
Kaggle AI Report, Pinterest's Diverse Recommendation System
Kaggle AI Report, Pinterest's Diverse Recommendation System
Programming Language for LLMs!(LMQL)

Kaggle published their AI report for 2023 in here. It has 71 slides and I highly encourage you to check out to understand where the industry is and where it is going.
It covers mainly six sections:
Generative AI:
A frontier of machine learning that is coming into new focus in the last few years, this area has combined the best of text and image research to create a fundamental shift in the usability and utility of machine learning models.
Text data:
Natural language processing and statistical language modeling are the backbone of some of the most exciting recent advances in AI.
Image / video data:
Image data was the foundation for early advances in deep learning and the past decade is a testament to the ingenuity of researchers and practitioners in this area, with ever-expanding datasets and problem formulations met with fresh, new ideas.
Tabular / time series data:
Tabular data problems are the most common type of problem to solve, and an area that has led to incredible research and development – some by our very own community members.
Kaggle competitions:
Kaggle is perhaps most famous for its competitions, curated and led with care by our team of experts, in partnership with hosts including researchers, educators, and industry giants. Competitions present cutting-edge problems and challenges that our diverse community solves in myriad exciting ways.
AI ethics:
Humans in the world of machine learning have always struggled to make our discoveries fair, unbiased, and equitable for other people.

I loved the following notebook that shows the developments in Generative AI really well. It is kind of a survey of surveys to show year over year developments in Generative AI.
I really liked the following notebook on LLM development and its developments over time.
Honorable mention is the following notebook that goes in depth for different optimization algorithms for various deep learning models. There are at least 3 notebooks for each section that totals in 20+ notebooks, I recommend checking the full report and skimming over the notebooks.
Articles

Pinterest wrote about how they are using models to identify different attributes in images, such as skin tone and body type. This information is then used to make sure that users see a variety of results when they search. In order to do that, they use a transformer-based unified visual embedding model to power the body type signal. This model is trained on a dataset of thousands of fashion Pins that have been labeled with body type information. The model is able to identify unique patterns and characteristics in these images that may provide a basis for meaningful groupings. This way they can customize and provide diverse set of results in the fashion domain and tailor the search results against the customer preference.
They still use Determinental Point Processes similar to their earlier post given its flexibility. Since DPP takes into account both the utility scores from ranking models and similarity scores with respect to the diversification dimensions, trade-off and tune it appropriately for different surfaces and their cases Multiple diversity dimensions, DPP can be operationalized with a joint similarity matrix to account for the intersectionality between different dimensions. A simpler option, which also offers more flexibility in terms of how similarity between items is defined, is to add a new diversity term per dimension in the weighted sum between the utility term and the, now several, diversity terms used to solve the DPP optimization. It is actually the later approach that they have opted in.
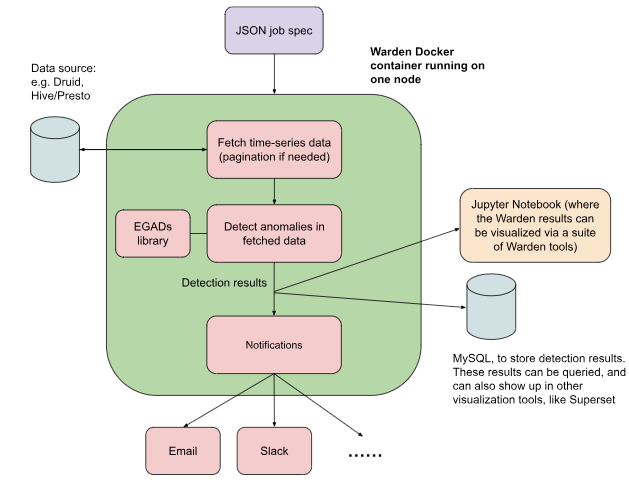
Pinterest wrote a blog post to show howto federate to build an anomaly detector through their platform.
The platform is more like an interface to write an anomaly detector algorithm especially on a time series and after you write the anomaly detector against those timestamps, it can deploy the algorithm very easily and relatively easy manner.
Libraries

Arckit provides tools for loading the data in a friendly format (without a separate download!), visualizing the data with high-quality vector graphics, and evaluating models on the dataset.
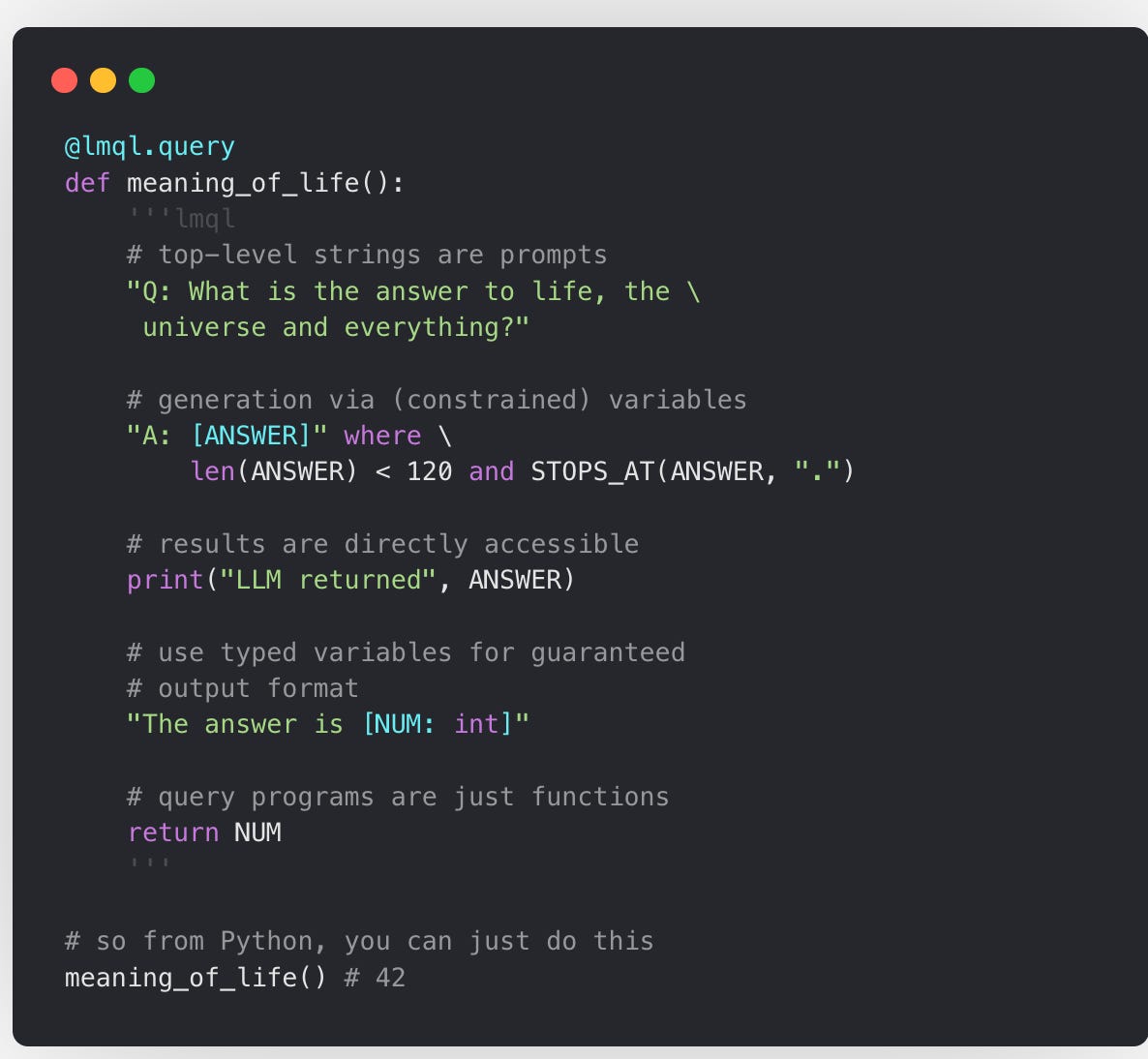
LMQL is a programming language for large language models (LLMs) based on a superset of Python. LMQL offers a novel way of interweaving traditional programming with the ability to call LLMs in your code. It goes beyond traditional templating languages by integrating LLM interaction natively at the level of your program code.
The bitsandbytes is a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and quantization functions.

LibMTL is an open-source library built on PyTorch for Multi-Task Learning (MTL).
Lean 4 is a functional programming language that makes it easy to write correct and maintainable code. You can also use Lean as an interactive theorem prover. Lean programming primarily involves defining types and functions. This allows your focus to remain on the problem domain and manipulating its data, rather than the details of programming.