Modular Deep Learning
Performance Gains with PyTorch 2.0, LAyer-SElective Rank-Reduction(LASER)

Articles
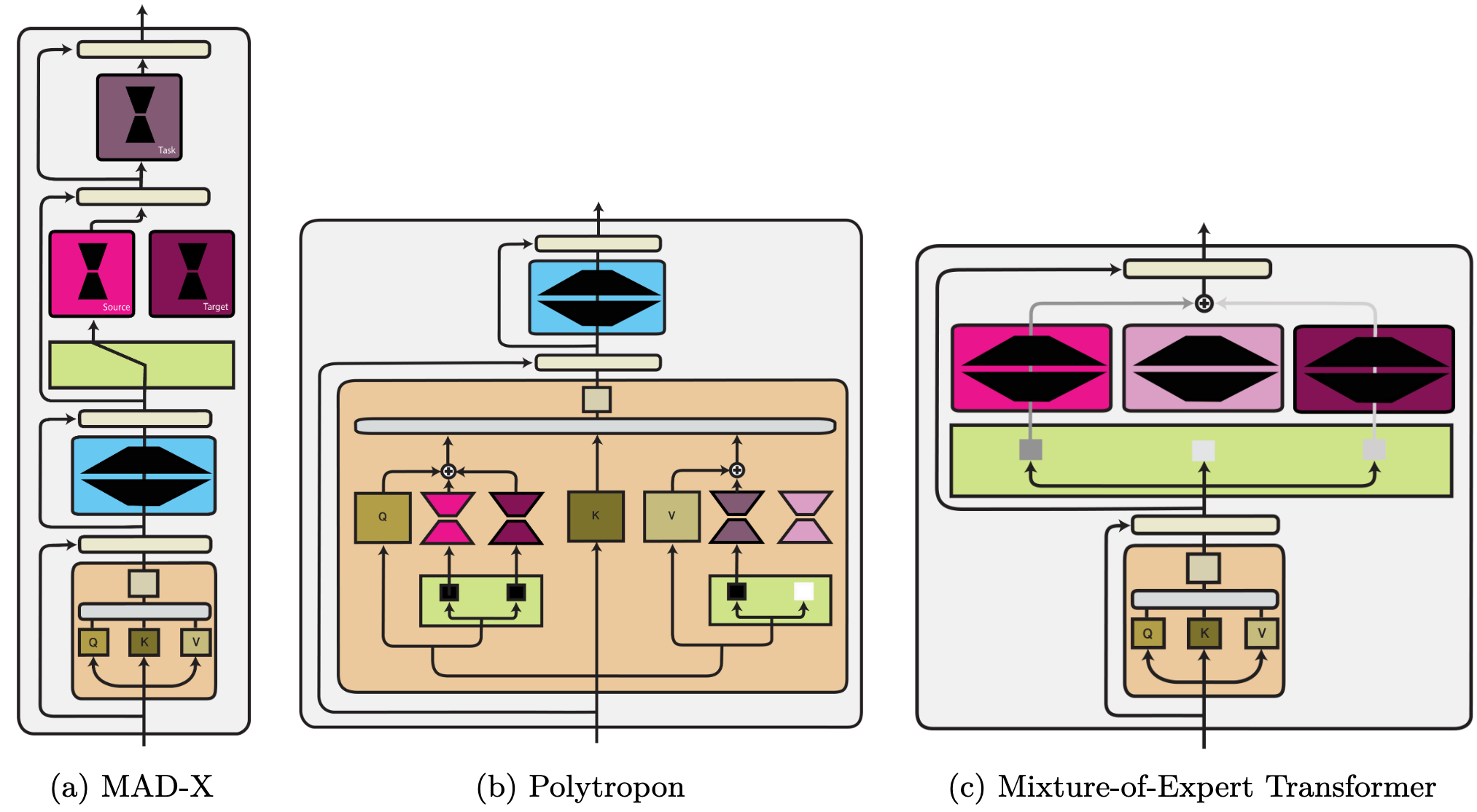
One of the readers of the newsletter sent me the following blog post about modular deep learning and it is very interesting research direction for foundational models.
It stars with the following problems to solve for the existing traditional Foundation Models:
Monolithic Bottlenecks: Traditional deep learning models are built as intricate, interconnected webs.
Limited Adaptability: Changing or fine-tuning specific functionalities often requires significant restructuring, hindering efficient development and customization.
Debugging Difficulties: Isolating and pinpointing issues within large, interconnected models can be a time-consuming and frustrating process.
Maintenance Burdens: As models grow and evolve, managing and maintaining their complex structures becomes increasingly challenging.
Transfer Learning's Dilemma: While transfer learning has democratized access to pre-trained models, fine-tuning them for multiple tasks can lead to:
Catastrophic Forgetting: When adapting a model to a new task, it may forget previously learned knowledge.
Negative Interference: Interactions between the pre-trained parts and the new task-specific components can impact performance negatively.
Then, the author argues the following properties of Modular Deep Learning can actually make some of the shortcomings of the foundational models go away.

Advantages of Modular Structure:
Separation of Concerns: Modularity proposes splitting models into smaller, independent modules, each responsible for a specific subtask or knowledge domain (e.g., a "word-embedding module" versus a "sentiment analysis module").
Benefits of Decomposition
Enhanced Adaptability: Individual modules can be swapped, replaced, or fine-tuned independently, catering to specific needs and avoiding complete model rebuilds.
Simplified Debugging: Isolating and troubleshooting issues becomes easier by focusing on individual modules.
Improved Maintainability: Modular structures are easier to manage and update, promoting sustainable model development.
Reduced Catastrophic Forgetting: Modular training allows for focusing on specific knowledge updates within modules, minimizing the risk of losing previously learned information.
Dimensions of Modularity can be applied in different dimensions:
Computation Function: Defines how data flows through the model, allowing for interchangeable modules like different attention mechanisms or encoders. Think of it as the "circuitry" of the modules.
Routing Function: Controls how information flows between modules, enabling flexible routing schemes and dynamic adaptation. Imagine this as the "traffic lights" directing information flows.
Aggregation Function: Determines how outputs from different modules are combined, providing flexibility in how knowledge is integrated. This acts as the "mixer" blending the outputs into a coherent representation.
Training Setting: Explores different approaches to train modular models, such as modular pre-training (training individual modules first) or joint training (training the entire system together). This is about the "construction crew" and how they build the modular system.
Benefits of Modularity:
Sustainable Model Development: Modular approaches encourage the development and sharing of reusable core components (e.g., language understanding modules) across different architectures and tasks. This fosters a collaborative and efficient ecosystem.
Democratizing AI Development: By breaking down complex models into smaller, well-defined units, modularity could shift AI development from centralized labs to a more distributed community effort, where individuals can contribute their expertise to specific modules.
Addressing Specific Challenges: Modularity can be tailored to tackle specific challenges in areas like multilingual NLP (where different language modules can be plugged in) or interpretability (where individual modules can be analyzed for their contributions to the overall output).

PyTorch team wrote a blog post on PyTorch 2.0 and how it brings a lot of performance gains to the training of a model in PyTorch. Specifically, the new feature through `torch.compile`, here are the performance gains that you can get:
Inference Speed:
JIT Compilation:
torch.compileuses Just-in-Time (JIT) compilation to convert PyTorch code into platform-specific machine code during inference. This eliminates the overhead of Python interpretation,leading to significant speedups.Kernel Fusion:
torch.compilefuses multiple operations into single, optimized kernels, reducing memory accesses and improving performance.Meta's Results: In Meta's production models, inference speed increased by up to 5x with
torch.compile.
Training Speed:
Autotuning:
torch.compileenables autotuning, searching for the optimal hardware configuration (e.g.,thread count, memory layout) for each operation. This improves efficiency by utilizing hardware resources optimally.Gradient Aggregation:
torch.compileoptimizes gradient aggregation, a key bottleneck in distributed training, leading to faster updates and overall training improvements.Meta's Results: While the blog doesn't specify exact figures, Meta reports a 2x improvement in training speed using
torch.compile.
2. Autotuning for Efficiency:
Online vs. Offline Tuning:
Online Tuning: This dynamic approach tunes configurations within the model execution itself, but can be time-consuming, especially for production models.
Offline Tuning: Meta developed a pre-run, offline tuning approach. It analyzes the model and hardware beforehand, generating optimal configurations for deployment, saving time and ensuring production stability.
3. Additional Features:
Quantization: PT2 supports various quantization techniques, reducing model size and accelerating inference on low-power devices.
Memory Management: PT2 improves memory allocation and deallocation, especially beneficial for large models on limited hardware.

Yang Song wrote an excellent blog post on some of the nice properties of score based generative models.
It motivates with the following problems to solve in GANs as of now:
Intractable Normalizing Constants: When working with GANs, calculating the probability density function (PDF) of real data is often necessary. This can be computationally expensive and impractical for complex datasets,hindering model scalability and efficiency.
Imagine trying to calculate the exact volume of a cloud - finding the surface area is easier, and score-based models take a similar approach.
Adversarial Training Instabilities: Training GANs involves a "cat-and-mouse" dynamic between a generator and a discriminator. This can be unstable, prone to mode collapse (generating repetitive, unrealistic samples), and sensitive to training hyperparameters.
Think of two kids building a tower from blocks, constantly knocking it down and rebuilding it to get better - score-based models skip the tower-building competition and directly focus on the final desired structure.
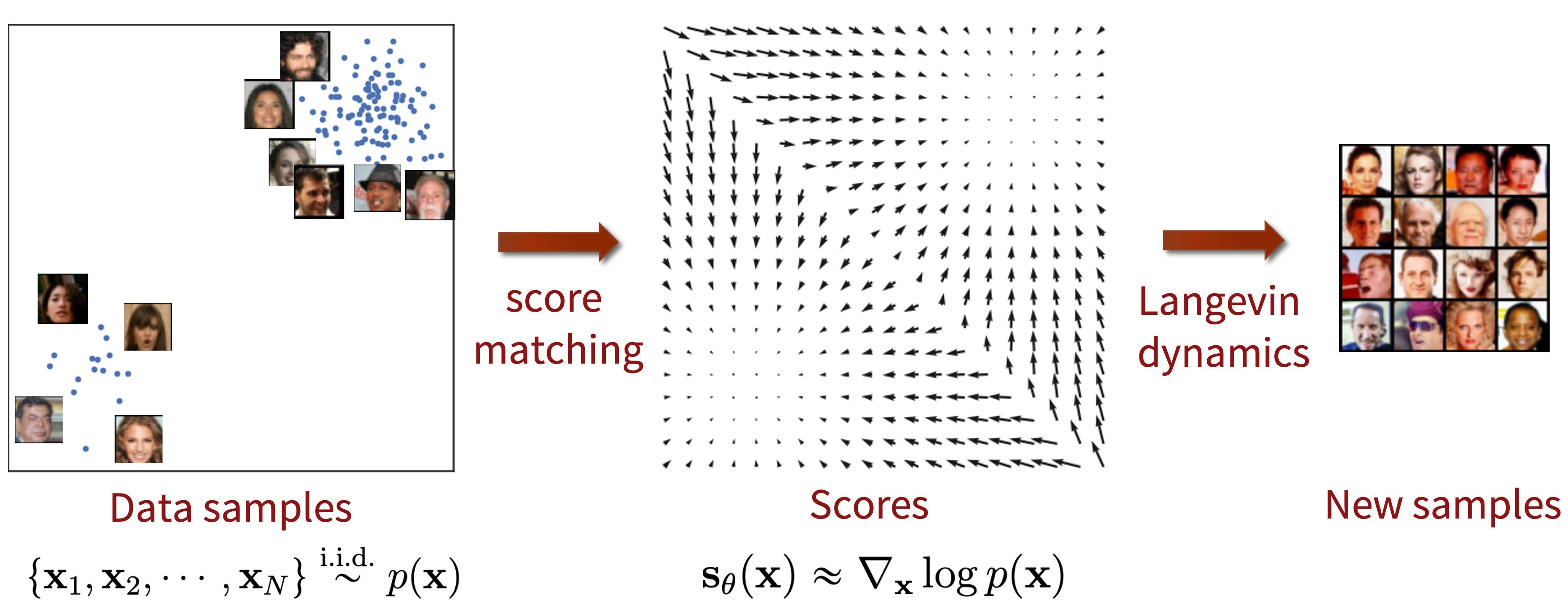
Score Based Property brings the following approach and benefits:
Shifting Focus from Densities to Scores: Instead of directly modeling the PDF, score-based models estimate the score function, which is the gradient of the log-PDF. This function tells you how much to change a current data point to make it look more "real" according to the underlying data distribution.
It's like having a map with arrows pointing towards areas with more real data - following these arrows leads you to realistic samples.
Benefits of the Score-Based Approach:
Sidestepping Intractable Densities: Estimating the score function doesn't require calculating the entire PDF,making it more computationally efficient and scalable for complex datasets.
No Adversarial Training: Score-based models remove the need for the cat-and-mouse game of GANs,leading to more stable training and reducing the risk of mode collapse.
Exact Likelihoods: Unlike GANs, score-based models can compute the exact likelihood of any data point,opening doors for precise model evaluation and data distribution analysis.
Results are very good, and I recommend checking them out as the author demonstrates the improvements in the images themselves.
Libraries
gpt-fast is a simple and efficient PyTorch native transformer text generation.
Featuring:
Very low latency
<1000 lines of python
No dependencies other than PyTorch and sentencepiece
int8/int4 quantization
Speculative decoding
Tensor parallelism
Supports Nvidia and AMD GPUs
LlamaIndex (GPT Index) is a data framework for your LLM application. LlamaIndex is a "data framework" to help you build LLM apps. It provides the following tools:
Offers data connectors to ingest your existing data sources and data formats (APIs, PDFs, docs, SQL, etc.)
Provides ways to structure your data (indices, graphs) so that this data can be easily used with LLMs.
Provides an advanced retrieval/query interface over your data: Feed in any LLM input prompt, get back retrieved context and knowledge-augmented output.
Allows easy integrations with your outer application framework (e.g. with LangChain, Flask, Docker, ChatGPT, anything else).

Platypus a family of fine-tuned and merged Large Language Models (LLMs) that achieves the strongest performance and currently stands at first place in HuggingFace's Open LLM Leaderboard as of the release date of this work. In this work they describe (1) their curated dataset Open-Platypus, that is a subset of other open datasets and which we release to the public (2) their process of fine-tuning and merging LoRA modules in order to conserve the strong prior of pretrained LLMs, while bringing specific domain knowledge to the surface (3) their efforts in checking for test data leaks and contamination in the training data, which can inform future research. Specifically, the Platypus family achieves strong performance in quantitative LLM metrics across model sizes, topping the global Open LLM leaderboard while using just a fraction of the fine-tuning data and overall compute that are required for other state-of-the-art fine-tuned LLMs. In particular, a 13B Platypus model can be trained on a single A100 GPU using 25k questions in 5 hours. This is a testament of the quality of their Open-Platypus dataset, and opens opportunities for more improvements in the field.
LLM-Benchmark-Logs is dedicated to documenting and organizing benchmarks performed on various Foundational Large Language Models and their Fine-tunes.
The main content of this repository is plaintext files containing detailed benchmark results. These files provide a comprehensive record of the performance characteristics of different LLMs under various conditions and workloads.

LAyer-SElective Rank-Reduction, abbreviated as LASER, is an intervention where we replace a selected weight matrix in the transformer architecture of an LLM with its low-rank approximation. A single LASER transformation consists of 3 hyperparameters: the layer number to modify (ℓ) such as 16th layer, the parameter type (τ) such as the first MLP layer, and the fraction of the maximum rank to retain (ρ) such as 0.01 fraction of the rank. We can write this transformation as (ℓ, τ, ρ) and we can compose these transformations and apply them in parallel. The low-rank approximation is performed using SVD. The code is available in GitHub.
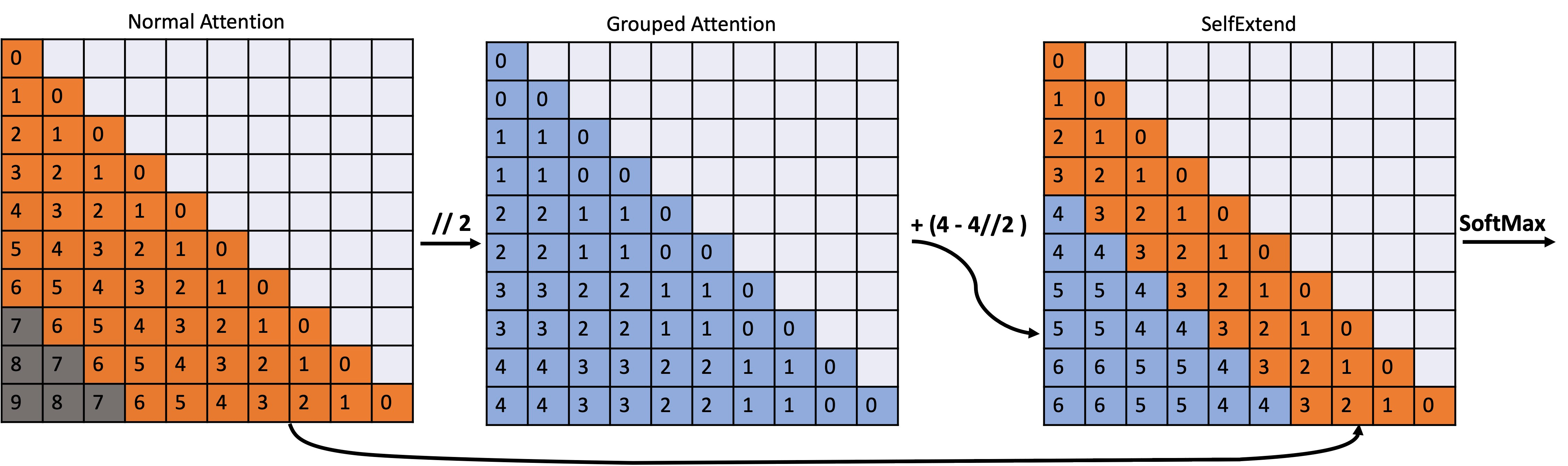
LongLM elicits LLMs' inherent ability to handle long contexts without fine-tuning. The limited length of the training sequence during training may limit the application of Large Language Models (LLMs) on long input sequences for inference. The authors argue that existing LLMs themselves have inherent capabilities for handling long contexts. They suggest extending LLMs' context window by themselves to fully utilize the inherent ability. In order to do so, they are proposing self-Extend to stimulate LLMs' long context handling potential. The basic idea is to construct bi-level attention information: the group level and the neighbor level. The two levels are computed by the original model's self-attention, which means the proposed does not require any training.

DeepVariant is a deep learning-based variant caller that takes aligned reads (in BAM or CRAM format), produces pileup image tensors from them, classifies each tensor using a convolutional neural network, and finally reports the results in a standard VCF or gVCF file.
DeepVariant supports germline variant-calling in diploid organisms.
NGS (Illumina or Element) data for either a whole genome or whole exome.
RNA-seq Case Study for Illumina RNA-seq.
PacBio HiFi data, see the PacBio case study.
Oxford Nanopore R10.4.1 Simplex or Duplex data, see the ONT R10.4.1 Simplex case study and ONT R10.4.1 Duplex case study.
Hybrid PacBio HiFi + Illumina WGS, see the hybrid case study.
Oxford Nanopore R9.4.1 data by using PEPPER-DeepVariant.
To map using a pangenome to improve accuracy, use this vg case study.
Complete Genomics data: T7 case study; G400 case study
Classes
Transformers United is an excellent Seminar like class from Stanford, and here is a playlist in YT that allows you to navigate the classes in order.