keywords that can be difficult for analysts to interpret.
By contrast, the LLooM algorithm turns unstructured text into meaningful high-level concepts that are defined by explicit inclusion criteria in natural language. For example, on a dataset of toxic online comments, while a BERTopic model outputs "women, power, female", LLooM produces concepts such as "Criticism of gender roles" and "Dismissal of women's concerns". We call this process concept induction: a computational process that produces high-level concepts from unstructured text.
The LLooM Workbench is an interactive text analysis tool that visualizes data in terms of the concepts that LLooM surfaces. With the LLooM Workbench, data analysts can inspect the automatically-generated concepts and author their own custom concepts to explore the data.
It has an excellent getting started page.
Orion is a fine-grained, interference-free scheduler for GPU sharing across ML workloads. We assume one of the clients is high-priority, while the rest of the clients are best-effort.
Orion intercepts CUDA, CUDNN, and CUBLAS calls and submits them into software queues. The Scheduler polls these queues and schedules operations based on their resource requirements and their priority. See ARCHITECTURE for more details on the system and the scheduling policy.
Orion expects that each submitted job has a file where all of its operations, along with their profiles and Straming Multiprocessor (SM) requirements are listed. See PROFILE for detailed instructions on how to profile a client applications, and how to generate the profile files.
Schedule-Free learning replaces the momentum of an underlying optimizer with a combination of interpolation and averaging. As the name suggests, Schedule-free learning does not require a decreasing learning rate schedule, yet typically out-performs, or at worst matches, SOTA schedules such as cosine-decay and linear decay. Only two sequences need to be stored at a time (the third can be computed from the other two on the fly) so this method has the same memory requirements as the base optimizer (parameter buffer + momentum).
Want to try a fine-tuning method that uses a fraction of the parameter count of SoTA PEFTs, while achieving potentially better performance? pyreft, a representation fine-tuning (ReFT) library that supports adapting internal language model representations via trainable interventions. With fewer fine-tuning parameters and more robust performance, pyreft can boost fine-tuning efficiency, decrease fine-tuning cost, while opening the doors to study the interpretability of adapting parameters.
pyreft supports:
Finetuning any pretrained LMs on HuggingFace with ReFT
Setting ReFT hyperparameters via configs
Sharing the fine-tuned results easily to HuggingFace

Programming for accelerators such as GPUs is critical for modern AI systems. This often means programming directly in proprietary low-level languages such as CUDA. Triton is an alternative open-source language that allows you to code at a higher-level and compile to accelerators like GPU.
Coding for Triton is very similar to Numpy and PyTorch in both syntax and semantics. However, as a lower-level language there are a lot of details that you need to keep track of. In particular, one area that learners have trouble with is memory loading and storage which is critical for speed on low-level devices.
Triton-Puzzles is puzzles is meant to teach you how to use Triton from first principles in an interactive fashion. You will start with trivial examples and build your way up to real algorithms like Flash Attention and Quantized neural networks. These puzzles do not need to run on GPU since they use a Triton interpreter.
🦆Qax🦆 is a tool for implementing types which represent tensors, but may or may not be instantiated as a single dense array on your GPU. Examples of this include:
Quantization: A 4-bit array of integers + a small number of scale values are used to represent a full 16/32-bit array
LoRA: An array 𝑊 is replaced by the array (𝑊+𝐵𝐴𝑇) so that 𝐴 and 𝐵 may be trained while leaving 𝑊 frozen
Symbolic zeros/constants: For arrays which will consist entirely of a single repeated value, simply store that single value and the shape of the array
Custom kernels: If you have a custom kernel and want to use it with existing models without modifying them, Qax is an easy way to do so
Gemini Cookbook of guides and examples for the Gemini API, including quickstart tutorials for writing prompts and using different features of the API, and examples of things you can build.

PERSIA (Parallel rEcommendation tRaining System with hybrId Acceleration) is developed by AI platform@Kuaishou Technology, collaborating with ETH. It is a PyTorch-based (the first public one to our best knowledge) system for training large scale deep learning recommendation models on commodity hardwares. It is capable of training recommendation models with up to 100 trillion parameters. To the best of our knowledge, this is the largest model size in recommendation systems so far. Empirical study on public datasets indicate PERSIA's significant advantage over several other existing training systems in recommendation [1]. Its efficiency and robustness have also been validated by multiple applications with 100 million level DAU at Kuaishou.