

Mechanistic Interpretability, Linear Representation Hypothesis, Sparse AutoEncoders and All That
Because somebody has to explain how LLM works!

Articles
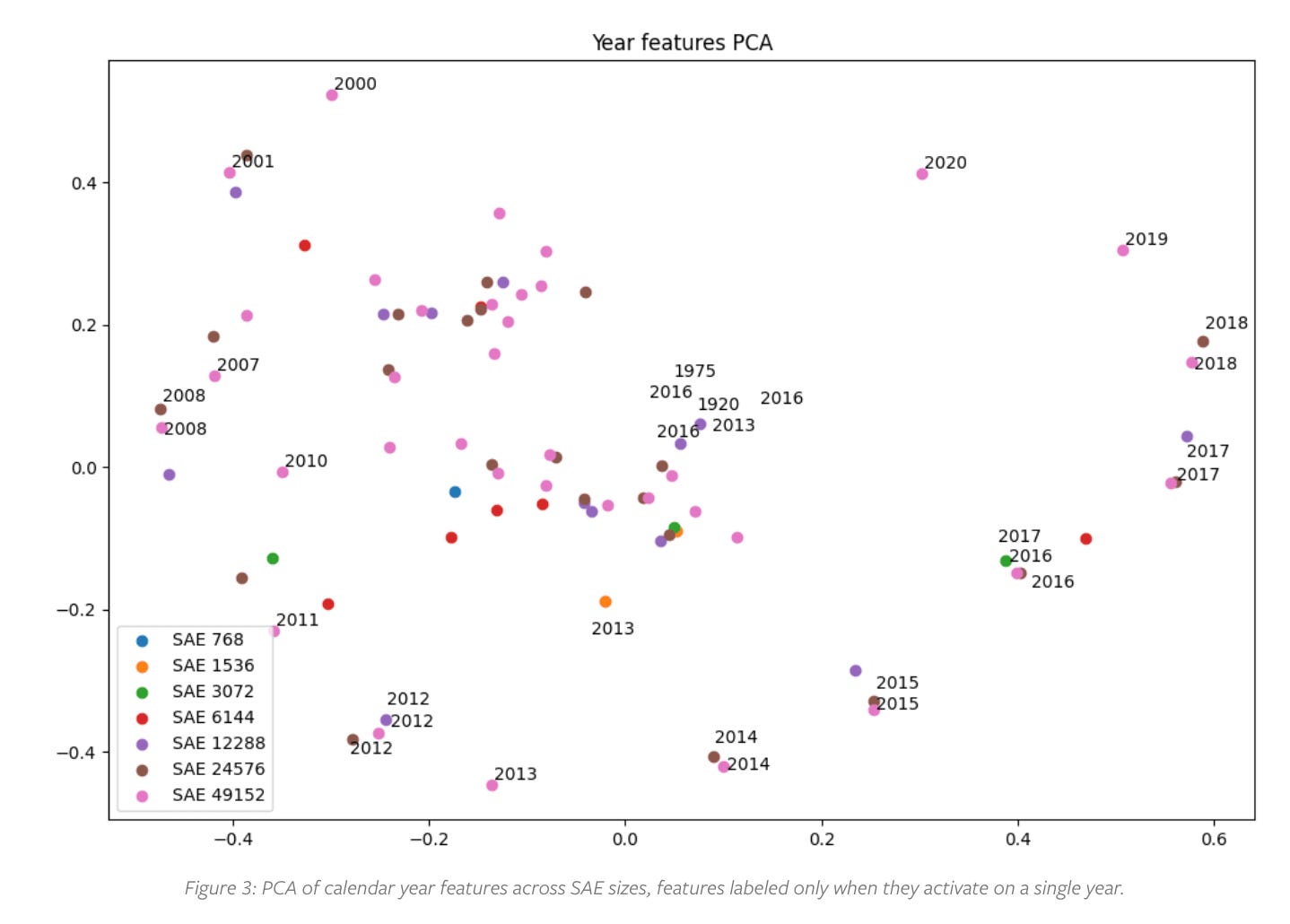
Following last week’s newsletter, I wanted to learn more about the feature analysis and especially interpretability of the model more and found an excellent post form AlignmentForum about the mechanistic interpretability of the GPT-2 model, focusing on how it represents and processes calendar-related information. The post goes into details on the geometry of the residual stream in layer 8 of GPT-2, aiming to understand how the model encodes and manipulates date-related features.
Before getting started, the phrase of “mechanistic interpretability(MI)” refers to the internal workings of neural networks by examining how specific features are represented and processed. It is mouthful, but simple term.
In this particular post, MI involves analyzing how the model encodes linguistic and factual information, including concepts like dates and times.
They use layer 8 of GPT-2. The choice of this layer is based on previous research indicating that it plays a significant role in processing date-related information before. The residual stream at this layer is of particular interest because it aggregates information from previous layers, serving as a transmitter for feature representation.
Main hypothesis of all of this work is that there is a structure in the model and there is geometric relationship between the features and it can be modeled in a linear subspace that can allow to perform other operations like date arithmetic.
One can follow the following approaches to understand this more:
Activation Probing is used to identify the components of the residual stream that are most relevant to calendar features. This involves analyzing the activations of neurons in response to date-related inputs and determining which dimensions are most informative.
Geometric Visualization helps in identifying clusters and patterns that correspond to different calendar features, providing a visual representation of the model's internal structure.
Linear Regression is applied to quantify the relationship between input features and the corresponding directions in the residual stream. This statistical approach helps in isolating the dimensions that are most predictive of calendar information.

Findings:
Post shows that GPT-2 encodes calendar features in a highly structured manner, with distinct geometric patterns emerging in the residual stream. This suggests that the model has developed an implicit understanding of temporal concepts.
The model uses a relatively low-dimensional subspace to represent calendar features, indicating an efficient encoding strategy. This efficiency is likely a result of the model's training on large text corpora, which contain abundant temporal information.
The presence of linear subspaces allows GPT-2 to perform basic temporal arithmetic, such as calculating the difference between dates. This capability is embedded within the model's architecture, enabling it to handle complex date-related queries.
Antropic wrote about various ideas from interpretability team in a blog post. They cover 5 different directions in their blog post and I will go over some of them in a detailed manner:
As outlined above; Mechanistic interpretability involves reverse-engineering neural networks to understand their internal computations and representations. This field aims to transform the learned weights of neural networks into human-understandable algorithms. The article highlights several open problems in this area, particularly the challenge of superposition, where features overlap within the network, complicating interpretability. Researchers are working on identifying and addressing additional hurdles to advance the understanding of neural networks, emphasizing that these challenges can be tackled in parallel, thus providing optimism for progress.
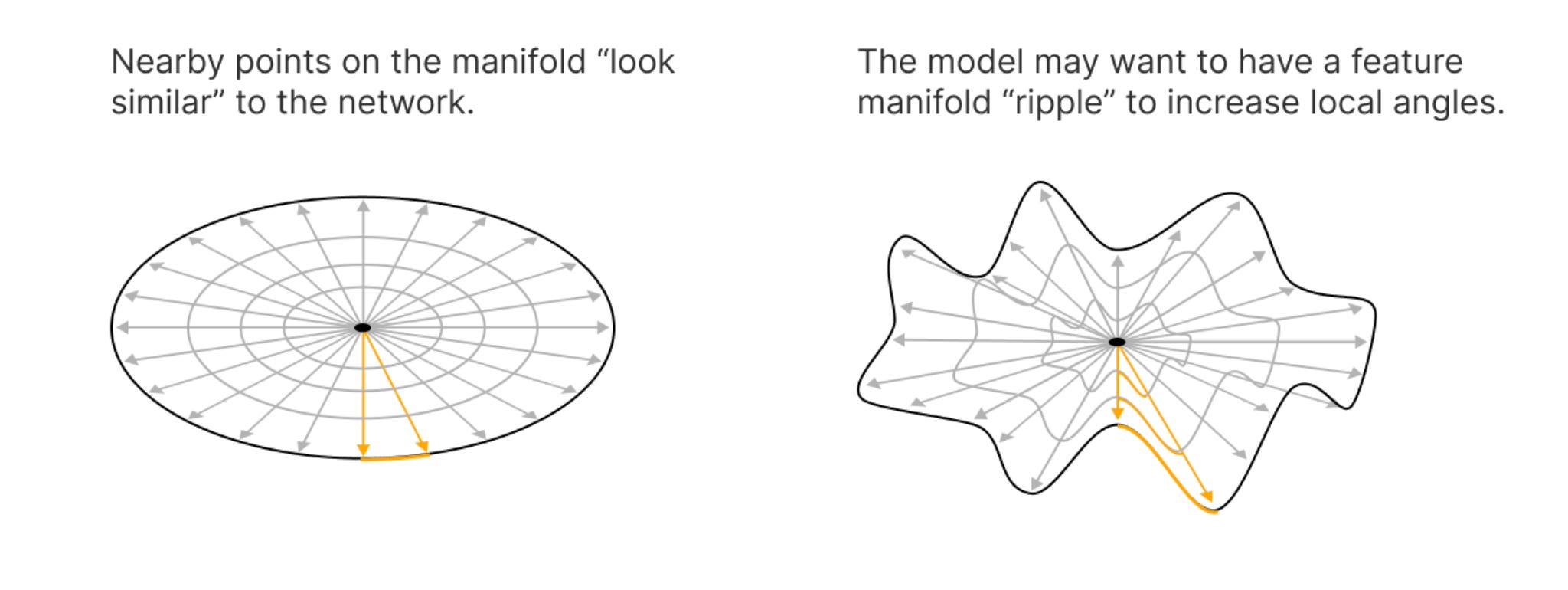
Linear representation hypothesis, which posits that features in neural networks can be understood as linear combinations of input data. This hypothesis is crucial for interpreting multidimensional features or feature manifolds within models. The team clarifies previous writings by emphasizing the distinction between one-dimensional features and those that behave linearly in a mathematical sense. This refined definition aids in understanding how features develop and interact within the network, providing insights into the model's processing mechanisms.

Multidimensional features refer to features that can be represented as manifolds, which must adhere to properties like composition as addition and intensity as scaling. The article explores the complexity of these manifolds and their implications for model interpretability. Understanding these manifolds is seen as a pathway to significant insights into how neural networks process information, potentially leading to more transparent and accountable AI systems.
Sparse Autoencoders have resolved millions of features but blog authors believe there are many more sparse features yet to be uncovered. These features, akin to "dark matter," are challenging to resolve but may hold the key to understanding the full complexity of neural networks. Dictionary learning is highlighted as a promising approach to reveal these rare features, although current limitations remain.
Efforts to reproduce results from previous research on transformer circuits are detailed, focusing on using pivot tables to interpret one-layer transformers. Pivot tables provide a visual summary of the model's attention mechanisms, offering insights into model behavior. The team discusses the challenges of reproducing these results, emphasizing the importance of subtle details in interpretability research.

Feature specificity and sensitivity are measures of how well a feature corresponds to a concept. Specificity refers to the likelihood that a concept is present when a feature activates, while sensitivity is the likelihood that a feature activates when a concept is present. The team explores using AI models like Claude to quantify sensitivity by assessing concept relevance in text samples, providing a framework for evaluating model interpretability.

Google Deepmind wrote about Gemma scope on how it can use sparse autoencoders(SAE) to provide interpretability into the various deep learning models. It is built mainly on sparse auto encoders, but it also allows us to provide various interpretability features through understanding feature distribution and importance of these features.
Sparse Autoencoders (SAEs) and JumpReLU Architecture:
Gemma Scope employs SAEs to examine the activations within the Gemma 2 models. These autoencoders are trained on each layer and sublayer output of the models, resulting in over 400 sparse autoencoders and more than 30 million learned features.
The SAEs function like a "microscope," allowing researchers to zoom in on dense, compressed activations and expand them into a more interpretable form. This helps in understanding how features develop across the model and how they interact to form more complex features.
The Gemma Scope leverages the JumpReLU SAE architecture, which improves the balance between detecting feature presence and assessing their strength. This architecture significantly reduces errors compared to the original sparse autoencoder design. More details can be found in this paper.
Layer-Level Analysis and Model Evaluation:
Gemma Scope can also be used to evaluate the behavior of individual AI model layers while processing requests. This layer-level analysis is crucial for understanding how specific model layers contribute to the overall behavior of the AI system. Gemma Scope allows modify model layers and evaluate the impact on the model's behavior. This capability is essential for testing hypotheses about model functionality and improving model performance.
Libraries

They describe a newly forming research area Automated Design of Agentic Systems (ADAS), which aims to automatically create powerful agentic system designs, including inventing novel building blocks and/or combining them in new ways.

They present a simple yet effective ADAS algorithm named Meta Agent Search to demonstrate that agents can invent novel and powerful agent designs. In Meta Agent Search, a "meta" agent iteratively programs interesting new agents in code based on previous discoveries.
More examples are available in their project page.

GPJax aims to provide a low-level interface to Gaussian process (GP) models in Jax, structured to give researchers maximum flexibility in extending the code to suit their own needs. The idea is that the code should be as close as possible to the maths we write on paper when working with GP models.
Mishax is a utility library for mechanistic interpretability research, with its motivations explained in this blog post. It enables users to do 2 things:
mishax.ast_patcherenables running code from some other library (e.g. a deep learning codebase) with some source-level code modifications applied. For mechanistic interpretability this can be used to stick probes in the model and intervene at arbitrary locations. This otherwise requires forking the code that’s being modified, but that comes with more maintenance requirements.mishax.safe_greenlet, given a complicated functionfthat allows running arbitrary callbacks somewhere deep inside (e.g. using Flax’sintercept_methods), enables transforming it into an ordinary-looking Pythonforloop that iterates over internal values and allows them to be replaced with other values. Behind the scenes, this will runfin a kind of separate “thread” –- but the user can mostly ignore that, and use the loop to read and write representations into the model during a forward pass, in a way that interoperates well with the rest of JAX.

Gemma Scope has an excellent website to explain more about how the library works internally.

You can play the pre-populated demos, or if you want to, you can create your own use case especially for the feature importance and analysis capabilities. It shows the top features and features activated separately and shows the tokens separately as well. Gemma scope model weights are available in here.

MInference 1.0 leverages the dynamic sparse nature of LLMs' attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy.