Linkedin Integrates Fairness into their ML Pipelines
Learning to Route by task for Efficient Inference



Libraries
nn-Meter is a library from Microsoft that allows you to measure performance characteristics of models in various edge devices.
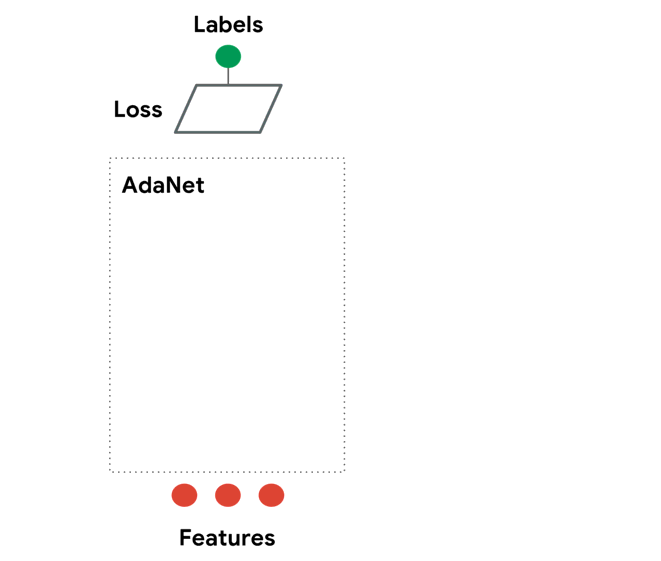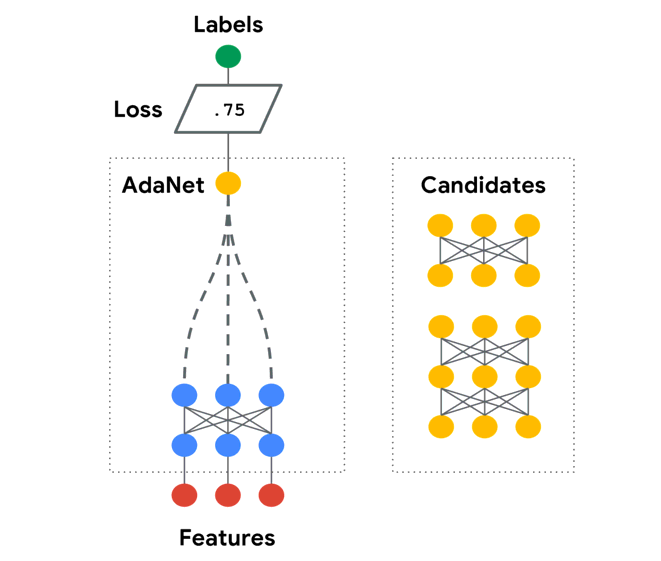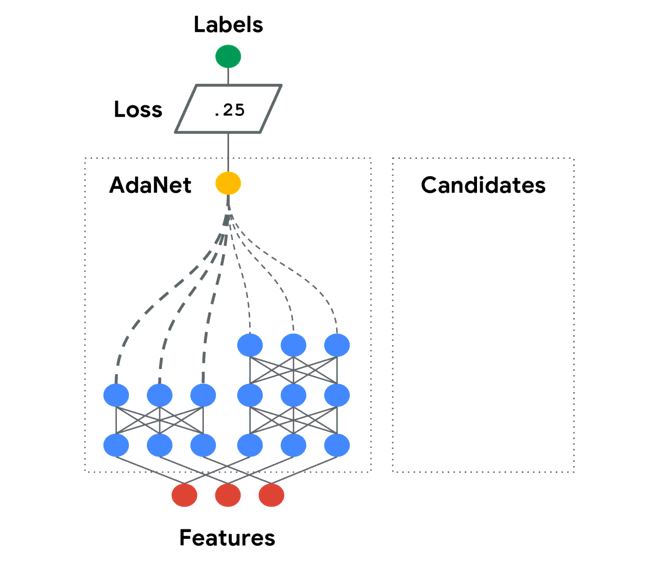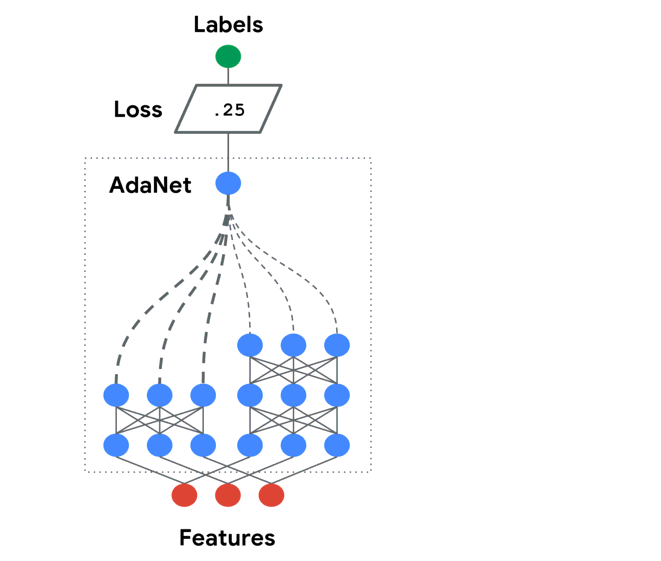
AdaNet is a lightweight TensorFlow-based framework for automatically learning models.
nni is an open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
PlotNeuralNet is a latex package that allows you to build various neural networks through latex.
Xmanager is a platform for packaging, running and keeping track of machine learning experiments. It currently enables one to launch experiments locally or on Google Cloud Platform (GCP).
Articles

How LinkedIn integrates fairness talks about integrating fairness into ML pipelines. The steps are in the following:
Start by evaluating the current model with the fairness metric.
If the model passes the fairness evaluation, mitigation may not be required.
If the model fails the fairness evaluation, our system learns and appends a post-processing layer in the form of a score transformation after the original model’s scoring step.
The mitigated model is then launched as an A/B experiment.
We collect online experimental data and validate the fairness metric.

Transformers blog post gives a good introduction to Transformers and core concepts on how to train the model.

Google wrote a blog post on explainability of visual classifiers. In this post, they are explaining how to build a system that can disentangle various attributes in the image and based on these attributes, they can build a “confidence” for attributes that will influence in the prediction score. Especially, gender and age classifiers are very interesting.
Examples of color of the hair in the age classifier and thickness of eyebrows for gender classifier are very interesting.

As shown in the above thread, this post is very interesting from Google. TLDR:
They extend MoE(Mixture of Experts) into task based MoE which they call TaskMoE where they still train a large multi-task model with the architecture of having many small stand-alone per-task subnetworks.
This approach has the advantage of still having a mixture of experts and it is very efficient as it only triggers a subset of per-task subnetworks.
Last month, there was another post/paper from Google that they proposed TokenLearner: https://ai.googleblog.com/2021/12/improving-vision-transformer-efficiency.html This approach also tries to learn an input representation that model would only process a small number of tokens that are specific to the task(kind of like a pre-prediction stage) The paper shows that they tried placing the tokenlearner in different places of ViT and found out that after the first quarter of the model stage, it reduces the computation to 33% of the original model processing.
This paper has similar approach where tokens are being used across different parts of the network, but in the inference time, the experts that are not used, will be pruned in order to save computation on inference time. This is exciting because model tries to learn various experts for task and assuming that you know what the task is, you can reduce the computation drastically.
This removes all of the need of post-processing model optimization techniques, such as pruning, knowledge distillation to make the model size smaller.
What if you want to predict all of the tasks? With the new architecture, you are still able to do it. It does not provide a lot of advantages, though in this use case as far as I understand, since you will be using all of the experts in the MoE layer and not save any computation.
For certain tasks, if you believe that there are certain experts that are not used at all, then this approach would be useful, but in this scenario, good old pruning would just work fine, too.
All of these papers and research follow the direction of Google AI Pathways: https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/ and foundational models overall: https://hai.stanford.edu/news/reflections-foundation-models
We want to train model once with as many tasks, inputs and outputs possible. We want to learn everything in the training and then through model architecture, we will make various engineering decisions to make the model inference/serving much more efficient(routing, MoE, sparse parts of the model).
This also fits in the multi-model learning paradigm well as well. Arguably the modality of the input will define what parts of the model that it can trigger/highlight and then model will only trigger those parts that will correspond to that modality.