
SORA
Well, it has happened and OpenAI released the most powerful(to date) text to video generation model called Sora! I highly suggest to check the sample videos it out if you have not, especially upto 1 minute videos, it is very good quality and very realistic to the point that some videos cannot be distinguished from real production. If you have access, do share some of the good prompts and videos with me, I want to follow-up another post on this just with videos!
What was very interesting to me about the videos is that; it learns very well different types of techniques of camera movements, pan, zoom. Taking shots from different angles are very smooth and transitions are movie quality. You think a director is actually planning the video and a professional is recording the video. The physics laws(generally speaking) is preserved, although if you are asking a prompt that is hard to adhere to the physics laws, it does make exceptions!
Main Problem to Solve
Traditional methods for simulating the physical world often rely on predefined rules or meticulously crafted physics engines. While effective, these approaches can be inflexible and time-consuming to set up, limiting their effectiveness in capturing the full dynamism and nuance of the real world. Similarly, existing video generation models struggle to produce truly realistic and dynamic content, hindering their potential for generating immersive and informative simulations.
Technical Approach To Solve this Problem
is Diffusion Models! Specifically, text-conditional diffusion models trained on a massive dataset of diverse videos and images(no surprises with the amount of data that is needed to stitch a number of images to make this a video).
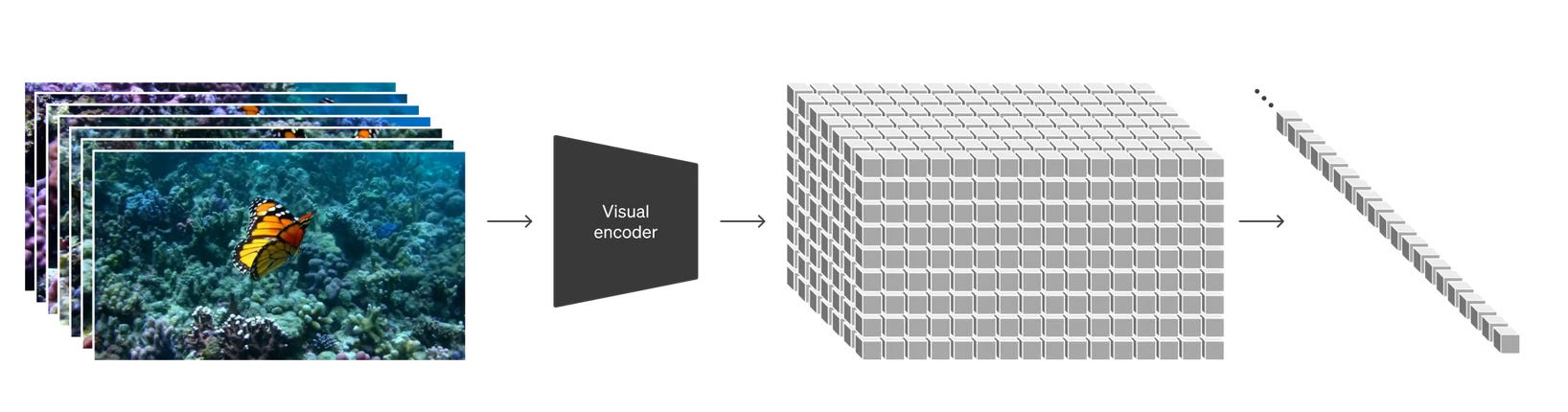
Some of the Key Highlights
Massive Dataset: Sora is trained on a whopping14 million video clips and 6 million static images. This diverse dataset, encompassing various resolutions, durations, and aspect ratios, equips the model with a rich understanding of visual elements and their interactions.
Transformer Architecture: The core architecture leverages a powerful transformer network, renowned for its ability to capture long-range dependencies and spatial relationships within data. This allows Sora to analyze patches extracted from the latent space of video and image data, understanding the intricate connections between visual elements across frames.
Diffusion Training: Inspired by a natural process, the training utilizes a diffusion process. Here, noise is gradually added to the training data, and the model learns to "reverse" this noise, essentially denoising it to reconstruct the original data. This unique training strategy empowers Sora to generate entirely new video frames, stitch them together seamlessly, and ultimately create original videos from scratch.
Textual Guidance: Text prompts can be incorporated into the generation process,guiding Sora to produce videos tailored to specific descriptions or instructions.
If we expand the transformer architecture and how it is different than some of the existing ones already, it has main 3 different approaches that are different than traditional transformers used for video processing:
Patch-based Processing: Instead of operating on entire video frames, Sora processes information in smaller chunks called patches. This allows the model to focus on specific regions of interest and capture finer-grained spatial relationships within the video.
Latent Space Transformation: Unlike standard transformers operating on pixel data, Sora operates on the latent space representation of the video. This compressed representation, learned during training, allows the model to capture the underlying structure and dynamics of the video more efficiently.
Multi-head Attention: Each transformer layer utilizes multiple attention heads, enabling the model to focus on different aspects of the latent space representation in parallel. This enhances its ability to extract diverse information crucial for video generation.
Results:
Realistic and Dynamic Videos: The model can generate high-fidelity, minute-long videos with stunning visual quality. Camera movements appear smooth and natural, objects interact realistically, and the overall experience is incredibly immersive.
Text-Driven Storytelling: With the power of text prompts, Sora can incorporate storytelling capability even in a one minute video.
Libraries
Autoregressive Image Models(AIM) accompanies the research paper, Scalable Pre-training of Large Autoregressive Image Models.
Apple introduces AIM a collection of vision models pre-trained with an autoregressive generative objective. They show that autoregressive pre-training of image features exhibits similar scaling properties to their textual counterpart (i.e. Large Language Models). Specifically, we highlight two findings:
the model capacity can be trivially scaled to billions of parameters, and
AIM effectively leverages large collections of uncurated image data.
DeepRec is a high-performance recommendation deep learning framework based on TensorFlow 1.15, Intel-TensorFlow and NVIDIA-TensorFlow. It is hosted in incubation in LF AI & Data Foundation.
Recommendation models have huge commercial values for areas such as retailing, media, advertisements, social networks and search engines. Unlike other kinds of models, recommendation models have large amount of non-numeric features such as id, tag, text and so on which lead to huge parameters.
DeepRec has been developed since 2016, which supports core businesses such as Taobao Search, recommendation and advertising. It precipitates a list of features on basic frameworks and has excellent performance in recommendation models training and inference. So far, in addition to Alibaba Group, dozens of companies have used DeepRec in their business scenarios.
DeepRec has super large-scale distributed training capability, supporting recommendation model training of trillion samples and over ten trillion parameters. For recommendation models, in-depth performance optimization has been conducted across CPU and GPU platform. It contains list of features to improve usability and performance for super-scale scenarios.
Some Key Features
Embedding Variable.
Dynamic Dimension Embedding Variable.
Adaptive Embedding Variable.
Multiple Hash Embedding Variable.
Multi-tier Hybrid Embedding Storage.
Group Embedding.
AdamAsync Optimizer.
AdagradDecay Optimizer.
AskVideos-VideoCLIP is a language-grounded video embedding model.
16 frames are sampled from each video clip to generate a video embedding.
The model is trained on 2M clips from WebVid and 1M clips from the AskYoutube dataset.
The model is trained with contrastive and captioning loss to ground the video embeddings to text.

FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.
The unique features of FlashInfer include:
Comprehensive Attention Kernels: Attention kernels that cover all the common use cases of LLM serving, including single-request and batching versions of Prefill, Decode, and Append kernels, on different formats of KV-Cache (Padded Tensor, Ragged Tensor, and Page Table).
Optimized Shared-Prefix Batch Decoding: FlashInfer enhances shared-prefix batch decoding performance through cascading, resulting in an impressive up to 31x speedup compared to the baseline vLLM PageAttention implementation (for long prompt of 32768 tokens and large batch size of 256).
Accelerate Attention for Compressed/Quantized KV-Cache: Modern LLMs are often deployed with quantized/compressed KV-Cache to reduce memory traffic. FlashInfer accelerates these scenarios by optimizing performance for Grouped-Query Attention, Fused-RoPE Attention and Quantized Attention.
Nanotron is a minimalistic large language model 3D-parallelism training, which aims to provide easy distributed primitives in order to train a variety of models efficiently using 3D parallelism.
Some Key Features:
Make it fast. At least as fast as other open source versions.
Make it minimal. We don't actually need to support all techniques and all versions of 3D parallelism. What matters is that we can efficiently use the "best" ones.
Make everything explicit instead of transparent. As we move forward, making things transparent works well when it works well but is a horrible debugging experience if one doesn't understand the implications of techniques used. In order to mitigate this, we choose to be explicit in the way it does things
LM Evaluation Harness provides a unified framework to test generative language models on a large number of different evaluation tasks.
Features:
Over 60 standard academic benchmarks for LLMs, with hundreds of subtasks and variants implemented.
Support for models loaded via transformers (including quantization via AutoGPTQ), GPT-NeoX, and Megatron-DeepSpeed, with a flexible tokenization-agnostic interface.
Support for fast and memory-efficient inference with vLLM.
Support for commercial APIs including OpenAI, and TextSynth.
Support for evaluation on adapters (e.g. LoRA) supported in HuggingFace's PEFT library.
Support for local models and benchmarks.
Evaluation with publicly available prompts ensures reproducibility and comparability between papers.
Easy support for custom prompts and evaluation metrics.