

Lyft's explains their Model Serving Infrastructure
Uber builds a data drift detection system, AGI will not get more coherent as it will get more intelligent

Articles
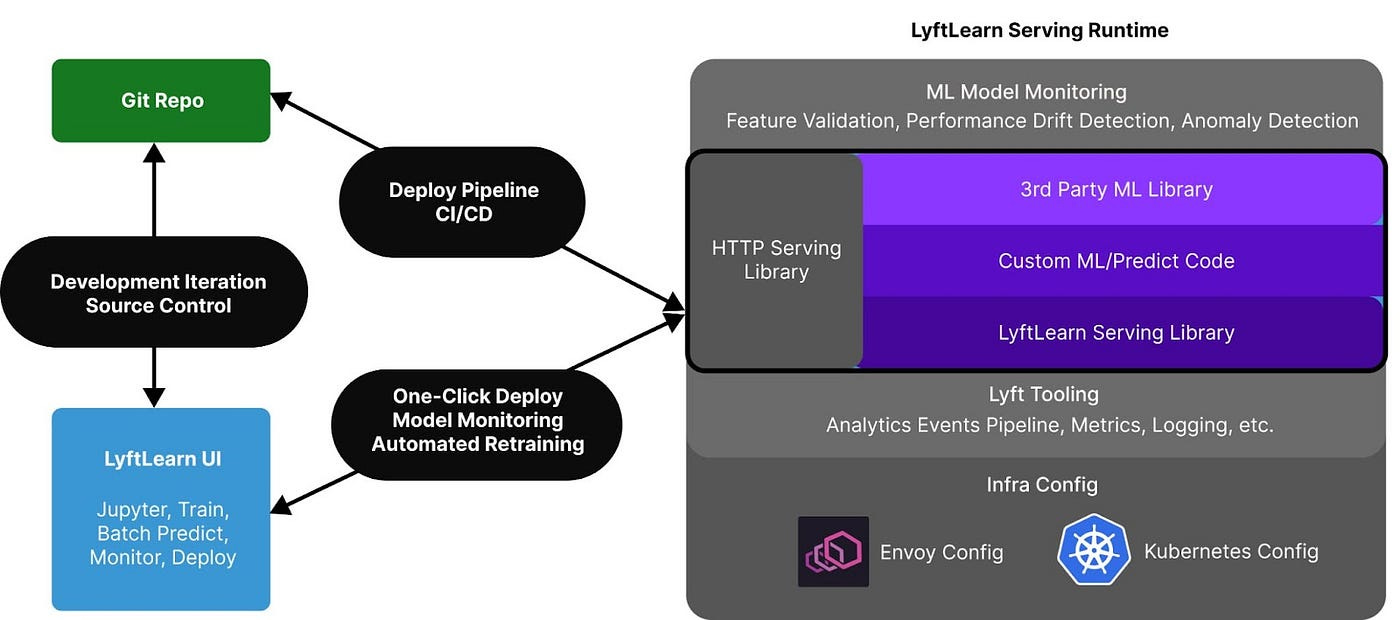
Lyft wrote about their model serving infrastructure in this blog post. They leverage Kubernetes and Envoy for model serving and use Gunicorn/Flask for their framework.
Their learnings:
Define the term “model”. “Model” can refer to a wide variety of things (e.g. the source code, the collection of weights, files in S3, the model binary, etc.), so it’s important to carefully define and document what “model” refers to at the start of almost every conversation. Having a canonical set of definitions in the ML community for all of these different notions of “models” would be immensely helpful.
Supply user-facing documentation. For platform products, thorough, clear documentation is critical for adoption. Great documentation leads to teams understanding the systems and self-onboarding effectively, which reduces the platform teams’ support overhead.
Expect model serving requests to be used indefinitely. Once a model is serving inference requests behind a network endpoint, it’s likely to be used indefinitely. Therefore, it is important to ensure that the serving system is stable and performs well. Conversely, migrating old models to a new serving system can be incredibly challenging.
Prepare to make hard trade-offs. We faced many trade-offs such as building a“Seamless end-to-end UX for new customers” vs. “Composable Intermediary APIs for power customers” or enabling “Bespoke ML workflows for each team” vs. enforcing “Rigor of software engineering best practices”. We made case-by-case decisions based on user behavior and feedback.
Make sure your vision is aligned with the power customers. It’s important to align the vision for a new system with the needs of power customers. In our case that meant prioritizing stability, performance, and flexibility above all else. Don’t be afraid to use boring technology.

Uber wrote about how they build a data drift detection system. I like how they actually examined a particular issue and designed a system to prevent such case:
Incident
Uber fares are composed of different components like surges, toll fees, etc. Riders’ reaction to these different components and trip conversion rates are critical to building fares ML models. We had an incident where fare component “X” was missing in the critical fares dataset for 10% of the sessions across key US cities.
Root Cause
The root cause was an app experiment that started logging fares differently.
How was it Detected?
This incident was detected after 45 days manually by one of the data scientists.
Impact
This dataset is used to train critical fares ML models. Fares components are an important feature used to train this model. To quantify the impact of such data incidents, the Fares data science team has built a simulation framework that replicates corrupted data from real production incidents and assesses the impact on the fares data model performance. Corrupted fares component in 30% of the sessions severely impacts the model performance leading to a 0.23% decline in the incremental gross booking. An incident that corrupts the fare component data in 10% of sessions across major US cities for 45 days would translate to millions of dollars of lost revenue.
The percentage of sessions with a particular fare component is a key metric that leadership and global ops use to make important decisions and understand the marketplace’s health.
Additionally, when a data incident happens, multiple teams across data science, data engineering, and product engineering lose productivity as they try to determine the root cause of the data incident.
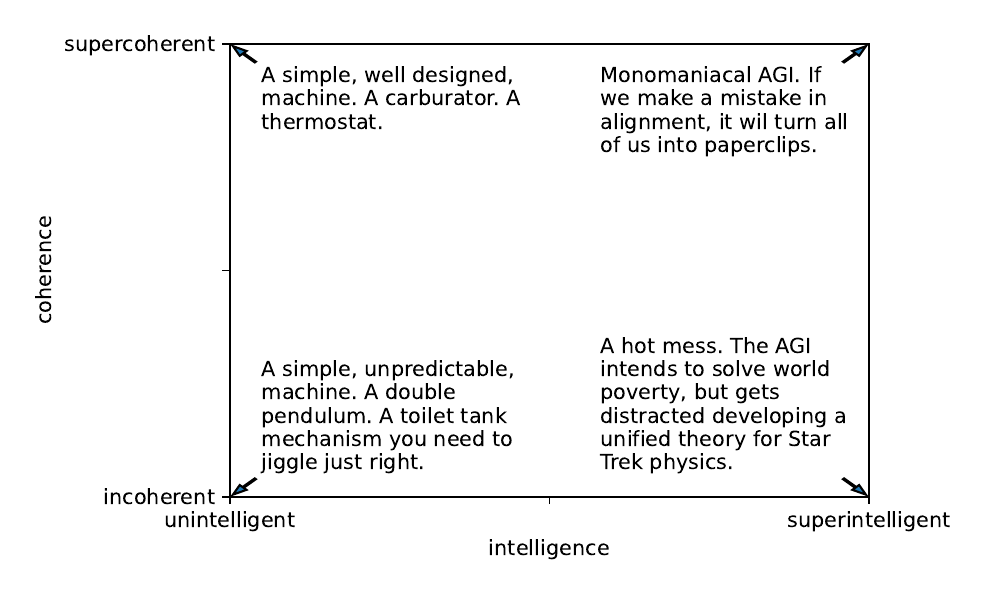
Jascha Sohl-Dickstein wrote about super-intelligence and super-coherence and how AGI cannot be both supercoherent and superintelligent in this blog post. Main argument of the post is that as the AGI gets more intelligent, it may not get more coherent on the things that it would do and he gives a number of different examples from various studies and experiments. Many popular fears about superintelligent AI rely on an unstated assumption that as AI is made more intelligent, it will also become more coherent, in that it will monomaniacally pursue a well defined goal. He discussed this assumption, and ran a simple experiment probing the relationship between intelligence and coherence.
The simple experiment provided evidence that the opposite is true — as entities become smarter, their behavior tends to become more incoherent, and less well described as pursuit of a single well-defined goal. This suggests that we should be less worried about AGI posing an existential risk due to errors in value alignment.
Libraries
VPD (Visual Perception with Pre-trained Diffusion Models) is a framework that leverages the high-level and low-level knowledge of a pre-trained text-to-image diffusion model to downstream visual perception tasks.
CaFo, a Cascade of Foundation models that incorporates diverse prior knowledge of various pre-trianing paradigms for better few-shot learning, including CLIP, DINO, DALL-E, and GPT-3. Specifically, CaFo works by `Prompt, Generate, then Cache'. They leverage GPT-3 to prompt CLIP with rich linguistic semantics and generate synthetic images via DALL-E to expand the few-shot training data. Then, they introduce a learnable cache model to adaptively blend the predictions from CLIP and DINO. By such collaboration, CaFo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification.
Visual ChatGPT connects ChatGPT and a series of Visual Foundation Models to enable sending and receiving images during chatting.
pyribs is a bare-bones Python library for quality diversity (QD) optimization. Pyribs implements the highly modular Rapid Illumination of Behavior Space (RIBS) framework for QD optimization. Pyribs is also the official implementation of Covariance Matrix Adaptation MAP-Elites (CMA-ME), Covariance Matrix Adaptation MAP-Elites via a Gradient Arborescence (CMA-MEGA), Covariance Matrix Adaptation MAP-Annealing (CMA-MAE), and scalable variants of CMA-MAE.
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on usability over performance, simple over easy, and customizability over abstractions.
🤗 Diffusers offers three core components:
State-of-the-art diffusion pipelines that can be run in inference with just a few lines of code.
Interchangeable noise schedulers for different diffusion speeds and output quality.
Pretrained models that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.