
Articles

Deepmind published a blog post where they introduce a single visual language model(VLM) Flamingo, that sets a new state of the art in few-shot learning on a wide range of open-ended multimodal tasks. This means Flamingo can tackle a number of difficult problems with just a handful of task-specific examples (in a “few shots”), without any additional training required. Flamingo’s simple interface makes this possible, taking as input a prompt consisting of interleaved images, videos, and text and then output associated language.

Socratic Models (SMs), a framework that uses structured dialogue between pre-existing foundation models, each of which can exhibit unique (but complementary) capabilities depending on the distributions of data on which they are trained.
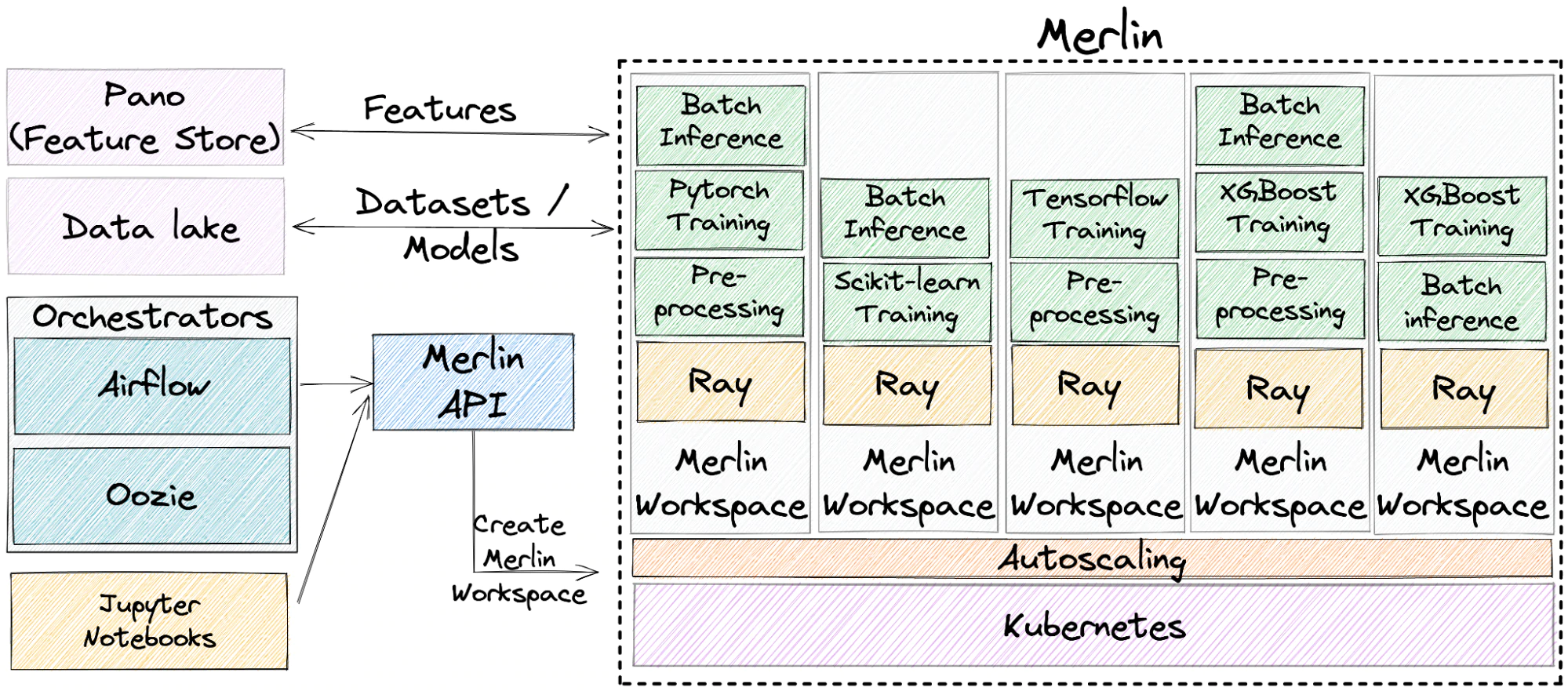
Shopify wrote about their ML Platform in this blog post. They use Kubernetes as the base of their ML Infrastructure and Merlin supports a variety of different use cases for different types of machine learning flows. They use Ray to scale up the machine learning workflows as the applications are in Python.


Linkedin announced that they open-sourced their feature store engine in this post. Feathr is built to simplify machine learning (ML) feature management and improve developer productivity. At LinkedIn, dozens of applications use Feathr to define features, compute them for training, deploy them in production, and share them across teams. With Feathr, users reported significantly reduced time required to add new features to model training workflows and improved runtime performance compared to previous application-specific feature pipeline solutions.
Libraries
PE-Former is a pure transformer architecture (no CNN backbone) for 2D body pose estimation. It uses an encoder-decoder architecture with a vision transformer as an encoder and a transformer decoder (derived from DETR).
Recon NER is a library to help you fix your annotated NER data and identify examples that are hardest for your model to predict so you can strategically prioritize the examples you annotate. It supports the following features:
Data Validation and Cleanup: Easily Validate the format of your NER data. Filter overlapping Entity Annotations, fix missing properties.
Statistics: Get statistics on your data. From how many annotations you have for each label, to more complicated metrics like quality scores for the balance of your dataset.
Model Insights: Analyze how well your model does on your Dataset. Identify the top errors your model is making so you can prioritize data collection and correction strategically.
Dataset Management: Recon provides
DatasetandCorpuscontainers to manage the train/dev/test split of your data and apply the same functions across all splits in your data + a concatenation of all examples. Operate inplace to consistently transform your data with reliable tracking and the ability to version and rollback changes.Serializable Dataset: Serialize and Deserialize your data to and from JSON to the Recon type system.
Type Hints: Comprehensive Typing system based on Python 3.7+ Type Hints
zsh-codex is a command line utility that you can use in terminal to write natural language to accomplish a number of tasks.
Archai is a platform for Neural Network Search (NAS) that allows you to generate efficient deep networks for your applications. Archai aspires to accelerate NAS research by enabling easy mix and match between different techniques while ensuring reproducibility, self-documented hyper-parameters and fair comparison. To achieve this, Archai uses a common code base that unifies several algorithms. Archai is extensible and modular to allow rapid experimentation of new research ideas and develop new NAS algorithms. Archai also hopes to make NAS research more accessible to non-experts by providing powerful configuration system and easy to use tools.
Convnext has the next generation of ConvNet architecture that implements the following paper in PyTorch.
Stumpy is a scalable library that efficiently computes something called the matrix profile, which can be used for a variety of time series data mining tasks such as:
pattern/motif (approximately repeated subsequences within a longer time series) discovery
anomaly/novelty (discord) discovery
shapelet discovery
semantic segmentation
streaming (on-line) data
fast approximate matrix profiles
time series chains (temporally ordered set of subsequence patterns)
snippets for summarizing long time series
pan matrix profiles for selecting the best subsequence window size(s)
Books
Algorithms for Decision Making talks about various different algorithms for traditional machine learning methods and gives a good amount of explanation on their mathematical background, advantages and disadvantages.