

LSM-2 from Google for Wearable Data
Kimi-2 is released by MoonshotAI, another SOTA MoE Model

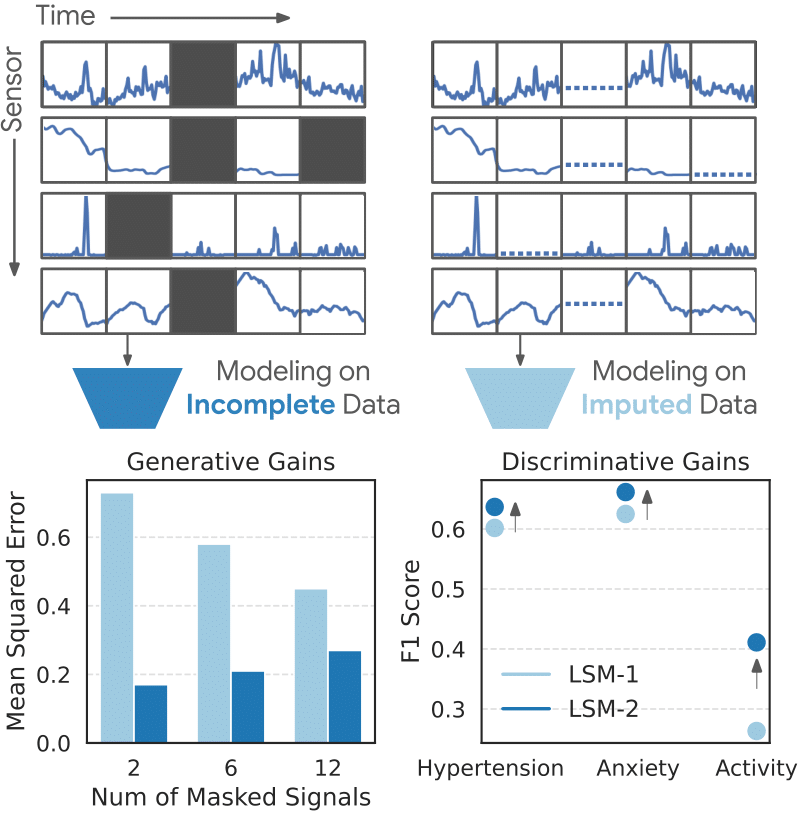
Google wrote an article on LSM-2, a foundation model designed for wearable sensor data, leveraging a novel self-supervised learning (SSL) framework called Adaptive and Inherited Masking (AIM). This approach addresses the challenge of incomplete data that is common in real-world wearable devices, due to device removal, charging, motion artifacts, and other disruptions.
Unlike traditional SSL methods that require complete data or rely on imputation and filtering—which introduce biases or waste valuable data—AIM treats missing data as a natural, informative aspect of sensor streams, enabling the model to learn directly from incomplete data without explicit imputation.

AIM extends masked autoencoder (MAE) pre-training by introducing a dual masking strategy that combines token dropout and attention masking. Token dropout improves computational efficiency by dropping a fixed number of masked tokens (segments of missing or deliberately masked data) before the encoder stage, while attention masking handles the variable and unpredictable additional tokens that remain masked based on real-world missingness. This technique effectively balances reducing input sequence length with maintaining model capacity to handle naturally fragmented data streams. During fine-tuning and evaluation phases, AIM applies attention masking exclusively to naturally missing tokens, allowing the model to generalize and robustly process variable data fragmentation.

Adaptive and Inherited Masking (AIM) Capabilities:
Dual Masking: AIM distinguishes between inherited (naturally missing) tokens, reflecting real sensor gaps, and artificial mask tokens, deliberately applied for self-supervised learning objectives.
Token Dropout: During pre-training, a fixed number of masked tokens (from both inherited and artificial types) are dropped before the encoder, reducing computational burden by shortening the effective sequence length.
Attention Masking: Remaining masked tokens are handled within the encoder's transformer blocks via explicit attention masks—ensuring the attention mechanism ignores these tokens during representation learning. This allows the model to process any configuration of missing data.
Unified Treatment: AIM treats inherited and artificial mask tokens equivalently at the transformer level, teaching the model to reason about and reconstruct both types, enabling robustness to random and structured data fragmentation.
Pre-training and Fine-tuning:
During SSL pre-training, AIM intersperses reconstructed and naturally missing tokens. The model learns to generate latent representations that encode both the underlying data structure and the distribution of missingness.
At fine-tuning and deployment, only inherited masks (i.e., the real-world missing entries) are present; attention masking ensures seamless adaptation to any fragmentation pattern, a vast improvement over imputation-based or aggressive filtering techniques.
Head Layer Probes:
After the transformer backbone, task-specific linear probes are used for evaluations:
Classification Tasks: Embeddings are averaged across observed tokens as the input to a linear classifier.
Regression Tasks: A similar approach supplies inputs to a linear regressor.
Generative Tasks: The model reconstructs missing input regions by generating output directly for masked locations.
Google had an extensive multimodal wearable dataset:
Size: 40M hours of data from 60,000+ participants over three months (March–May 2024).
Device Heterogeneity: Devices include Fitbit, Google Pixel watches, and trackers with multiple sensor channels (e.g., heart rate, accelerometry, EDA, temperature).
Labeling: All data are anonymized. Meta-data (user annotations for 20 activities, self-reported physical/mental health, demographics) collected in parallel.
Partitioning: Data from each user appears in either training, fine-tuning, or evaluation splits, but never more than one, strictly preventing data leakage and ensuring reliable generalization tests.
Data Preprocessing and Ingestion Scheme:
Tokenization: Raw continuous time-series from various sensors are discretized into non-overlapping time-channel patches, permitting efficient batching and masking within the transformer—standardizing sequences with variable sampling rates and occasional dropout artifacts.
Missingness Quantification: Every input sequence is annotated with a precise missingness map, denoting which patches result from real-world sensor gaps. This map governs inherited masking throughout the pipeline.
No Imputation: Critically, AIM and LSM-2 do not perform statistical or model-based imputation; instead, every instance of missingness (whether due to device-off, motion artifacts, or signal drop) is treated as valuable, information-bearing structure.
Efficient Large-scale Ingestion:
Incoming data are validated and indexed with hash-based deduplication to prevent redundant storage.
Meta-data and sensor streams are stored in a format optimized for parallel readout and random-access, crucial for efficient construction of masked batches for SSL training.
Custom ingestion pipelines ensure batch construction correctly respects subject splits and missing annotations.

It performs relatively well in a number of tasks:
Generative Tasks: LSM-2 achieves up to 77% better mean squared error (MSE) reconstruction of missing sensor signals than LSM-1 under high (80%) missingness, excelling in random imputation, interpolation, extrapolation, and channel-missing scenarios.

Classification and Regression: LSM-2 outperforms not just LSM-1 but also supervised baselines in 20-class activity classification and binary health conditions (hypertension, anxiety), with robust feature generalization to new tasks via linear probes.
Scaling: Unlike LSM-1, LSM-2’s performance scales almost linearly with increases in data, subjects, compute, and model capacity, showing no evidence of saturation
Libraries
Kimi K2 is a state-of-the-art mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters. Trained with the Muon optimizer, Kimi K2 achieves exceptional performance across frontier knowledge, reasoning, and coding tasks while being meticulously optimized for agentic capabilities.
Key Features
Large-Scale Training: Pre-trained a 1T parameter MoE model on 15.5T tokens with zero training instability.
MuonClip Optimizer: We apply the Muon optimizer to an unprecedented scale, and develop novel optimization techniques to resolve instabilities while scaling up.
Agentic Intelligence: Specifically designed for tool use, reasoning, and autonomous problem-solving.
Model Variants
Kimi-K2-Base: The foundation model, a strong start for researchers and builders who want full control for fine-tuning and custom solutions.
Kimi-K2-Instruct: The post-trained model best for drop-in, general-purpose chat and agentic experiences. It is a reflex-grade model without long thinking.


Contextual Observation & Recall Engine(C.O.R.E) is a portable memory graph built from your llm interactions and personal data, making all your context and workflow history accessible to any AI tool, just like a digital brain. This eliminates the need for repeated context sharing . The aim is to provide:
Unified, Portable Memory: Add and recall context seamlessly, and connect your memory across apps like Claude, Cursor, Windsurf and more.
Relational, Not just Flat Facts: CORE organizes your knowledge, storing both facts and relationships for a deeper richer memory like a real brain.
User Owned: You decide what to keep, update or delete and share your memory across the tool you want and be freed from vendor lock-in.

SymbolicAI is a neuro-symbolic framework, combining classical Python programming with the differentiable, programmable nature of LLMs in a way that actually feels natural in Python. It's built to not stand in the way of your ambitions. It's easily extensible and customizable to your needs by virtue of its modular design. It's quite easy to write your own engine, host locally an engine of your choice, or interface with tools like web search or image generation. To keep things concise in this README, we'll introduce two key concepts that define SymbolicAI: primitives and contracts.

Arch handles the pesky low-level work in building agentic apps — like applying guardrails, clarifying vague user input, routing prompts to the right agent, and unifying access to any LLM. It’s a language and framework friendly infrastructure layer designed to help you build and ship agentic apps faster.
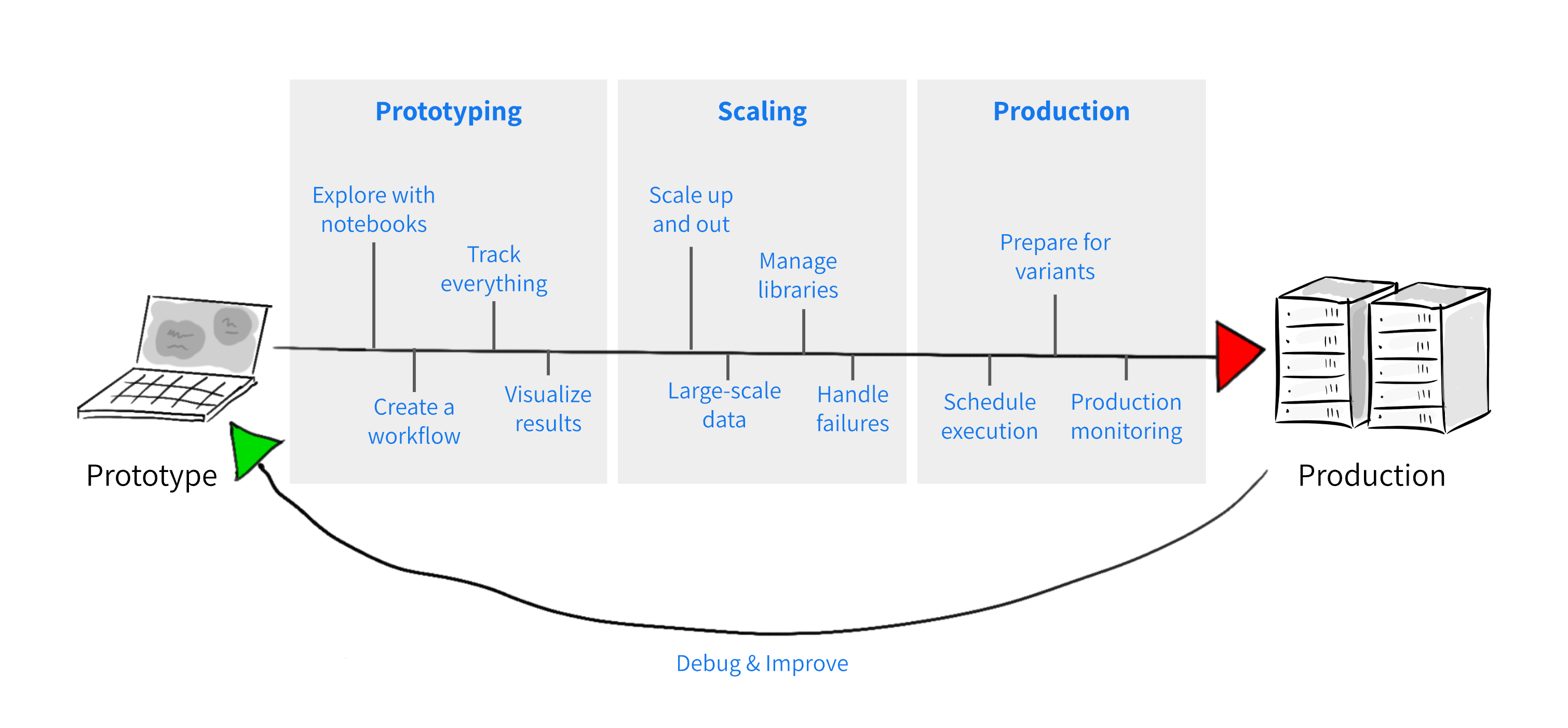
Metaflow is a human-centric framework designed to help scientists and engineers build and manage real-life AI and ML systems. Serving teams of all sizes and scale, Metaflow streamlines the entire development lifecycle—from rapid prototyping in notebooks to reliable, maintainable production deployments—enabling teams to iterate quickly and deliver robust systems efficiently.
Originally developed at Netflix and now supported by Outerbounds, Metaflow is designed to boost the productivity for research and engineering teams working on a wide variety of projects, from classical statistics to state-of-the-art deep learning and foundation models. By unifying code, data, and compute at every stage, Metaflow ensures seamless, end-to-end management of real-world AI and ML systems.
The code is available in GitHub.
MedGemma is a collection of Gemma 3 variants that are trained for performance on medical text and image comprehension. Developers can use MedGemma to accelerate building healthcare-based AI applications. MedGemma comes in two variants: a 4B multimodal version and a 27B text-only version.
MedGemma 4B utilizes a SigLIP image encoder that has been specifically pre-trained on a variety of de-identified medical data, including chest X-rays, dermatology images, ophthalmology images, and histopathology slides. Its LLM component is trained on a diverse set of medical data, including radiology images, histopathology patches, ophthalmology images, dermatology images, and medical text.
goose is your on-machine AI agent, capable of automating complex development tasks from start to finish. More than just code suggestions, goose can build entire projects from scratch, write and execute code, debug failures, orchestrate workflows, and interact with external APIs - autonomously.
Whether you're prototyping an idea, refining existing code, or managing intricate engineering pipelines, goose adapts to your workflow and executes tasks with precision.
Designed for maximum flexibility, goose works with any LLM and supports multi-model configuration to optimize performance and cost, seamlessly integrates with MCP servers, and is available as both a desktop app as well as CLI - making it the ultimate AI assistant for developers who want to move faster and focus on innovation.
Below The Fold

Sirius is a GPU-native SQL engine. It plugs into existing databases such as DuckDB via the standard Substrait query format, requiring no query rewrites or major system changes.
BloomSearch provides extremely low memory usage and low cold-start searches through pluggable storage interfaces.
Memory efficient: Bloom filters have constant size regardless of data volume
Pluggable storage: DataStore and MetaStore interfaces for any backend (can be same or separate)
Fast filtering: Hierarchical pruning via partitions, minmax indexes, and bloom filters
Flexible queries: Search by
field,token, orfield:tokenwith AND/OR combinatorsDisaggregated storage and compute: Unbound ingest and query throughput

atopile is a language, compiler and toolchain to design electronics with code.
Design circuit boards with the same powerful workflows that software developers use - version control, modularity, and automated validation. Instead of point-and-click schematics, use human-readable .ato files that can be version controlled and shared. Capture design intelligence and validation rules in code to ensure your hardware works as intended. QuickStart page is pretty good if you want to get started right away.
Containerization package allows applications to use Linux containers. Containerization is written in Swift and uses Virtualization.framework on Apple silicon.
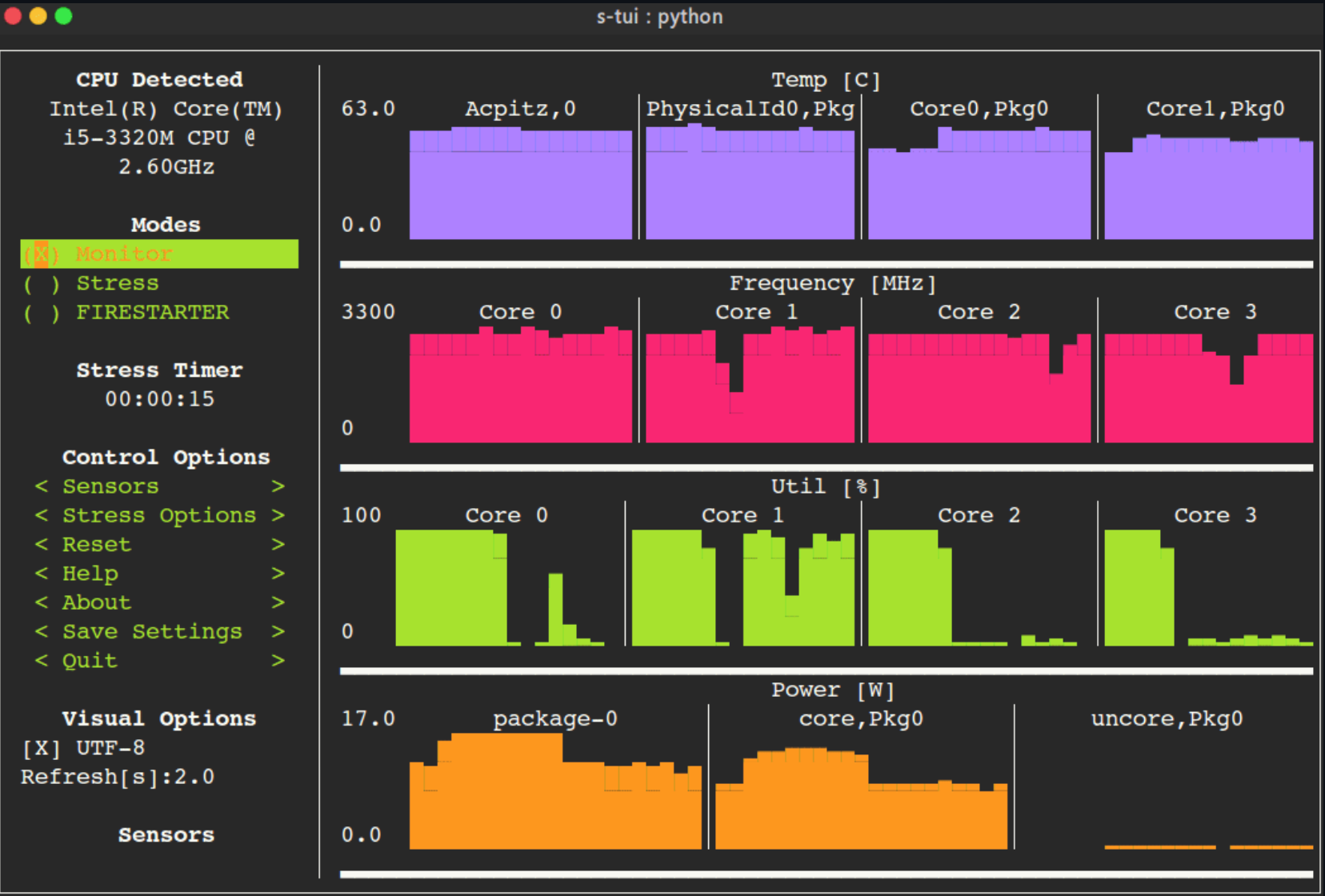
Stress-Terminal UI, s-tui, monitors CPU temperature, frequency, power and utilization in a graphical way from the terminal.
Maestro is a general-purpose workflow orchestrator that provides a fully managed workflow-as-a-service (WAAS) to the data platform users at Netflix.
It serves thousands of users, including data scientists, data engineers, machine learning engineers, software engineers, content producers, and business analysts, for various use cases. It schedules hundreds of thousands of workflows, millions of jobs every day and operates with a strict SLO even when there are spikes in the traffic. Maestro is highly scalable and extensible to support existing and new use cases and offers enhanced usability to end users.
The library is available in GitHub.
More To Read
From a previous employee on his time spent in OpenAI as reflections.
A good blog post on going through some unknown “artisanal” git commands and shows basic prompts and commands in a funny way.