MLE-STAR* from Google to Automate all things ML Related!
*Machine Learning Engineering via Search and Targeted Refinement

Articles

Google wrote about a new agent framework for solving common machine learning tasks called MLE-STAR,(Machine Learning Engineering via Search and Targeted Refinement) which is a general multi-agent framework for building automated machine learning engineering agents that can generate complete ML solutions from task descriptions and datasets end to end.
The research mainly addresses critical limitations in existing Large Language Model (LLM)-based MLE agents, which rely heavily on internal LLM knowledge and employ coarse exploration strategies that modify entire code structures at once, limiting their ability to select effective task-specific models and perform deep exploration within specific components. This all or nothing approach does not build an iterative solution and sometimes it is ineffective of solving a subcomponent of a problem.
This research addresses some of the limitations through general(not task specific) multi-agent framework that distinguishes from AutoML type of approaches where the search space is much more limited and have to be very well defined(both in terms of problem statement and a possible solution among all of the possible paths).
Web Search
One of the main advantage of MLE-STAR's integration of web search as a tool for retrieving state-of-the-art models is ability to fetch the most of the recent information about a particular problem rather than solely depending on LLM's internal knowledge. This addresses the common problem where LLMs propose outdated models (like logistic regression for text classification tasks) due to bias toward familiar patterns from pre-training data. This also becomes common for reasoning tasks especially for research oriented and study oriented tasks where model does not have all of the information that is trained on, but can use the information at the “test time” to reason about and curate a good answer even though it does not necessarily know this information in the “training time”.
In order to do that, they have the following execution path:
Uses Google Search to retrieve M effective models for given tasks
Retrieves both model descriptions (
T_model) and corresponding example code (T_code)A retriever agent (
A_retriever) generates structured JSON outputs containing model informationRetrieved models are evaluated by a candidate evaluation agent (
A_init) that generates executable Python scripts
Refinement
Unlike existing approaches that modify entire code structures, MLE-STAR introduces a nested loop refinement system that targets specific ML pipeline components.
Outer Loop - Component Identification:
Performs ablation studies using an ablation study agent (
A_abl) to identify which code blocks have the most significant impact on performanceA summarization module (
A_summarize) processes ablation resultsAn extractor module (
A_extractor) identifies the critical code block (c_t) for refinement and generates initial plans (p_0)
Inner Loop - Iterative Refinement:
A coding agent (
A_coder) implements refinement plansA planning agent (
A_planner) proposes new strategies based on performance feedback from previous attemptsProcess continues for K iterations, selecting the best-performing candidate
Outer loop repeats T times targeting different critical code blocks
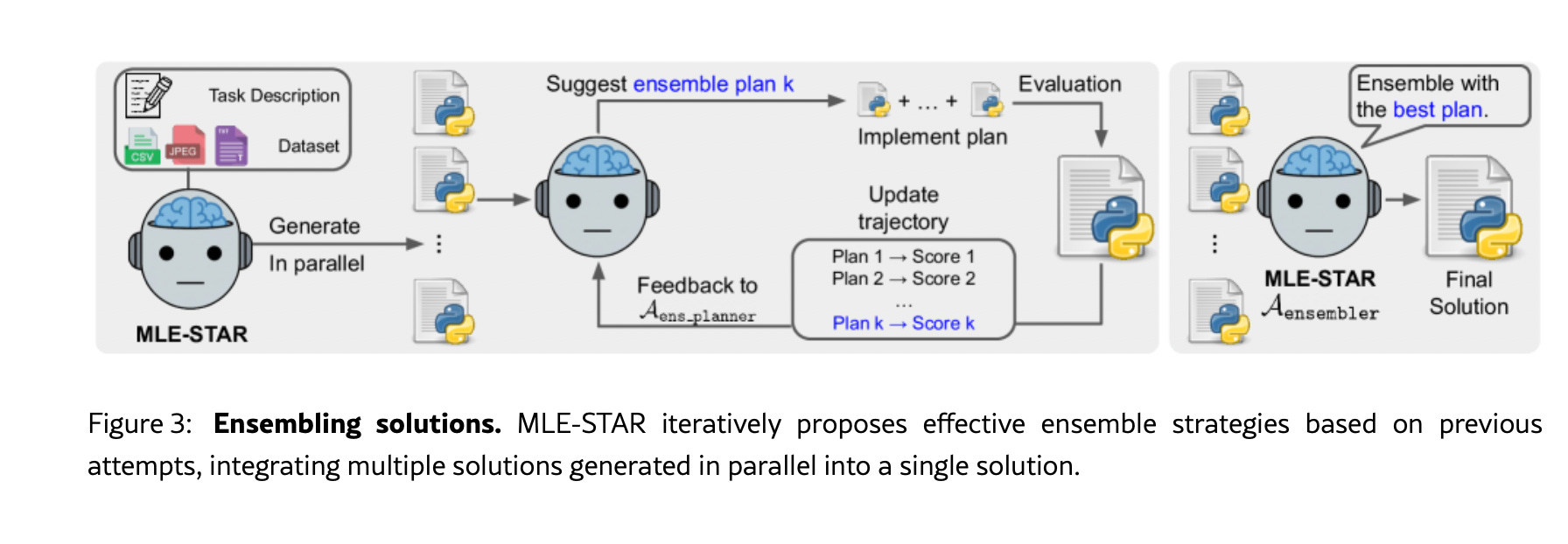
3. Orchestration of Ensemble Selection
MLE-STAR has an ensemble method that goes beyond simple voting or averaging. Instead of selecting the single best solution, it follows:
Generates multiple candidate solutions from parallel runs
Uses an ensemble strategy planner (A_ens_planner) to propose effective combination methods
An ensembler agent (A_ensembler) implements these strategies
Iteratively refines ensemble approaches based on performance feedback over R iterations
Through this, it can optimize the selection after multiple possible paths and solutions are proposed and still optimize these paths through the ensembler agent.
If we were to summarize this multi-agent system, we can outline 13 specialized agents that interact with each other with slightly different objective functions while optimizing the problem at the hand(problem definition is in the next section):
Retriever Agent (A_retriever): Searches web for relevant models
Candidate Evaluation Agent (A_init): Generates and evaluates initial solutions
Merging Agent (A_merger): Combines multiple models into initial solution
Ablation Study Agent (A_abl): Creates ablation study code for component analysis
Summarization Agent (A_summarize): Processes ablation study results
Extractor Agent (A_extractor): Identifies critical code blocks for refinement
Coder Agent (A_coder): Implements code refinements
Planner Agent (A_planner): Proposes refinement strategies
Ensemble Strategy Planner (A_ens_planner): Plans ensemble combinations
Ensembler Agent (A_ensembler): Implements ensemble strategies
Debugging Agent (A_debugger): Fixes code execution errors
Data Leakage Checker (A_leakage): Prevents test data contamination
Data Usage Checker (A_data): Ensures all provided data is utilized
Problem Formulation
The system formally defines the optimization problem as finding s* = argmax(h(s)), where S is the space of possible Python script solutions and h is a performance score function. The multi-agent framework takes datasets D and task descriptions T_task as input, working across any data modalities (tabular, image, text, audio) and task types (classification, regression, sequence-to-sequence).
Experiments were conducted on 22 Kaggle competitions from MLE-bench Lite, using Gemini-2.0-Flash and Gemini-2.5-Pro as base models. The system retrieves 4 model candidates, performs 4 inner refinement loops across 4 outer loops, and explores ensemble strategies for 5 rounds within a 24-hour time limit.
Medal Achievement Rates:
MLE-STAR with Gemini-2.5-Pro: 63.6% medal achievement rate (36.4% gold medals)
MLE-STAR with Gemini-2.0-Flash: 43.9% medal achievement rate (30.3% gold medals)
AIDE baseline with Gemini-2.0-Flash: 25.8% medal achievement rate (12.1% gold medals)
This represents an 18+ percentage point improvement in overall medal achievement and a 147% improvement in gold medal achievement over the best baseline.
The paper also has a lot more details on agents as well as the benchmarks.
Libraries

TinyTroupe is an experimental Python library that allows the simulation of people with specific personalities, interests, and goals. These artificial agents - TinyPersons - can listen to us and one another, reply back, and go about their lives in simulated TinyWorld environments. This is achieved by leveraging the power of Large Language Models (LLMs), notably GPT-4, to generate realistic simulated behavior. This allows us to investigate a wide range of convincing interactions and consumer types, with highly customizable personas, under conditions of our choosing. The focus is thus on understanding human behavior and not on directly supporting it (like, say, AI assistants do) -- this results in, among other things, specialized mechanisms that make sense only in a simulation setting. Further, unlike other game-like LLM-based simulation approaches, TinyTroupe aims at enlightening productivity and business scenarios, thereby contributing to more successful projects and products. Here are some application ideas to enhance human imagination:
Advertisement: TinyTroupe can evaluate digital ads (e.g., Bing Ads) offline with a simulated audience before spending money on them!
Software Testing: TinyTroupe can provide test input to systems (e.g., search engines, chatbots or copilots) and then evaluate the results.
Training and exploratory data: TinyTroupe can generate realistic synthetic data that can be later used to train models or be subject to opportunity analyses.
Product and project management: TinyTroupe can read project or product proposals and give feedback from the perspective of specific personas (e.g., physicians, lawyers, and knowledge workers in general).
Brainstorming: TinyTroupe can simulate focus groups and deliver great product feedback at a fraction of the cost!
Torchleet is a leetcode for Pytorch. TorchLeet is broken into two sets of questions:
Question Set: A collection of PyTorch practice problems, ranging from basic to hard, designed to enhance your skills in deep learning and PyTorch.
LLM Set: A new set of questions focused on understanding and implementing Large Language Models (LLMs) from scratch, including attention mechanisms, embeddings, and more.

Positron is:
A next-generation data science IDE built by Posit PBC
An extensible, polyglot tool for writing code and exploring data
A familiar environment for reproducible authoring and publishing

Arch handles the pesky low-level work in building agentic apps — like applying guardrails, clarifying vague user input, routing prompts to the right agent, and unifying access to any LLM. It’s a language and framework friendly infrastructure layer designed to help you build and ship agentic apps faster.
🌐 MCP-Use is the open source way to connect any LLM to any MCP server and build custom MCP agents that have tool access, without using closed source or application clients.
💡 Let developers easily connect any LLM to tools like web browsing, file operations, and more.
If you want to get started quickly check out mcp-use.com website to build and deploy agents with your favorite MCP servers.
Visit the mcp-use docs to get started with mcp-use library
For the TypeScript version, visit mcp-use-ts
Below The Fold
any-llm is a single interface to use different llm providers from Mozilla, which offers:
Simple, unified interface - one function for all providers, switch models with just a string change
Developer friendly - full type hints for better IDE support and clear, actionable error messages
Leverages official provider SDKs when available, reducing maintenance burden and ensuring compatibility
Stays framework-agnostic so it can be used across different projects and use cases
Actively maintained - we use this in our own product (any-agent) ensuring continued support
No Proxy or Gateway server required so you don't need to deal with setting up any other service to talk to whichever LLM provider you need.

RisingWave is a stream processing and management platform designed to offer the simplest and most cost-effective way to process, analyze, and manage real-time event data — with built-in support for the Apache Iceberg™ open table format. It provides both a Postgres-compatible SQL interface and a DataFrame-style Python interface.
RisingWave can ingest millions of events per second, continuously join and analyze live streams with historical data, serve ad-hoc queries at low latency, and persist fresh, consistent results to Apache Iceberg™ or any other downstream system.
Manticore Search is an easy-to-use, open-source, and fast database designed for search. It is a great alternative to Elasticsearch.
vet is a command-line tool that acts as a safety net for the common but risky curl | bash pattern. It lets you inspect remote scripts for changes, run them through a linter, and require your explicit approval before they can execute.
libpostal is a C library for parsing/normalizing street addresses around the world using statistical NLP and open data. The goal of this project is to understand location-based strings in every language, everywhere. For a more comprehensive overview of the research behind libpostal, be sure to check out the (lengthy) introductory blog posts:
Original post: Statistical NLP on OpenStreetMap
Follow-up for 1.0 release: Statistical NLP on OpenStreetMap: Part 2

Jujutsu is a powerful version control system for software projects. You use it to get a copy of your code, track changes to the code, and finally publish those changes for others to see and use. It is designed from the ground up to be easy to use—whether you're new or experienced, working on brand new projects alone, or large scale software projects with large histories and teams.
Jujutsu is unlike most other systems, because internally it abstracts the user interface and version control algorithms from the storage systems used to serve your content. This allows it to serve as a VCS with many possible physical backends, that may have their own data or networking models—like Mercurial or Breezy, or hybrid systems like Google's cloud-based design, Piper/CitC.
Notesnook is a free (as in speech) & open-source note-taking app focused on user privacy & ease of use.
Notesnook is our proof that privacy does not (always) have to come at the cost of convenience. We aim to provide users peace of mind & 100% confidence that their notes are safe and secure. The decision to go fully open source is one of the most crucial steps towards that.

ZUSE is a sleek, minimal IRC client for your terminal. Built with Go and powered by the elegant Bubble Tea framework. Chat faster, cleaner, and without distractions right from your terminal.