Human in the Loop in Fraud Detection
OpenAI builds an instructional following large-scale models

Libraries
Electra (Efficiently Learning an Encoder that Classifies Token Replacements Accurately), is a novel pre-training method for language representations which outperforms existing techniques, given the same compute budget on a wide array of Natural Language Processing (NLP) tasks.
Colossal-AI is an integrated large-scale model training system with a number of parallelization techniques. There is also a good video that shows a comparison between this library and other libraries that solve similar problems.
Bagua is a deep learning training acceleration framework for PyTorch.
Advanced Distributed Training Algorithms: Users can extend the training on a single GPU to multi-GPUs (may across multiple machines) by simply adding a few lines of code (optionally in elastic mode). One prominent feature of Bagua is to provide a flexible system abstraction that supports state-of-the-art system relaxation techniques of distributed training. So far, Bagua has integrated communication primitives including
Centralized Synchronous Communication (e.g. Gradient AllReduce)
Decentralized Synchronous Communication (e.g. Decentralized SGD)
Low Precision Communication (e.g. ByteGrad)
Asynchronous Communication (e.g. Async Model Average)
Cached Dataset: When data loading is slow or data preprocessing is tedious, they could become a major bottleneck of the whole training process. Bagua provides cached dataset to speedup this process by caching data samples in memory, so that reading these samples after the first time becomes much faster.
TCP Communication Acceleration (Bagua-Net): Bagua-Net is a low level communication acceleration feature provided by Bagua. It can greatly improve the throughput of AllReduce on TCP network. You can enable Bagua-Net optimization on any distributed training job that uses NCCL to do GPU communication (this includes PyTorch-DDP, Horovod, DeepSpeed, and more).
Performance Autotuning: Bagua can automatically tune system parameters to achieve the highest throughput.
Generic Fused Optimizer: Bagua provides generic fused optimizer which improve the performance of optimizers by fusing the optimizer
.step()operation on multiple layers. It can be applied to arbitrary PyTorch optimizer, in contrast to NVIDIA Apex's approach, where only some specific optimizers are implemented.Load Balanced Data Loader: When the computation complexity of samples in training data are different, for example in NLP and speech tasks, where each sample have different lengths, distributed training throughput can be greatly improved by using Bagua's load balanced data loader, which distributes samples in a way that each worker's workload are similar.
EvoJAX is a scalable, general purpose, hardware-accelerated neuroevolution toolkit. Built on top of the JAX library, this toolkit enables neuroevolution algorithms to work with neural networks running in parallel across multiple TPU/GPUs. EvoJAX achieves very high performance by implementing the evolution algorithm, neural network and task all in NumPy, which is compiled just-in-time to run on accelerators.
moolibis an RPC library to help you perform distributed machine learning research, particularly reinforcement learning. It is designed to be highly flexible and highly performant.It is flexible because it allows researchers to define their own training loops and data-collection policies with minimal interference or abstractions -
moolibgets out of the way of research code.It is performant because it gives researchers the power of efficient data-parallelization across GPUs with minimal overhead, in a manner that is highly scalable.
Articles
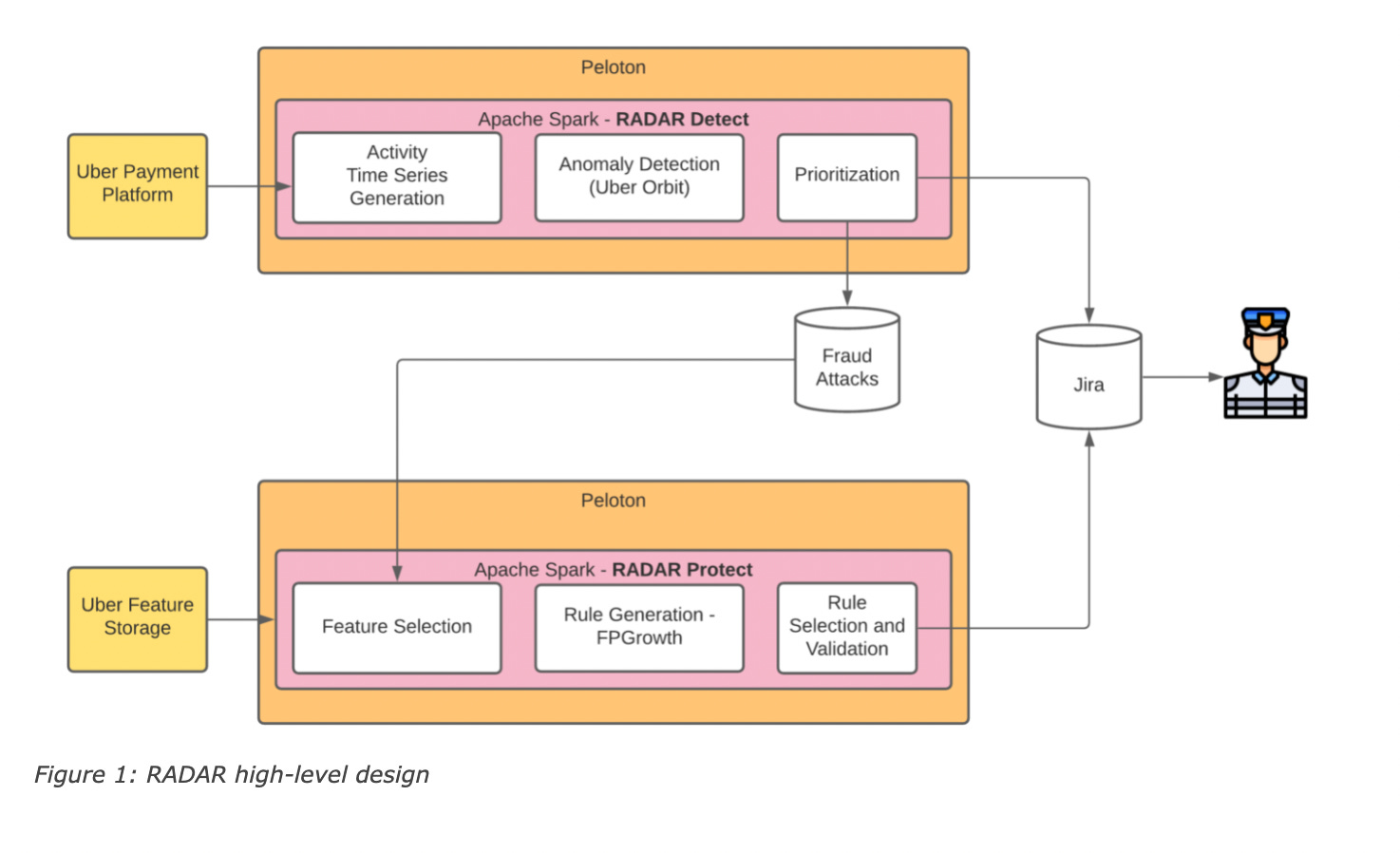
Uber wrote about how they built RADAR which is an Intelligent Early Fraud Detection System with Humans in the Loop.
In the system, there is also a component that does data mining on top of fraudulent activities to understand what it makes to to be a fraudulent activity within all of the features that compose a particular payment.


Google Cloud AI Research wrote a blog post that explains how to use rule based system in a neural network system.
Rules can provide the following benefits in a neural network:
Rules can provide extra information for cases with minimal data, improving the test accuracy.
A major bottleneck for widespread use of DNNs is the lack of understanding the rationale behind their reasoning and inconsistencies. By minimizing inconsistencies, rules can improve the reliability of and user trust in DNNs.
DNNs are sensitive to slight input changes that are human-imperceptible. With rules, the impact of these changes can be minimized as the model search space is further constrained to reduce underspecification.

OpenAI wrote a blog post on how to follow instructions better to create a high alignment between user and researchers.
OpenAI collected a dataset of human-written demonstrations on prompts submitted to their API, and use this to train their supervised learning baselines.
Next, they collect a dataset of human-labeled comparisons between two model outputs on a larger set of API prompts.
They then train a reward model (RM) on this dataset to predict which output our labelers would prefer.
Finally, they use this RM as a reward function and fine-tune our GPT-3 policy to maximize this reward using the PPO algorithm.