

Modules in Pinterest's HomeFeed
Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models

Articles
.")
NVIDIA’s Nemotron-H series introduces a family of hybrid Mamba-Transformer models designed to address the limitations of traditional Transformer architectures while maintaining the accuracy. These models achieve up to 3x faster inference speeds compared to similarly sized Transformers, making them highly efficient for real-world applications. The variants of these series of models are in the following:
8B Models:
Nemotron-H-8B-Base (pretrained on 15T tokens)
Nemotron-H-8B-Instruct (instruction-tuned)
Nemotron-H-8B-VLM (vision-language variant)
47-56B Models:
Nemotron-H-47B-Base (distilled from 56B)
Nemotron-H-56B-Base (pretrained on 20T tokens in FP8)
Nemotron-H-56B-VLM (multimodal variant)
Hybrid Mamba-Transformer Layers
Nemotron-H combines Mamba-2 SSM layers (54 layers in 56B model) with Transformer self-attention layers (10 layers):
Mamba-2 Layers:
Replace ~83% of self-attention layers in traditional Transformers
Use state-space models (SSMs) for sequence modeling
Operate with O(1) memory/compute per token during autoregressive generation
Enable 3x faster inference compared to pure Transformers on 65k-token contexts
Residual Attention Layers:
10 self-attention layers retained for critical reasoning steps
Employ rotary positional embeddings (RoPE)
Use grouped-query attention (GQA) with 8 key/value heads
FP8
The 56B model represents the largest FP8-pretrained LLM to date:
Full-stack FP8 implementation:
Forward/backward passes in FP8
Optimizer states stored in FP8
Distributed tensor parallelism with FP8 gradients
Memory savings:
47% reduction in GPU memory vs bfloat16
Enables training 56B model on 6,144 H100 GPUs (768 nodes)
Model Distillation Technique
The 47B model was distilled from 56B using FP8-aware progressive layer removal:
Layer similarity analysis:
Removed 6 Mamba layers showing highest cosine similarity (≥0.93)
Pruned 2 attention layers with lowest attention entropy
Distillation curriculum:
63B token dataset (1:5 mix of synthetic & original pretraining data)
KL divergence loss with temperature τ=2.0
3-stage progressive unfreezing of teacher layers
This has resulted in the following model accuracy and efficiency tradeoff:
Retains 98.7% of 56B model's MMLU performance
12% faster inference than original 56B model
Long-Context Optimization
Nemotron-H achieves 64k-token context via:
Dynamic Packing:
Concatenates documents up to 512k tokens
Synthetic dependency injection between segments
Positional Encoding:
RoPE with base θ=500,000 (vs standard 10,000)
Linear interpolation for fine-grained position resolution
Training Infrastructure
Cluster: 6,144 H100 GPUs (768 nodes)
Parallelism strategy:
8-way tensor parallelism
12-way pipeline parallelism with interleaving
64-way data parallelism
Throughput:
3.2T tokens/day at peak efficiency
89% MFU (model flop utilization)
Instead of going with the traditional transformer architecture, NVIDIA demonstrates that a lot of efficiency can be achieved while not deteriorating the model performance overall.
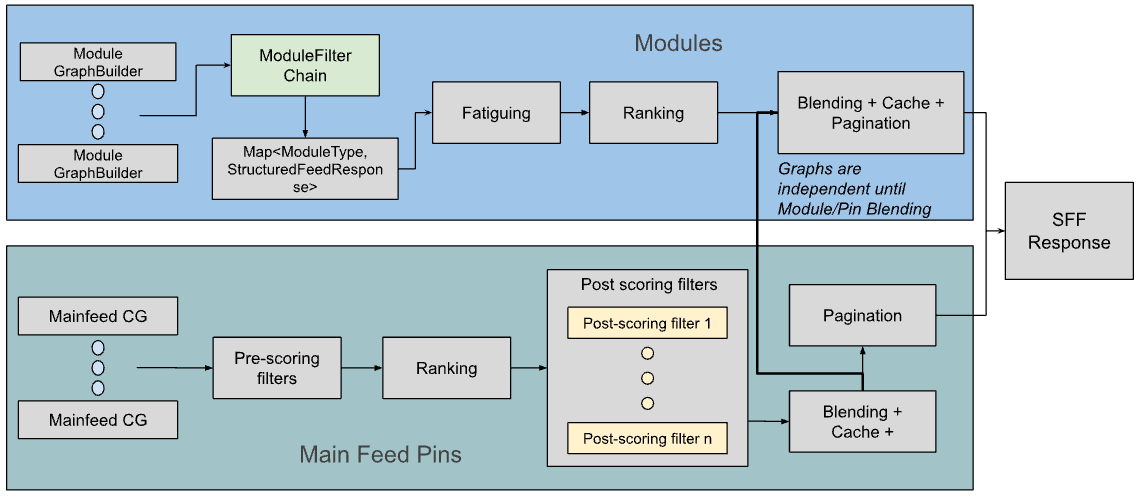
Pinterest's explains their Homefeed, traditionally a grid of individual Pins, and how they have evolved Homefeed to include modules: richer, context-aware content formats. They expand how they think about module relevance, covering module fatiguing, ranking, and blending strategies. The main idea is to integrate modules without compromising the core user experience and engagement on the Homefeed.
Modules
Modules represent a significant departure from the traditional Pin-centric Homefeed. They are designed to provide:
Context: Offering additional information and ways to explore topics related to a user's interests.
Diversity: Introducing new topics and content types beyond individual Pins.
Control: Giving users more granular control over their browsing experience.
Modules come in two primary formats:
Landing Page Modules: Tapping these modules directs users to a dedicated landing page featuring related Pins and content.
Carousel Modules: These are horizontal shelves of Pins displayed directly within the Homefeed.
Modules bring a challenge with them: how to effectively blend these new content units with the existing, highly optimized grid of Pins without negatively impacting user engagement. The "HF Module Relevance Platform" was developed to address this challenge, dynamically blending modules and Pins to optimize the Homefeed experience for each user.
Module Fatiguing
Module fatiguing operates on a simple principle: if a user repeatedly sees a specific module without interacting with it, the module should be temporarily hidden. This prevents users from being bombarded with irrelevant or uninteresting modules, thereby preserving the overall Homefeed quality.
Daily Workflow: A daily workflow aggregates each user's historical module engagement data.
The key metric is the number of impressions since the user's last click on a particular module.
Heuristic-Based Approach:
If the number of impressions without a click exceeds a threshold (k) over the past n days, the module is hidden from the user for d days.
n, k, and d are tunable parameters.
Formulaic Representation
Let:
I(u, m, t) = Number of impressions for user u on module m at time t.
LC(u, m) = Last click timestamp of user u on module m.
Fatiguing Rule:
If ∑ $$I(u, m, t) for LC(u, m) < t < now] > k over the past n days, then hide module m from user u for d days.
The disadvantages of Fatigue
As the module ecosystem expanded, the limitations of the heuristic-based fatiguing approach became apparent:
Binary Decision: Fatiguing only determines whether to show a module, not how or where to show it within the Homefeed.
Granularity: The approach is limited to the module-type level, lacking the granularity to distinguish between variations within a module type (e.g., different product categories in a shopping module).
Real-time Responsiveness: The daily workflow update cycle means that fatiguing signals are not real-time, leading to potential delays in responding to changing user preferences.
To address these limitations, Pinterest invested in new relevance components, including module ranking and blending.
Module Ranking
The module ranker is responsible for ordering modules based on their predicted relevance to a given user, ensuring that the most interesting modules are presented higher in the Homefeed.
Baseline Approach: Leveraging Pin Ranking
Initially, Pinterest utilized the existing Homefeed Pin Ranking model for module ranking. The steps to do so are in the following:
Cover Pin Selection: Selecting the first four "cover Pins" from each module.
Pin Scoring: Scoring these cover Pins using the production Pin Ranking model.
Module Score Aggregation: Calculating a module score based on the maximum calibrated save score among the four cover Pins.
Quality Filtering: Filtering out "low quality" modules based on a percentile threshold (x) on the module score. Some modules may have custom filtering thresholds.
Deep Ranking Model: A Dedicated Module Ranker
The limitations of the Pin Ranking-based approach led to the development of a dedicated module ranking model.
Rationale
The existing Pin Ranking model is a complex, critical component of the Homefeed. Making direct adjustments to this model to improve module ranking performance is challenging and potentially risky.
The Pin Ranker does not consider user-module engagement, limiting its ability to personalize module distribution.
Architecture
Multi-Head Model: The Module Ranker is a multi-head model, optimized for various module actions:
Module Taps
Pin Clicks on Carousel/Landing Page
Saves on Carousel/Landing Page
Binary Classification: These positive actions are mapped to binary labels, and the model is trained using binary cross-entropy loss.
Data Sampling Strategy
Positive Label Retention: All positive labels representing module engagement are retained.
Negative Label Downsampling: Impressions (negative labels) are downsampled to maintain a balance between positive and negative examples.
Feature Set
The Module Ranker utilizes a comprehensive set of features, including:
Module Features:
Aggregated engagement features (taps, impressions, repins, closeups, clicks, long clicks) over various time windows (1, 7, 28 days), both overall and per user.
Module Title Embeddings, Module Type, UI Type.
Cover Image Pin Ranker Predictions.
Pretrained Embeddings: Visual information, shopping intent, Pin representations, and other onsite signals extracted from the first four cover Pins.
User Features:
Viewer engagement features.
Viewer characteristics (gender, language, user state).
Context Features.
Calibration Layer
Due to the downsampling of impressions, a calibration layer is used to map the predicted scores to empirical engagement rates.
Calibration training data is distinct from normal model training data.
The calibrated scores are used in the blending layer to dynamically place modules.
Utility Function
A utility function combines the predictions from the multiple heads into a single score used for module ranking.
This function is a weighted sum of the prediction scores, with weights determined based on business insights and offline/online tuning.
Mathematical Representation
Module Utility Score = ∑ $$wᵢ * PredictionScoreᵢ] for all heads i, where wᵢ is the weight for head i.
Module Blending
Module blending determines how modules are dynamically integrated into the Homefeed alongside Pins.
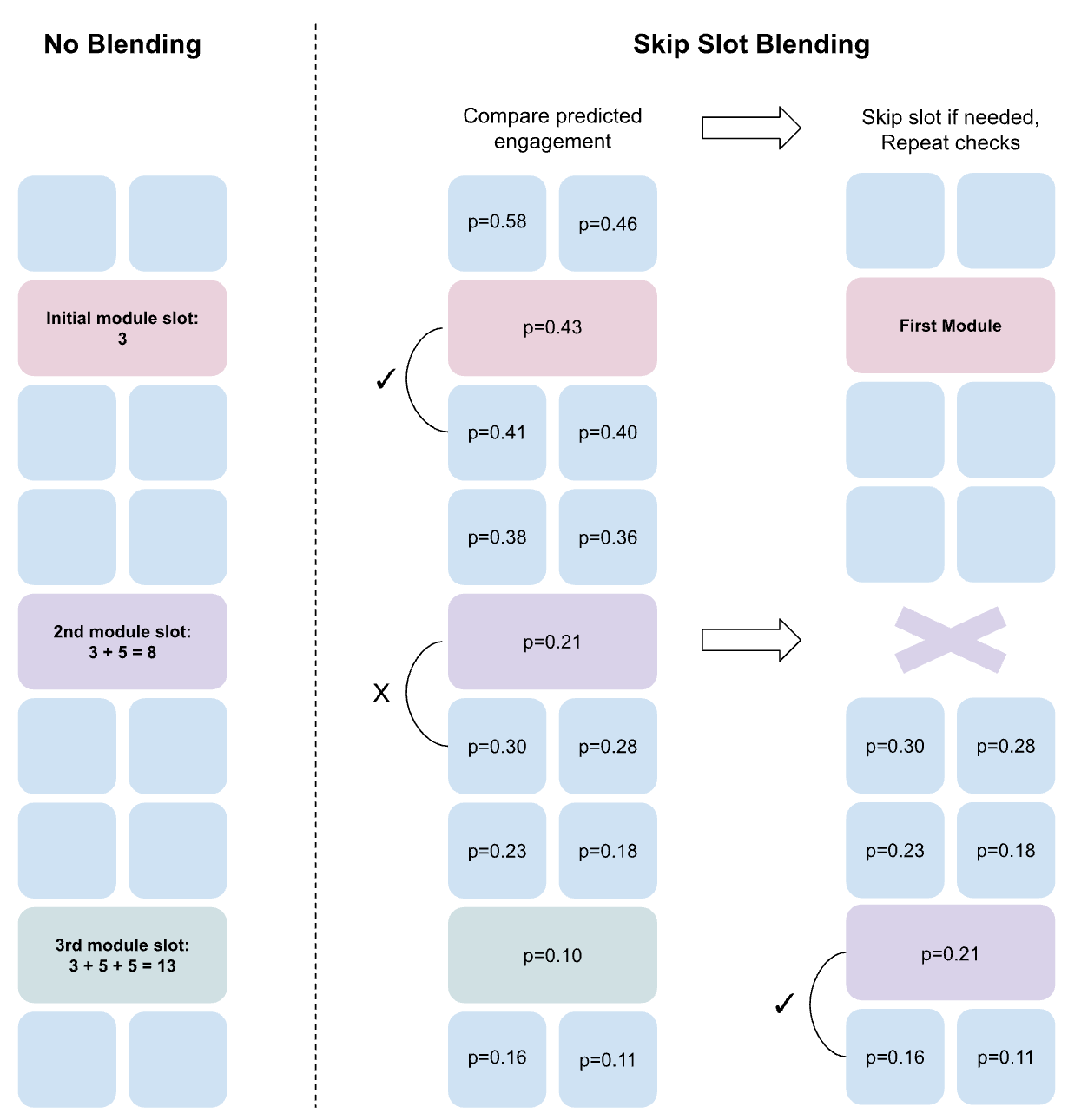
The initial approach placed modules in fixed slots within the feed (e.g., slots 15, 35, 55, 75). This could negatively impact user engagement by displacing highly engaging Pins with modules.
Skip-Slot Blending: Dynamic Placement
To address this, Pinterest developed "skip-slot" blending, a strategy that dynamically places modules based on the predicted engagement of the surrounding Pins.
Pin Utility Score
A Pin Utility score is computed for each Pin using the outputs of the Pin Ranker. This score represents the predicted engagement of the Pin.
Comparison Function
The comparison function determines whether a module should replace a Pin in a given slot.
The function compares the Module Utility score (from the module ranker) to the Pin Utility score, with a weighting coefficient (wₚ) to control the preference for modules versus Pins.
Comparison Formula
Module Utility Score > wₚ * Pin Utility Score
If the Module Utility score is higher, the module replaces the Pin. Otherwise, the check is repeated k slots lower.
Algorithm
Order modules based on their Module Utility score.
For each module:
Starting at slot s, check if Module Utility score > wₚ * Pin Utility score at that slot.
If true, place the module in slot s.
Otherwise, repeat the check k slots lower.
Repeat until all modules are placed or no slots remain.
This algorithm allows modules with lower scores to be moved further down the feed or removed entirely if they do not meet the engagement threshold.
By using these strategies(module fatiguing, dedicated ranking models, and dynamic blending strategies), Pinterest successfully introduced modules in their home feed without hurting the relevance and possibly improving the user experience.
LeetCode for ML ~> DeepML
As you probably know that LeetCode is an online platform designed to help developers practice coding, improve problem-solving skills, and prepare for technical interviews. It offers a wide range of coding and algorithmic problems across various difficulty levels and topic.
Deep-ML is trying to be the same equivalent of leetcode for the ML assignments and contents. Their problems start with basic linear algebra and back propagation algorithms and it offers problems that builds on top of these algorithmic problems.
Libraries

T6 (Tensor ProducT ATTenTion Transformer) is a state-of-the-art transformer model that leverages Tensor Product Attention (TPA) mechanisms to enhance performance and reduce KV cache size. This repository provides tools for data preparation, model pretraining, and evaluation to facilitate research and development using the T6 architecture.
It has the following features:
Tensor Product Attention: Implements advanced attention mechanisms for improved model performance.
Scalability: Efficient training procedures optimized for large-scale datasets and multi-GPU setups.
Flexible Data Support: Compatible with popular datasets like Fineweb-Edu-100B and OpenWebText.
Comprehensive Evaluation: Integrated with lm-evaluation-harness for standardized benchmarking.
Higher-order TPA (TBD): Higher-order TPA.
Flash TPA (TBD): Flash TPA.
It has also the following documentation page as well.
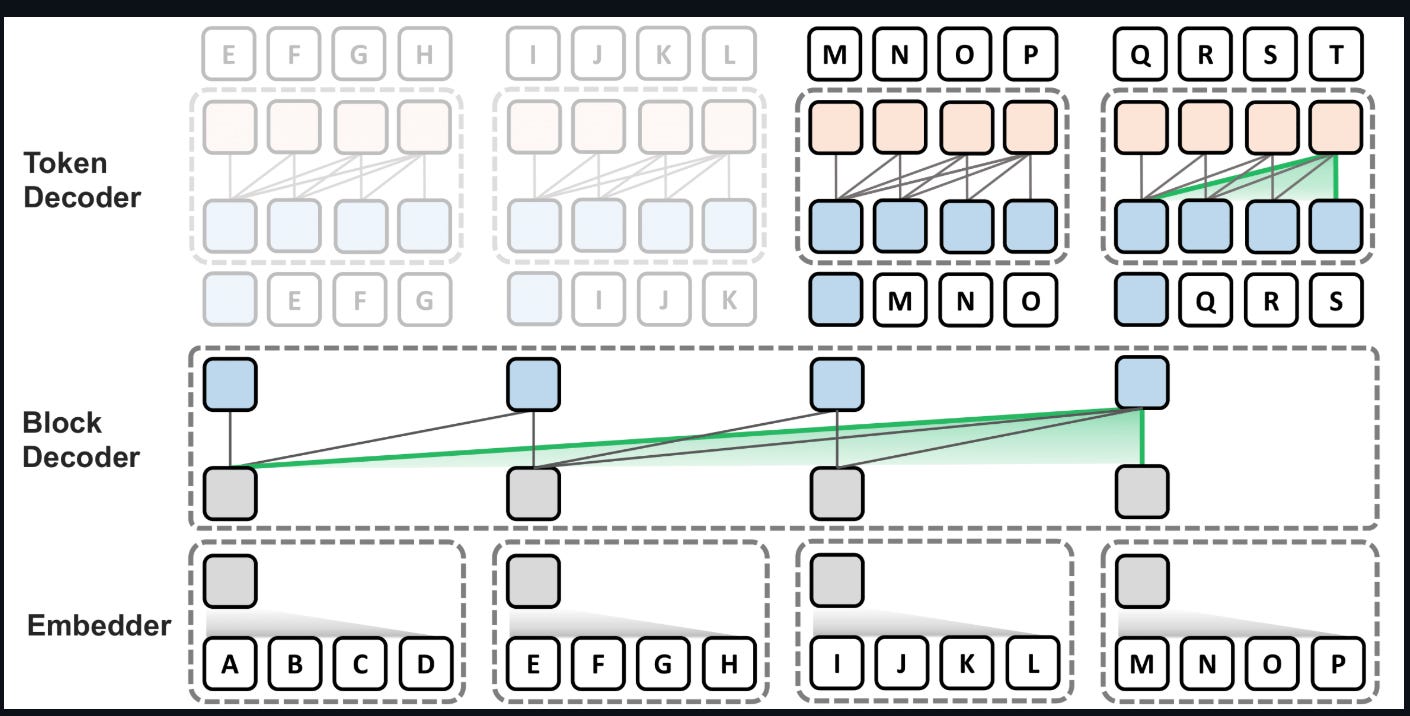
Block Transformer is an architecture which adopts hierarchical global-to-local language modeling to autoregressive transformers to mitigate inference bottlenecks of self-attention. Block Transformer models global dependencies through self-attention between coarse blocks at lower layers (in block decoder), and decodes fine-grained tokens within each local block at upper layers (in token decoder). In this architecture, inference-time benefits of both global and local modules, achieving 10-20x gains in throughput compared to vanilla transformers with equivalent perplexity

TensorDict is a dictionary-like class that inherits properties from tensors, making it easy to work with collections of tensors in PyTorch. It provides a simple and intuitive way to manipulate and process tensors, allowing you to focus on building and training your models.
TensorDict makes your code-bases more readable, compact, modular and fast. It abstracts away tailored operations, making your code less error-prone as it takes care of dispatching the operation on the leaves for you.
The key features are:
🧮 Composability:
TensorDictgeneralizestorch.Tensoroperations to collection of tensors.⚡️ Speed: asynchronous transfer to device, fast node-to-node communication through
consolidate, compatible withtorch.compile.✂️ Shape operations: Perform tensor-like operations on TensorDict instances, such as indexing, slicing or concatenation.
🌐 Distributed / multiprocessed capabilities: Easily distribute TensorDict instances across multiple workers, devices and machines.
💾 Serialization and memory-mapping
λ Functional programming and compatibility with
torch.vmap📦 Nesting: Nest TensorDict instances to create hierarchical structures.
⏰ Lazy preallocation: Preallocate memory for TensorDict instances without initializing the tensors.
📝 Specialized dataclass for torch.Tensor (
@tensorclass)

SGLang is a fast serving framework for large language models and vision language models. It makes your interaction with models faster and more controllable by co-designing the backend runtime and frontend language. The core features include:
Fast Backend Runtime: Provides efficient serving with RadixAttention for prefix caching, jump-forward constrained decoding, overhead-free CPU scheduler, continuous batching, token attention (paged attention), tensor parallelism, FlashInfer kernels, chunked prefill, and quantization (FP8/INT4/AWQ/GPTQ).
Flexible Frontend Language: Offers an intuitive interface for programming LLM applications, including chained generation calls, advanced prompting, control flow, multi-modal inputs, parallelism, and external interactions.
Extensive Model Support: Supports a wide range of generative models (Llama, Gemma, Mistral, QWen, DeepSeek, LLaVA, etc.), embedding models (e5-mistral, gte, mcdse) and reward models (Skywork), with easy extensibility for integrating new models.
Active Community: SGLang is open-source and backed by an active community with industry adoption.

Rigging is a lightweight LLM framework to make using language models in production code as simple and effective as possible. Here are the highlights:
Structured Pydantic models can be used interchangably with unstructured text output.
LiteLLM as the default generator giving you instant access to a huge array of models.
Define prompts as python functions with type hints and docstrings.
Simple tool use, even for models which don't support them at the API.
Store different models and configs as simple connection strings just like databases.
Integrated tracing support with Logfire.
Chat templating, forking, continuations, generation parameter overloads, stripping segments, etc.
Async batching and fast iterations for large scale generation.
Metadata, callbacks, and data format conversions.
Modern python with type hints, async support, pydantic validation, serialization, etc.
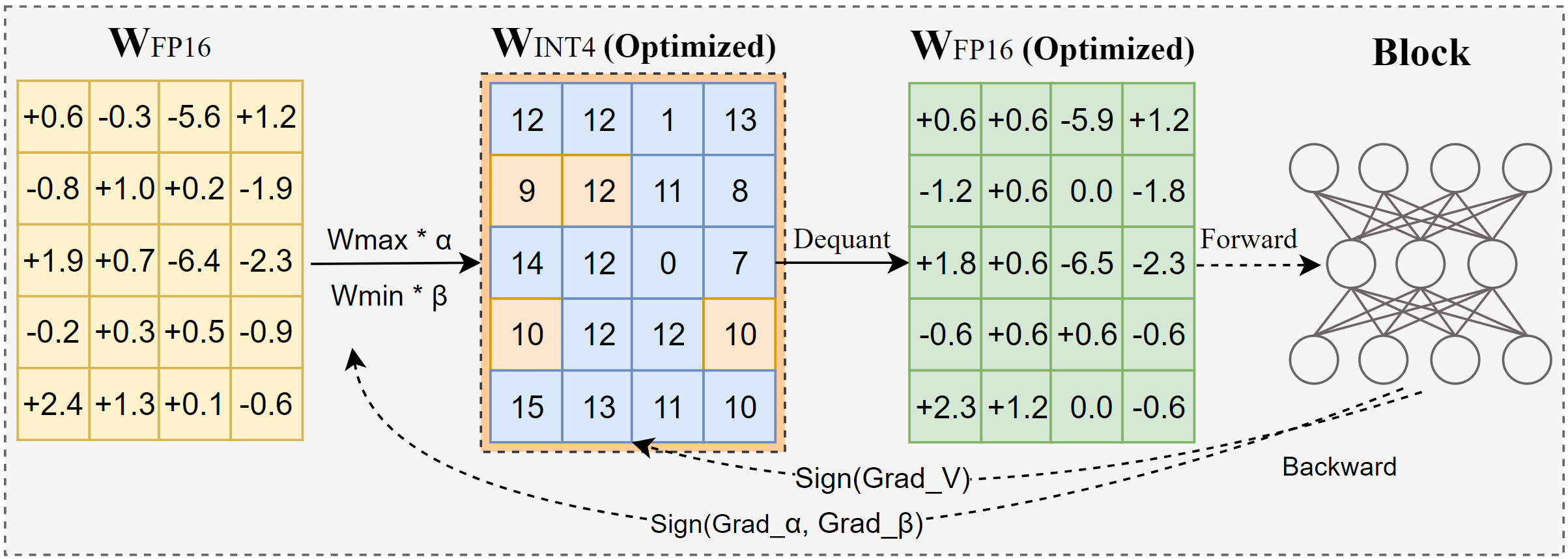
AutoRound is an advanced quantization algorithm for low-bits LLM/VLM inference. It's tailored for a wide range of models. AutoRound adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, which competes impressively against recent methods without introducing any additional inference overhead and keeping low tuning cost. The below image presents an overview of AutoRound. Check out our paper on arxiv for more details and quantized models in several Hugging Face Spaces, e.g. OPEA, Kaitchup and fbaldassarri.

Think of Director as ChatGPT for videos. It is a framework to build video agents that can reason through complex video tasks like search, editing, compilation, generation etc & instantly stream the results.
For example, a simple natural language command like: Upload this video and send the highlights to my Slack, sets everything in motion - Director’s reasoning will orchestrate the different agents intelligently to complete the task for you.
Built on top of VideoDB’s ‘video-as-data’ infrastructure, Director enables you to:
Summarize videos in seconds.
Search for specific moments.
Create clips instantly.
Integrate top GenAI projects and APIs and create and edit content instantly.
Add overlays, extract frames.

Graphiti builds dynamic, temporally aware Knowledge Graphs that represent complex, evolving relationships between entities over time. Graphiti ingests both unstructured and structured data, and the resulting graph may be queried using a fusion of time, full-text, semantic, and graph algorithm approaches.


In pursuit of more inclusive Vision-Language Models (VLMs), this study introduces a Large Multilingual Multimodal Model called PALO. PALO offers visual reasoning capabilities in 10 major languages, including English, Chinese, Hindi, Spanish, French, Arabic, Bengali, Russian, Urdu, and Japanese, that span a total of ~5B people (65% of the world population).
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples:
Seamless user experience of model compressions on Transformer-based models by extending Hugging Face transformers APIs and leveraging Intel® Neural Compressor
Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper Fast Distilbert on CPUs and QuaLA-MiniLM: a Quantized Length Adaptive MiniLM, and NeurIPS 2021's paper Prune Once for All: Sparse Pre-Trained Language Models)
Optimized Transformer-based model packages such as Stable Diffusion, GPT-J-6B, GPT-NEOX, BLOOM-176B, T5, Flan-T5, and end-to-end workflows such as SetFit-based text classification and document level sentiment analysis (DLSA)
NeuralChat, a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of plugins such as Knowledge Retrieval, Speech Interaction, Query Caching, and Security Guardrail. This framework supports Intel Gaudi2/CPU/GPU.
Inference of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting GPT-NEOX, LLAMA, MPT, FALCON, BLOOM-7B, OPT, ChatGLM2-6B, GPT-J-6B, and Dolly-v2-3B. Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed Sapphire Rapids.
DomiKnowS is a Python library that facilitates the integration of domain knowledge in deep learning architectures. With DomiKnowS, you can express the structure of your data symbolically via graph declarations and seamlessly add logical constraints over outputs or latent variables to your deep models. This allows you to define domain knowledge explicitly, improving your models' explainability, performance, and generalizability, especially in low-data regimes.
MLX is an array framework for machine learning on Apple silicon, brought to you by Apple machine learning research.
Some key features of MLX include:
Familiar APIs: MLX has a Python API that closely follows NumPy. MLX also has fully featured C++, C, and Swift APIs, which closely mirror the Python API. MLX has higher-level packages like
mlx.nnandmlx.optimizerswith APIs that closely follow PyTorch to simplify building more complex models.Composable function transformations: MLX supports composable function transformations for automatic differentiation, automatic vectorization, and computation graph optimization.
Lazy computation: Computations in MLX are lazy. Arrays are only materialized when needed.
Dynamic graph construction: Computation graphs in MLX are constructed dynamically. Changing the shapes of function arguments does not trigger slow compilations, and debugging is simple and intuitive.
Multi-device: Operations can run on any of the supported devices (currently the CPU and the GPU).
Unified memory: A notable difference from MLX and other frameworks is the unified memory model. Arrays in MLX live in shared memory. Operations on MLX arrays can be performed on any of the supported device types without transferring data.
SPDL (Scalable and Performant Data Loading) is a library and project to explore the design and performance of data loading with thread-based parallelism.
SPDL is a framework-agnostic data loading solution that utilizes multi-threading, which achieves high-throughput in a regular Python interpreter (built without free-threading option enabled).
When compared against conventional process-based solutions, SPDL achieves 2x – 3x throughput while using a smaller amount of compute resources.
SPDL is compatible with Free-Threaded Python. Running SPDL in FT Python with the GIL disabled achieves 30% higher throughput compared to the same FT Python with the GIL enabled.
Copper is a user-friendly runtime engine for creating fast and reliable robots. Copper is to robots what a game engine is to games.
Easy: Copper offers a high-level configuration system and a natural Rust-first API.
Fast: Copper uses Rust's zero-cost abstractions and a data-oriented approach to achieve sub-microsecond latency on commodity hardware, avoiding heap allocation during execution.
Reliable: Copper leverages Rust's ownership, type system, and concurrency model to minimize bugs and ensure thread safety.
Product Oriented: Copper aims to avoid late-stage infra integration issues by generating a very predictable runtime.

Fast-LLM is a cutting-edge open-source library for training large language models with exceptional speed, scalability, and flexibility. Built on PyTorch and Triton, Fast-LLM empowers AI teams to push the limits of generative AI, from research to production.
Optimized for training models of all sizes—from small 1B-parameter models to massive clusters with 70B+ parameters—Fast-LLM delivers faster training, lower costs, and seamless scalability. Its fine-tuned kernels, advanced parallelism techniques, and efficient memory management make it the go-to choice for diverse training needs.
As a truly open-source project, Fast-LLM allows full customization and extension without proprietary restrictions. Developed transparently by a community of professionals on GitHub, the library benefits from collaborative innovation, with every change discussed and reviewed in the open to ensure trust and quality. Fast-LLM combines professional-grade tools with unified support for GPT-like architectures, offering the cost efficiency and flexibility that serious AI practitioners demand.
Classes

This is a practical course on aligning language models for your specific use case. It's a handy way to get started with aligning language models, because everything runs on most local machines. There are minimal GPU requirements and no paid services. The course is based on the SmolLM2 series of models, but you can transfer the skills you learn here to larger models or other small language models.