

Llama 3.1 launched and it is gooooood!
ceLlama, llama-agentic-system, Treescope, Opslane

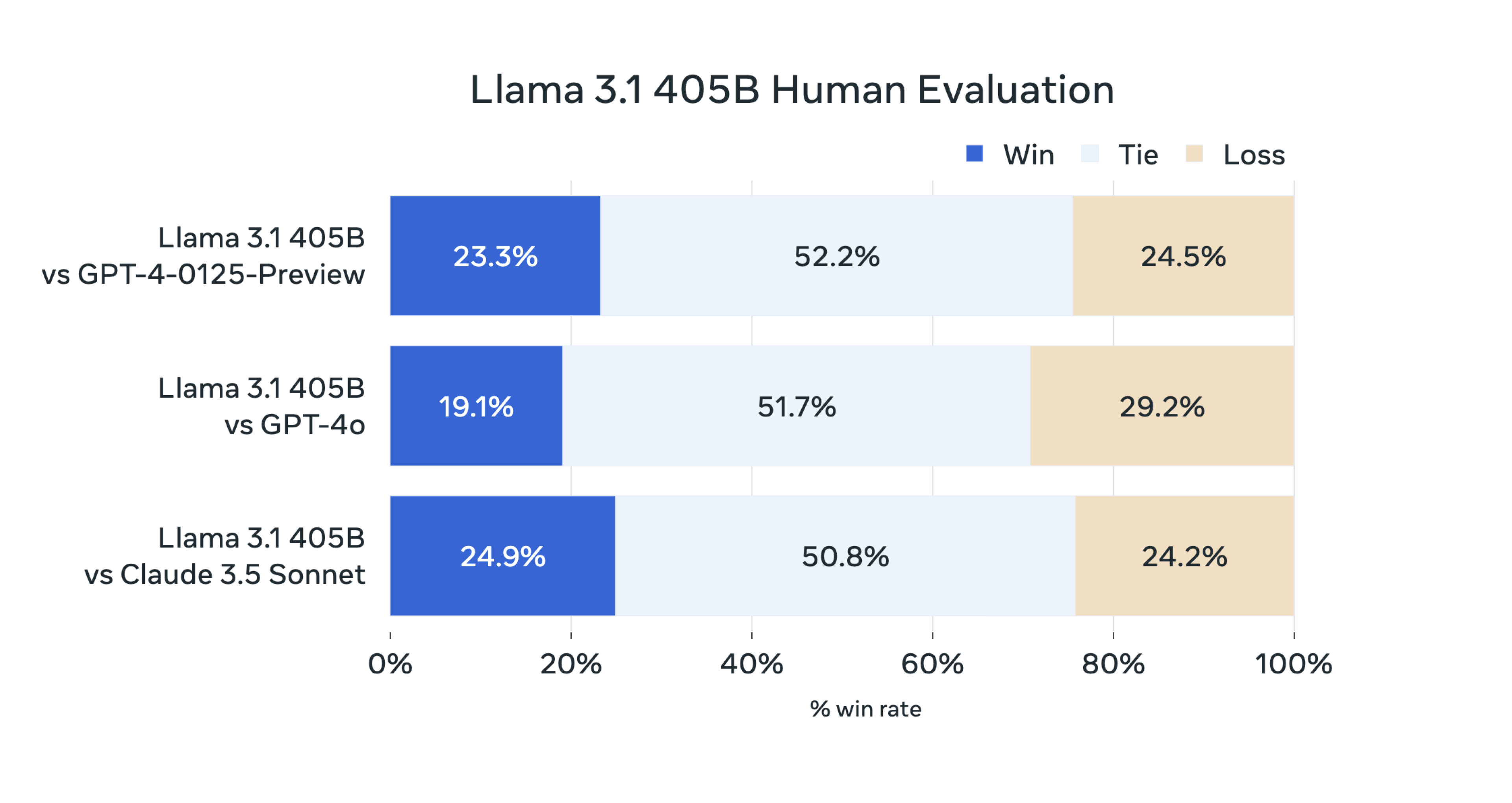
Today, we had a special issue with Llama3.1 which I will cover a lot of technical details on the delta between Llama 3 and Llama 3.1, model size and data volume are significantly different as well as various strategies for data sampling.
Articles

Meta has announced the release of Llama 3.1, latest and most capable open-source large language model (LLM) collection to date. I will go over in different dimensions of this model release similar to what I have done before for Llama3:
Llama3 is out and it is awesome!

This week’s newsletter is completely focused on Llama and its ecosystem as Llama3 was released last week! Articles Llama3 is out and available for public consumption in two different sizes(8B and 70B). The model architecture delta is in the following:
Model size and data scale are the most significant improvements comparing to previous model architecture. It comes with 3 different flavors and 405 billion parameter is the most capable, but also the most costly one.
Model Architecture and Scaling:
The Llama 3.1 405B model is bigger than Llama 3 in all of the dimensions:
Architecture: Likely based on the transformer architecture with optimizations for large-scale training.
Parameter Count: At 405 billion parameters, it's more than 5 times larger than the previous Llama 2 70B model.
Training Data: Over 15 trillion tokens, representing a massive increase in training corpus size.
Hardware Size: Employed over 16,000 H100 GPUs, showcasing the immense computational resources required.
Training Optimizations:
Improved data parallelism and model parallelism techniques
Enhanced pipeline parallelism to efficiently distribute computation across GPUs
Optimized memory management to handle the increased model size
Scaling Laws: The performance improvements align with theoretical scaling laws, suggesting that even larger models could yield further gains.

Data Quality and Processing:
Meta significantly enhanced their data pipeline for Llama 3.1:
Pre-training Data:
Implemented more sophisticated filtering algorithms to remove low-quality content
Developed advanced deduplication techniques to ensure data diversity
Utilized natural language processing tools to assess text coherence and information density
Post-training Data:
Employed human-in-the-loop processes for quality assurance
Implemented automated metrics to evaluate instruction-following capabilities
Developed domain-specific datasets to enhance performance in targeted areas (e.g., coding, scientific reasoning)
Multilingual Focus:
Expanded the training corpus to include high-quality content in multiple languages
Balanced language representation to improve performance across diverse linguistic contexts
Model Optimization
The transition from 16-bit to 8-bit precision is a crucial advancement to be able to reduce the cost of the model inference, but also allow to use the compute in the training a lot more:
Precision Reduction:
From BF16 (bfloat16) to FP8 (8-bit floating-point)
Quantization Techniques:
Likely employed post-training quantization (PTQ) methods
Possibly used quantization-aware training (QAT) for some components
Performance Impact:
Reduced memory bandwidth requirements by up to 50%
Increased inference speed by potentially 2x or more
Enabled running the 405B model on a single server node, dramatically improving deployment flexibility
Accuracy Preservation:
Implemented calibration techniques to minimize accuracy loss during quantization
Possibly used mixed-precision approaches for sensitive layers
Instruction and Chat Fine-tuning:
The fine-tuning process for Llama 3.1 was extensive and multi-staged with different procedures targeting different outcomes in the fine-tuning:
Supervised Fine-Tuning (SFT):
Utilized a large corpus of instruction-response pairs
Implemented curriculum learning to gradually increase task complexity
Employed dynamic batching to handle variable-length inputs efficiently
Rejection Sampling (RS):
Generated multiple responses for each prompt
Implemented a learned reward model to score and select the best responses
Iteratively refined the selection criteria based on human feedback
Direct Preference Optimization (DPO):
Applied reinforcement learning techniques to directly optimize for human preferences
Utilized a learned preference model to guide the optimization process
Implemented safeguards to prevent overfitting to the preference model
Synthetic Data Generation:
Developed advanced prompt engineering techniques to guide data generation
Implemented quality filters to ensure generated data meets predefined standards
Utilized active learning approaches to identify areas requiring additional synthetic data
Context Length and Multilingual Support:
The improvements in context length and multilingual capabilities are significant:
Context Length:
Increased from 4K tokens to 128K tokens for 8B and 70B models
Implemented efficient attention mechanisms (e.g., sparse attention, linear attention) to handle the extended context
Developed specialized positional encoding schemes for long sequences
Multilingual Enhancements:
Expanded the tokenizer vocabulary to better represent diverse languages
Implemented language-specific pre-training objectives to capture linguistic nuances
Developed cross-lingual transfer learning techniques to improve performance on low-resource languages
Llama System and Component Integration:
Meta's move towards a full AI system involves several key components:
Llama Guard 3:
Multilingual safety model trained on diverse harmful content datasets
Implements real-time content filtering and moderation capabilities
Utilizes advanced few-shot learning techniques for adaptability
Prompt Guard:
Specialized model for detecting and mitigating prompt injection attacks
Employs adversarial training techniques to improve robustness
Integrates seamlessly with the main Llama 3.1 models for enhanced security
Sample Applications:
Developed reference implementations for common use cases (e.g., chatbots, code assistants)
Implemented best practices for prompt engineering and response handling
Showcased integration with external tools and APIs for enhanced functionality
Llama Stack Proposal:
The Llama Stack initiative aims to standardize the AI development ecosystem:
Standardized Interfaces:
Defined common APIs for model inference, fine-tuning, and deployment
Established protocols for data exchange between components
Proposed standardized formats for model weights and configurations
Toolchain Components:
Developed reference implementations for tokenizers, embedders, and decoders
Proposed standardized metrics for model evaluation and comparison
Established guidelines for versioning and compatibility across components
Agentic Applications:
Defined interfaces for task planning and execution in multi-step workflows
Proposed standards for memory management and context retention in long-running agents
Established protocols for integrating external tools and knowledge bases
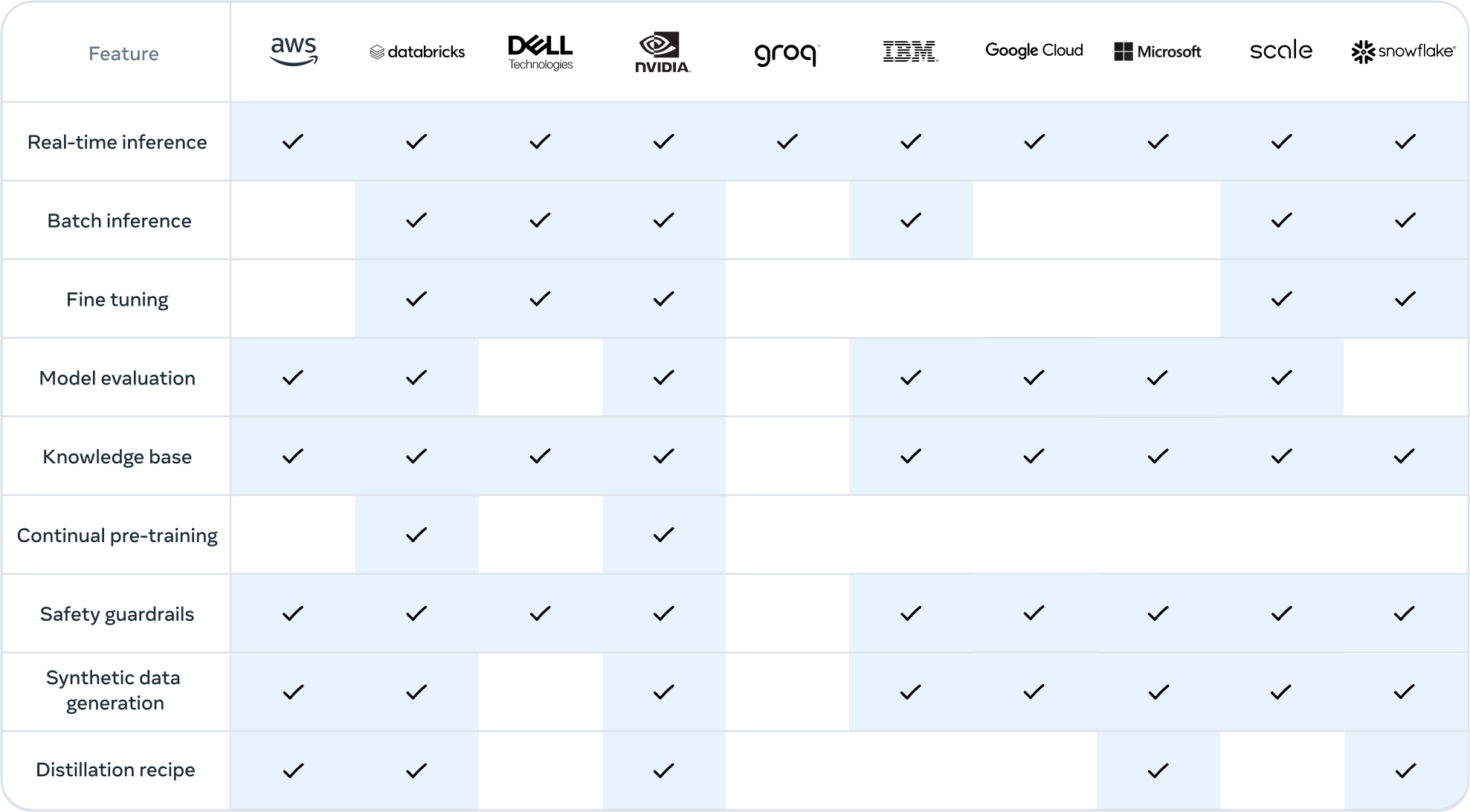
Ecosystem Support and Partnerships:
Meta has collaborated with key community projects like vLLM, TensorRT, and PyTorch to ensure day-one support for production deployment. They've also partnered with various companies and organizations to optimize inference and enable advanced workflows such as synthetic data generation, model distillation, and seamless RAG (Retrieval-Augmented Generation).
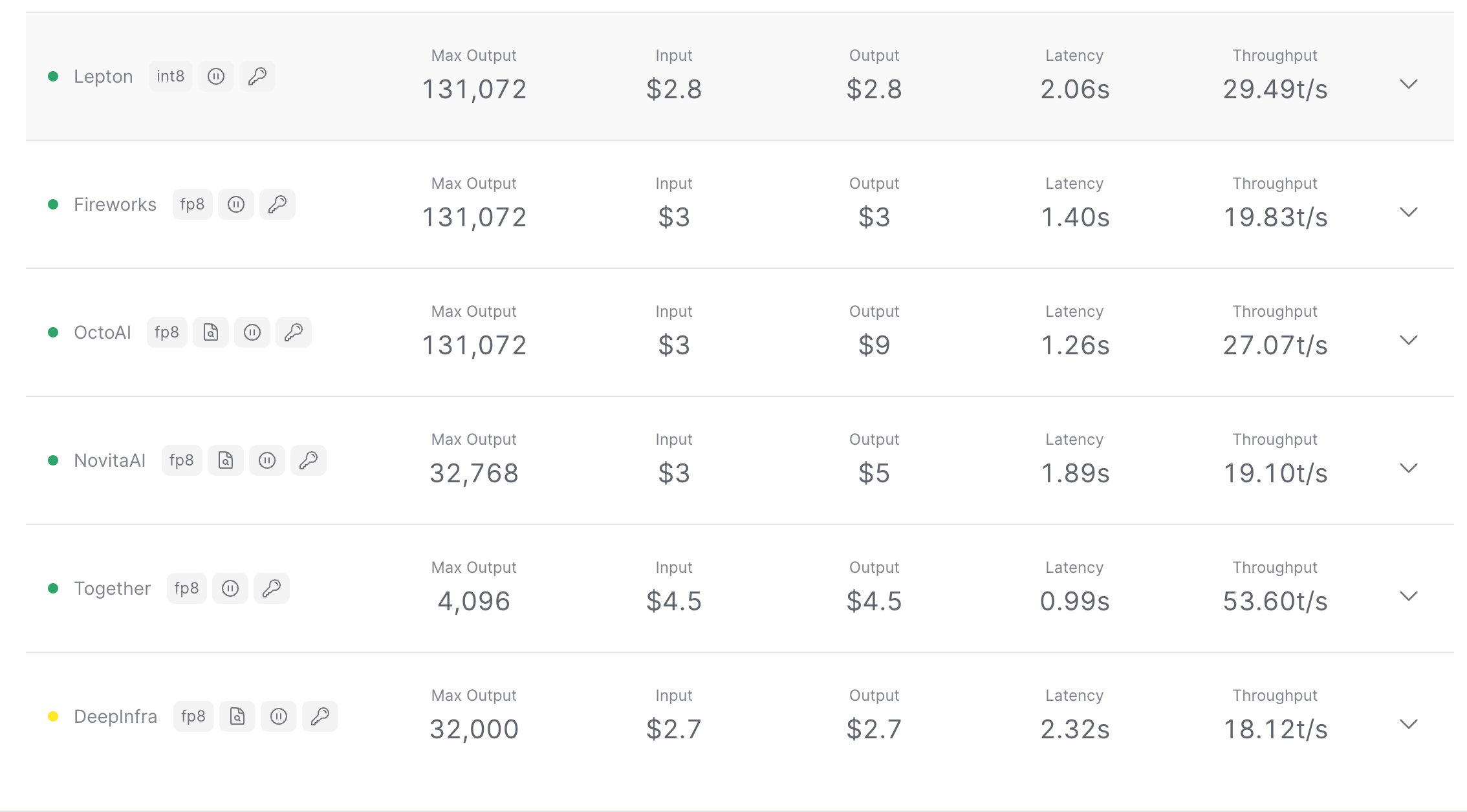
OpenRouter already have a number of different providers that has different cost characteristics for Llama 405B parameter model.
Mark Zuckerberg wrote also a letter to commitment for Open Source in coordination with LLama 3.1 and here are some of the reasonings from the post:
We need to train, fine-tune, and distill our own models. Every organization has different needs that are best met with models of different sizes that are trained or fine-tuned with their specific data. On-device tasks and classification tasks require small models, while more complicated tasks require larger models. Now you’ll be able to take the most advanced Llama models, continue training them with your own data and then distill them down to a model of your optimal size – without us or anyone else seeing your data.
We need to control our own destiny and not get locked into a closed vendor. Many organizations don’t want to depend on models they cannot run and control themselves. They don’t want closed model providers to be able to change their model, alter their terms of use, or even stop serving them entirely. They also don’t want to get locked into a single cloud that has exclusive rights to a model. Open source enables a broad ecosystem of companies with compatible toolchains that you can move between easily.
We need to protect our data. Many organizations handle sensitive data that they need to secure and can’t send to closed models over cloud APIs. Other organizations simply don’t trust the closed model providers with their data. Open source addresses these issues by enabling you to run the models wherever you want. It is well-accepted that open source software tends to be more secure because it is developed more transparently.
We need a model that is efficient and affordable to run. Developers can run inference on Llama 3.1 405B on their own infra at roughly 50% the cost of using closed models like GPT-4o, for both user-facing and offline inference tasks.
We want to invest in the ecosystem that’s going to be the standard for the long term. Lots of people see that open source is advancing at a faster rate than closed models, and they want to build their systems on the architecture that will give them the greatest advantage long term.
All of the models can be accessed from here.
Libraries

Treescope is an interactive HTML pretty-printer and N-dimensional array ("tensor") visualizer, designed for machine learning and neural networks research in IPython notebooks. It's a drop-in replacement for the standard IPython/Colab renderer, and adds support for:
Expanding and collapsing subtrees of rendered objects, to let you focus on the parts of your model that you care about,
Automatically embedding faceted visualizations of arbitrary-dimensional arrays and tensors directly into the output renderings, so you can quickly understand their shapes and the distribution of their values,
Color-coding parts of neural network models to emphasize shared structures,
Inserting "copy path" buttons that let you easily copy the path to any part of a rendered object,
Customizing the visualization strategy to support rendering your own data structures,
And more!
Treescope was originally developed as the pretty-printer for the Penzai neural network library, but it also supports rendering neural networks developed with other libraries, including Equinox, Flax NNX, and PyTorch. You can also use it with basic JAX and Numpy code.

ceLLama is a streamlined automation pipeline for cell type annotations using large-language models (LLMs).
Advantages:
Privacy: Operates locally, ensuring no data leaks.
Comprehensive Analysis: Considers negative genes.
Speed: Efficient processing.
Extensive Reporting: Generates customized reports.
llama-agentic-system allows you to run Llama 3.1 as a system capable of performing "agentic" tasks like:
Breaking a task down and performing multi-step reasoning.
Ability to use tools
built-in: the model has built-in knowledge of tools like search or code interpreter
zero-shot: the model can learn to call tools using previously unseen, in-context tool definitions
Additionally, we would like to shift safety evaluation from the model level to the overall system level. This allows the underlying model to remain broadly steerable and adaptable to use cases which need varying levels of safety protection.
One of the safety protections is provided by Llama Guard. By default, Llama Guard is used for both input and output filtering. However, the system can be configured to modify this default setting. For example, it is recommended to use Llama Guard for output filtering in situations where refusals to benign prompts are frequently observed, as long as safety requirements are met for your use case.

Opslane is a tool that helps the on-call experience less stressful.
It reduces alert fatigue by classifying alerts as actionable or noisy and providing contextual information for handling alerts.