Aditya Ramesh wrote about how DallE-2 works under the hood in a concise post. They explain the concept in a word2vec manner which makes both CLIP and unCLIP concepts very intuitive.
Using unCLIP, we can translate points in CLIP’s concept space back into images and visually inspect the change that is taking place as we move the embedding of the image in the direction specified by the “before” caption (“a victorian house”) and the “after” caption (“a modern house”).
Google published a new library that they have developed in a blog post called TensorStore. TensorStore is a library for reading and writing large multi-dimensional arrays; very similar to Numpy, but it does not have to store the array in memory and can ingest and process data in disk which is much more scalable way. Further, it:
Provides a uniform API for reading and writing multiple array formats, including zarr and N5.
Supports safe, efficient access from multiple processes and machines via optimistic concurrency.
Offers an asynchronous API to enable high-throughput access even to high-latency remote storage.
Provides advanced, fully composable indexing operations and virtual views.
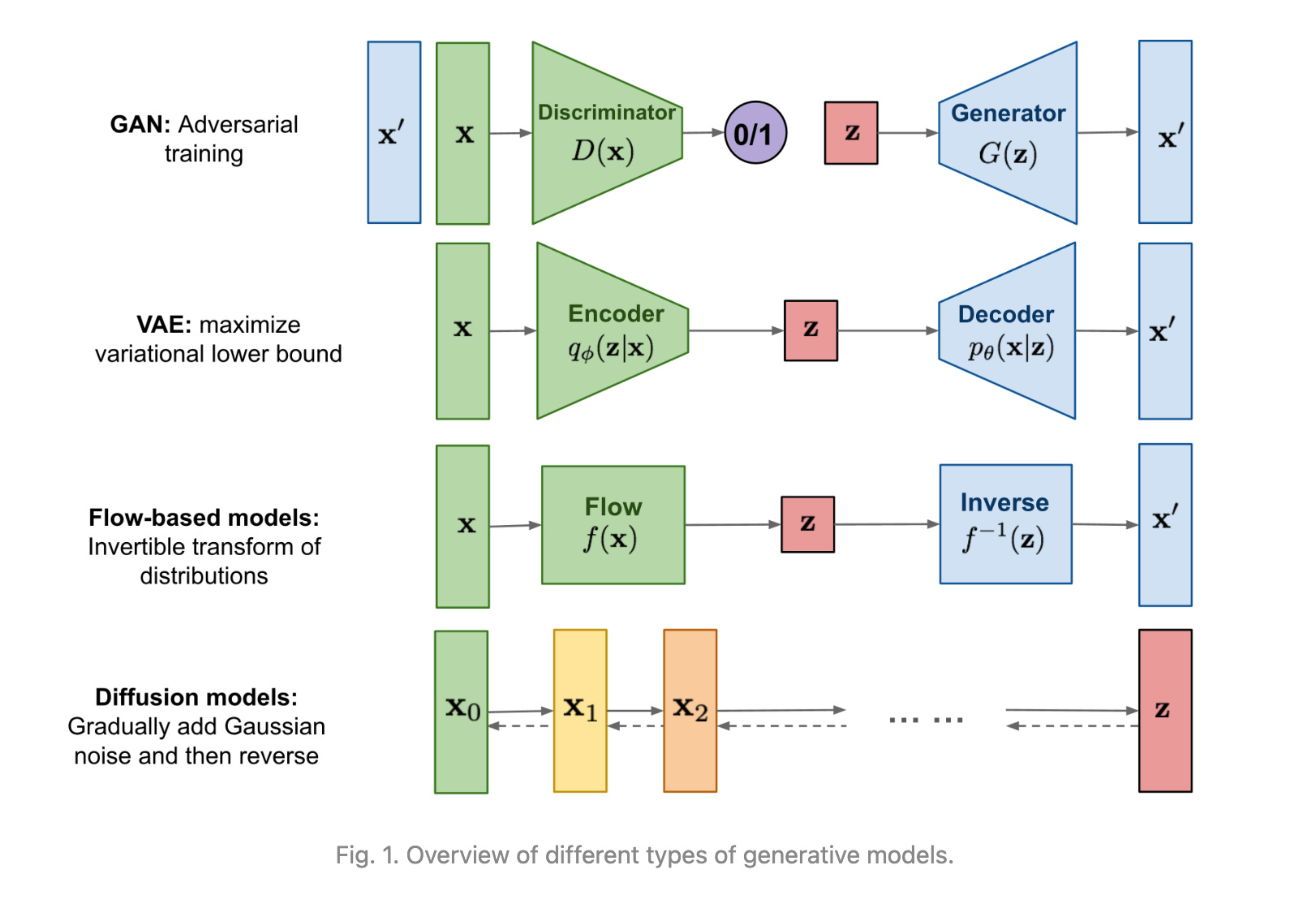
Lilian Weng wrote an excellent post on Diffusion Models. It goes over what Diffusion Models are and how they differ with other generative models. It outlines the high level advantages and disadvantages as a summary:
Pros: Tractability and flexibility are two conflicting objectives in generative modeling. Tractable models can be analytically evaluated and cheaply fit data (e.g. via a Gaussian or Laplace), but they cannot easily describe the structure in rich datasets. Flexible models can fit arbitrary structures in data, but evaluating, training, or sampling from these models is usually expensive. Diffusion models are both analytically tractable and flexible
Cons: Diffusion models rely on a long Markov chain of diffusion steps to generate samples, so it can be quite expensive in terms of time and compute. New methods have been proposed to make the process much faster, but the sampling is still slower than GAN.
OpenAI introduces Whisper which is an end to end system that decodes speech into text.
The Whisper architecture is a simple end-to-end approach, implemented as an encoder-decoder Transformer. Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
Libraries
Petals is a decentralized platform for running 100B+ language models from HuggingFace.
Run inference or fine-tune large language models like BLOOM-176B by joining compute resources with people all over the Internet. No need to have high-end GPUs.
It's difficult to fit the whole BLOOM-176B into GPU memory unless you have multiple high-end GPUs. Instead, Petals allows to load and serve a small part of the model, then team up with people serving all the other parts to run inference or fine-tuning.
This way, one inference step takes ≈ 1 sec — much faster than possible with offloading. Enough for chatbots and other interactive apps.
Beyond traditional language model APIs — you can employ any fine-tuning and sampling methods by executing custom paths through the model or accessing its hidden states. This allows for the comforts of an API with the flexibility of PyTorch
.
Embetter is a library that implements scikit-learn compatible embeddings for computer vision and text. It plays nicely with bulk which allows custom labeling and embedding updates on top of that.
Acme is a library of reinforcement learning (RL) building blocks that strives to expose simple, efficient, and readable agents. These agents first and foremost serve both as reference implementations as well as providing strong baselines for algorithm performance. However, the baseline agents exposed by Acme should also provide enough flexibility and simplicity that they can be used as a starting block for novel research. Finally, the building blocks of Acme are designed in such a way that the agents can be run at multiple scales (e.g. single-stream vs. distributed agents). It has a nice notebook for a QuickStart. The paper also goes a long way explaining different components.
Stable-Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database. Similar to Google's Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM. See this section below and the model card.
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
Workshops
Google had a Workshop on Sparsity and Adaptive Computation.
One central theme in this workshop is that different inputs may require different amounts and types of processing to enable efficient learning. Examples in the adaptive compute toolbox that we will explore in depth include decoupling model capacity and model compute with mixture of experts, saving compute on easy inputs via early exiting, or devoting modality-specific layers to different tokens by means of heterogeneous experts.