Model Safety at Uber
Skyvern, PyScripter and Argilla


Uber wrote a good article on how they are raising the bar on the model deployment by implementing a number of different checks and balances for model quality through some of the MLOps practices.
Uber’s centralized ML platform called Michelangelo, which supports over 400 use cases, executes more than 20,000 training jobs monthly, and serves 15 million predictions per second during peak load. In such an environment, even minor degradations in model quality can ripple out rapidly, making “silent failures” or subtle regressions dangerous and hard to detect. Unlike conventional code, ML systems are deeply probabilistic and tightly coupled to their ever-changing data sources, rendering static code tests insufficient for reliability.
In order to provide high safety standards in such an environment, Uber adopts various principles and adopts methods to improve their operational efficiency and operate the systems in a reliable manner.
Main principles that they have adopted:
Data and Code as Artifacts: Every ML model is fundamentally dependent on its source data and code — both are equally critical in determining system reliability and are targets for silent failures.
End-to-end Safeguards: Effective safety requires embedding protections at every stage — feature engineering, model training, pre-production validation, and post-deployment monitoring.
Automation and Actionability: Safeguards are coupled with automated mechanisms (alerts, rollout gates, instant rollbacks) that act instantly when anomalies or regressions are detected.
These principles provide both deployment safety and mitigation strategies in case something goes wrong post-deployment.
After the principles, the post is almost like a summary of what a good MLOps book should cover in terms of four categories with regards to ML Lifecycle:
1. Data and Feature Engineering
The earliest line of defense is ensuring feature-level consistency:
Null Handling: Uber enforces consistent representation of nulls and requires identical imputation logic in both training and serving. This eliminates subtle sources of schema or value drift.
Schema Validation: Michelangelo’s pipelines automatically check data schemas for type mismatches, distribution shifts, and cardinality changes before they affect downstream systems.
2. Model Training and Operational Robustness
Training is tightly linked with operational baselines:
Distributional Statistics: Offline training computes and records key statistics (percentiles, averages, null rates) for every numerical feature.
Latency Budgets: All model architectures are vetted against strict latency budgets to ensure serving environments remain performant.
Standardized Reporting: Each run produces model reports containing data-quality metrics, feature-importance rankings, and core performance stats—these are the basis for “deployment readiness” reviews.
3. Robust pre-Production Validation
Backtesting: Models are validated against historical production data to catch regressions invisible in aggregate metrics.
Shadow Testing: Most critical use cases undergo “shadow” deployments, in which new models run in parallel with production, feeding on the same live input—outputs are compared in real time, but only the production model affects users. This is increasingly required by default for online models.
4. Safe and Controlled Rollout
Phased Rollout: Models are first deployed to a “traffic slice” with continuous monitoring. Any breach of error, latency, or resource thresholds triggers auto-rollback to the last approved version.
Fallback Plans: Every rollout includes predefined fallback and contingency measures to ensure business continuity.
Monitoring & Observability
For monitoring and observability, they use extensively Hue to both monitor and create alerts on the operational metrics such as availability, latency as well as prediction or model quality metrics such as calibration, entropy.
Operational Metrics: Availability, latency, throughput.
Prediction Metrics: Score distributions, calibration, entropy.
Feature Health: Null rates, drift detection via statistical tests, online-offline feature parity checks.
Automated Alerts and Promotion Gates: If thresholds are breached (especially in high-risk cases), promotions can be blocked autonomously until remediated.
“Hue” System: Separates data profiling from monitoring so teams can compare live and historical feature distributions, supporting slicing and debugging at Uber scale (Flink and Pinot power this stream analytics).
Automated data-quality checks, system monitoring, and gradual rollout with rollback are default for every model.
Continuous “offline” and “real-time” validation, plugged seamlessly into Michelangelo, rapidly highlights regressions—this means issues that once took days to be detected now surface in hours or less.

Model Safety Deployment Scoring: Uber tracks four key aspects for each model family:
Offline evaluation coverage
Shadow deployment coverage
Unit-test coverage (for both monorepo and new lines)
Active monitoring and alerting coverage
These metrics form a transparent safety score showing a family’s overall readiness for deployment, driving continuous improvement and adoption.
Libraries

Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows on a large number of websites, replacing brittle or unreliable automation solutions.
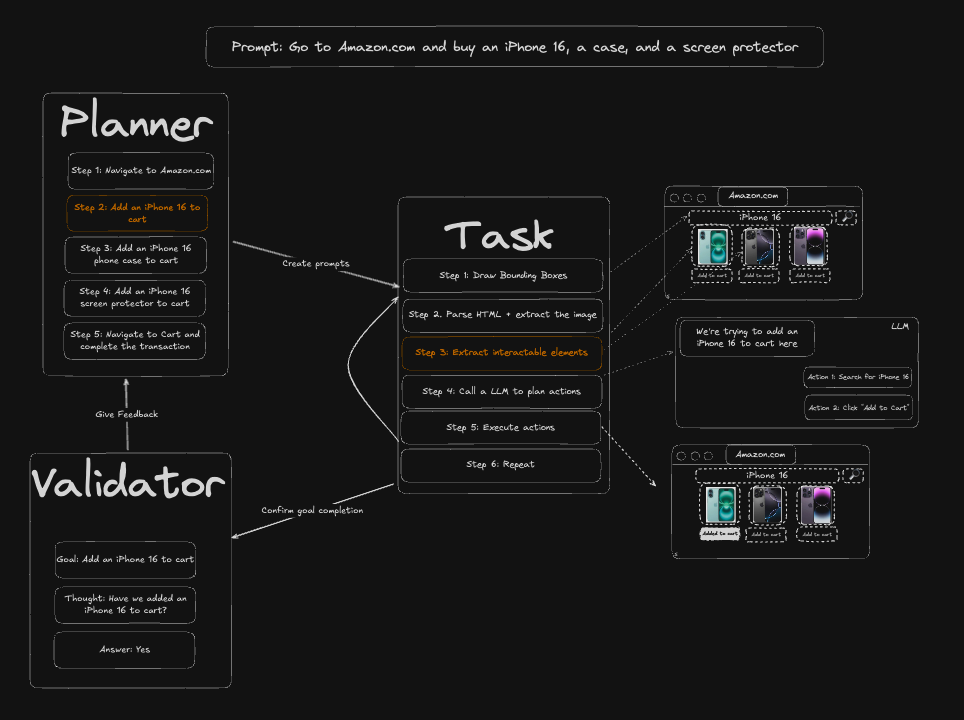
Skyvern was inspired by the Task-Driven autonomous agent design popularized by BabyAGI and AutoGPT -- with one major bonus: we give Skyvern the ability to interact with websites using browser automation libraries like Playwright.
This approach has the following advantages:
Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code
Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate
Skyvern is able to take a single workflow and apply it to a large number of websites, as it’s able to reason through the interactions necessary to complete the workflow
Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include:
If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16
If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff
Pico-Banana-400K is a large-scale dataset of ~400K text–image–edit triplets designed to advance research in text-guided image editing.
Each example contains:
an original image (from Open Images),
a human-like edit instruction, and
the edited result generated by Nano-Banana and verified by Gemini-2.5-Pro.
The dataset spans 35 edit operations across 8 semantic categories, covering diverse transformations—from low-level color adjustments to high-level object, scene, and stylistic edits.
MSCCL is an inter-accelerator communication framework that is built on top of NCCL and uses its building blocks to execute custom-written collective communication algorithms. MSCCL vision is to provide a unified, efficient, and scalable framework for executing collective communication algorithms across multiple accelerators.
NVIDIA Inference Xfer Library (NIXL) is targeted for accelerating point to point communications in AI inference frameworks such as NVIDIA Dynamo, while providing an abstraction over various types of memory (e.g., CPU and GPU) and storage (e.g., file, block and object store) through a modular plug-in architecture.
DeepEP is a communication library tailored for Mixture-of-Experts (MoE) and expert parallelism (EP). It provides high-throughput and low-latency all-to-all GPU kernels, which are also known as MoE dispatch and combine. The library also supports low-precision operations, including FP8.
Below the Fold

LightlyStudio is an open-source tool designed to unify your data workflows from curation, annotation and management in a single tool. You can work with COCO and ImageNet on a Macbook Pro with M1 and 16GB of memory!

PyScripter is a free and open-source Python Integrated Development Environment (IDE) created with the ambition to become competitive in functionality with commercial Windows-based IDEs available for other languages.

Katakate aims to make it easy to create, manage and orchestrate lightweight safe VM sandboxes for executing untrusted code, at scale. It is built on battle-tested VM isolation with Kata, Firecracker and Kubernetes. It is orignally motivated by AI agents that need to run arbitrary code at scale but it is also great for:
Custom serverless (like AWS Fargate, but yours)
Hardened CI/CD runners (no Docker-in-Docker risks)
Blockchain execution layers for AI dApps

Argilla is a collaboration tool for AI engineers and domain experts who need to build high-quality datasets for their projects.

Trailbase is an open, blazingly fast, single-executable Firebase alternative with type-safe REST & realtime APIs, built-in WebAssembly runtime, SSR, auth and admin UI built on Rust, SQLite & Wasmtime.
Simplify with fewer moving parts: an easy to self-host, single-executable, extensible backend for your mobile, web or desktop application. Sub-millisecond latencies eliminate the need for dedicated caches, no more stale or inconsistent data.