MLOps::Relational Inductive Biases

Articles
If consistency with the training instances is taken as the sole determiner of appropriate generalizations, then a program can never make the inductive leap necessary to classify instances beyond those it has observed. Only if the program has other sources of information, or biases for choosing one generalization over the other, can it non-arbitrarily classify instances beyond those in the training set....
The impact of using a biased generalization language is clear: each subset of instances for which there is no expressible generalization is a concept that could be presented to the program, but which the program will be unable to describe and therefore unable to learn. If it is possible to know ahead of time that certain subsets of instances are irrelevant, then it may be useful to leave these out of the generalization language, in order to simplify the learning problem. ...
Although removing all biases from a generalization system may seem to be a desirable goal, in fact the result is nearly useless. An unbiased learning system’s ability to classify new instances is no better than if it simply stored all the training instances and performed a lookup when asked to classify a subsequent instance.
Tom M. Mitchell, The Need for Biases in Learning Generalizations
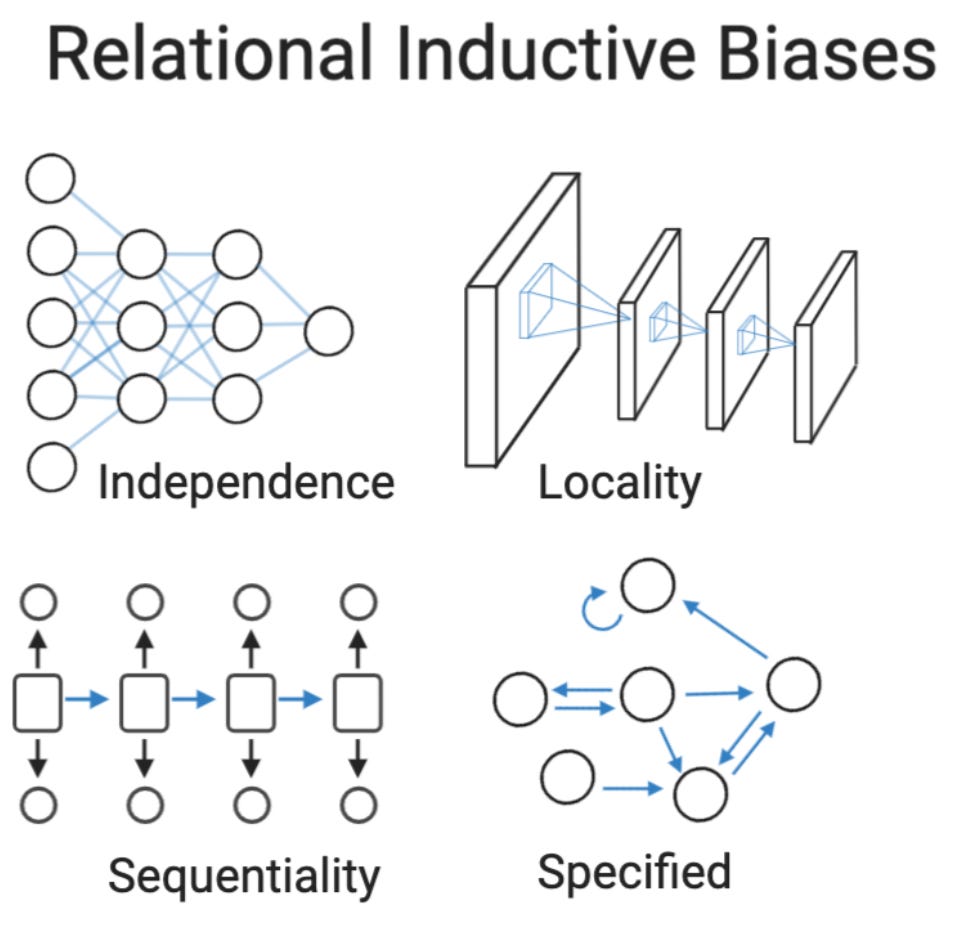
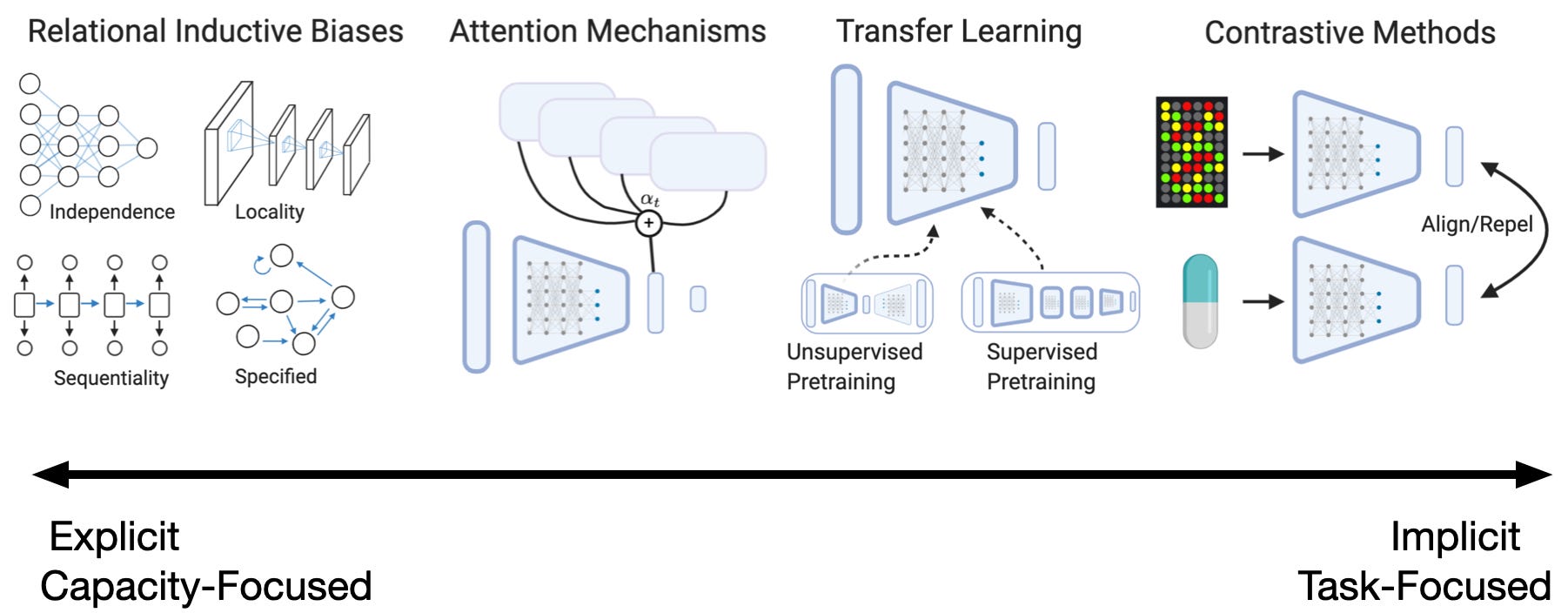
Incredibly well written article on inductive biases with a focus on deep learning methods. It starts why inductive bias is needed for machine learning by giving an excerpt from above. Then, it talks about other types of inductive biases that can be introduced in different types of machine learning techniques such as k-means clustering. After that, the bigger portion of the article is reserved for various deep learning techniques and how these techniques are using various inductive biases even for representation learning techniques.

NYTimes wrote about how they built their recommendation engines to recommend various articles. They use universal sentence encoder to get embedding representation of text and they formulate overall classification of the articles as multi-label text classification problem.
Libraries
Sagify is a command line utility tool to accelerate the deployments of machine learning models in SageMaker in AWS.
Dex is a new research language for machine learning from ML/Haskell family.
MLCube which is part of MLCommons is another Kubeflow like framework which interprets various machine learning components into tasks and build various pipelines. The basic premise is very simple and sought after: to build reliable machine learning flows that can be easily put into production. It is built on Docker and very similar to Kubeflow(yaml for “tasks” and execution). You can also build pipelines on different types of platforms if you want to distinguish different type of hardware or vendor that you want to run the pipelines. Its code is also available in PIP.
Papers
Studying Catastrophic Forgetting in Neural Ranking Models talks about transfer learning and how transfer learning may be detrimental for ranking problems as a fine-tune step and how to prevent these “catastrophic” forgetting.
ICLR 2021 published all of the papers that are accepted.
Google published a knowledge distillation paper. Unlike traditional knowledge distillation techniques, they propose to distill the knowledge human readable programs. Specifically, they are distilling a machine learning model into a piece-wise linear functions.
Most of the machine learning research do not focus on the datasets themselves. Datasets are generally considered to be tools for “benchmark”ing to compare various algorithms and techniques. Of course, this way of thinking is problematic for one that datasets themselves have “bias”es which may shadow some of the issues in the algorithms from fairness point of view. This paper shows some of the pitfalls of datasets and how one should think
Notebooks
Catalyst has a nice notebook that demonstrates end to end a machine learning flow. It shows how to log various metrics, implement custom metrics and create various experiments.
Codalab has an interesting approach to reproducible research. Instead of publishing the paper, code and other materials separately. They aim to combine them altogether in worksheets to be able to reproduce different steps in the paper along with the code and data that can produce the same results within the paper. The worksheet list has a number of interesting papers in the form of “worksheets”. It is great to see companies innovate on the notebook format to even further improve the reproducibility in research.
Classes
Lena Voita has an introductory Natural Language Processing class that has good notebooks that explain various aspects in an applied/hands-on materials. Sequence to Sequence notebook is pretty good and has nice articles around Convolutional Neural Networks. All of the material for the class is available in here.
Cornell tech has an Applied Machine Learning class in YouTube. It is modern(covers recent neural network architectures as part of the class) unlike most of the machine learning classes that you found on the web. It starts with introductory/basic classes and build up on top of a good base.