
Articles

Infini-gram is a new approach in language modeling, offering a modern revival of n-gram language models (LMs) at scale. This system processes n-gram queries with unbounded context length across trillion-token corpora with remarkable efficiency. The project scales traditional n-gram approaches to 5 trillion tokens—containing approximately 5 quadrillion unique n-grams—making it the largest n-gram language model ever created. Infini-gram achieves millisecond-level query processing, demonstrating that classical statistical language modeling approaches remain relevant and they are complementary to neural methods in the era of large language models(LLMs).
Infini-gram modernizes traditional n-gram language models in two fundamental ways:
massive scaling of training data
removal of context length constraints.
The system processes n-gram queries across an unprecedented volume of 5 trillion tokens, combining several major open-source text corpora including Dolma (3T tokens), RedPajama (1.4T tokens), Pile (380B tokens), and C4 (200B tokens). This represents the largest n-gram language model ever created, surpassing previous implementations by orders of magnitude.
The most significant technical innovation is the expansion of "n" from traditionally small fixed values (typically ≤5) to an unbounded approach, and therefore the name of "∞-gram LM." Traditional n-gram models were constrained to small context windows because the computational requirements grew nearly exponentially with increasing n-values. Infini-gram overcomes this limitation through a variant of the backoff approach, where the system resorts to smaller n-values only when longer n-grams have zero counts. This enables the model to utilize the maximum possible context, significantly improving prediction accuracy compared to fixed-length n-gram models.

The technical architecture powering Infini-gram is based on suffix arrays, a data structure that stores the ranking of all suffixes of a byte array. The byte array represents the concatenation of all tokenized documents in the training corpora. The suffix array occupies O(N) space and can be constructed in O(N) time, making it remarkably efficient for the scale involved. This approach eliminates the need to precompute and store massive n-gram count tables, which would be prohibitively expensive for unbounded n-values.

Performance metrics demonstrate extraordinary efficiency: n-gram counting operations complete in approximately 20 milliseconds regardless of n-gram length when querying the RedPajama corpus (1.4T tokens). N-gram language model probability estimation and decoding functions remain under 40 milliseconds per query, while the ∞-gram functionality takes slightly longer (under 200 milliseconds) as it must determine the longest possible n. Perhaps most impressively, these operations require minimal computational resources, functioning effectively with only CPU and RAM, as the index can remain on disk during inference. The system requires "0 GPU for both training and inference," distinguishing it from resource-intensive neural approaches.

The ∞-gram framework enabled novel analyses of both human-written and machine-generated text. ∞-gram language model achieves surprisingly high accuracy for next-token prediction at 47%, outperforming traditional 5-gram models which achieve only 29%. Prediction accuracy increases significantly when utilizing larger context windows and when ∞-gram estimates are sparse.
More details about the approach and paper are available in here and code is also available in GitHub.

Eugene Yan wrote an excellent piece on how LLM can be used in recommendations systems by reviewing a number of different papers from companies that work on or does research in recommendations space.
I want to categorize these into 4 main areas:
Augmented Model Architecture → LLM for Recsys
LLM for Data
LLM for Scale on a budget
Unified Model Architecture → LLM as Recsys
1. LLM for Recsys
Recommender systems are evolving beyond traditional ID-based approaches by integrating semantic understanding through LLMs and multimodal fusion. These architectures address cold-start challenges while improving interpretability.

Semantic IDs (YouTube)
Innovation: Replaces arbitrary item IDs with content-derived identifiers that preserve semantic relationships.
How:
Multimodal Encoding: A transformer model processes video frames and audio tracks into dense embeddings, capturing temporal relationships through cross-attention layers.
Hierarchical Compression: The Residual Quantization VAE progressively compresses embeddings into 8 discrete codes, where each layer refines the reconstruction error from previous steps. This allows efficient nearest-neighbor searches while maintaining item similarity.
Adaptive Tokenization:
N-gram Hashing splits IDs into fixed-length segments for embedding table lookup, enabling partial matches.
SentencePiece learns variable-length subword units from ID distributions, better handling long-tail items through adaptive grouping.
Why It Works: By encoding content features directly into IDs, the system preserves item relationships even for new entries. The hierarchical compression balances reconstruction accuracy with storage efficiency.

M3CSR (Kuaishou)
Innovation: Aligns user behavior with multimodal content clusters to bridge the semantic gap.
How:
Modality-Specific Processing:
Visual content passes through ResNet with attention pooling to emphasize salient regions.
Text descriptions encode via Sentence-BERT with contrastive learning to separate dissimilar items.
Cluster-Based Alignment: K-means++ groups items into 1,000 content clusters, creating interpretable categories that remain stable across updates.
Dual-Tower Interaction:
The user tower processes behavior sequences through GRUs with modality-specific attention.
The item tower maps cluster memberships to dense embeddings using modality gates that dynamically adjust feature importance.

Why It Works: Clusters act as semantic anchors, allowing the model to generalize across items with similar characteristics. The modality gating mechanism prevents noisy features from dominating predictions.

FLIP (Huawei)
Innovation: Unifies tabular user data and LLM-processed text through cross-modal pretraining.
How:
Tabular-to-Text Conversion: Templates transform user interaction logs into natural language sentences, preserving metadata like timestamps and categories.
Masked Pretraining:
Randomly masks tabular fields (e.g., user IDs) and text tokens, forcing the model to reconstruct both modalities.
Contrastive learning aligns text and tabular embeddings in a shared space.
Adaptive Fusion: A gating network dynamically combines text and tabular features based on prediction confidence, falling back to ID-based patterns when text is ambiguous.

Why It Works: The joint training process creates a shared representation space where user behavior and content descriptions mutually enhance predictions. The fallback mechanism maintains robustness.

CALRec (Google)
Innovation: Adapts LLMs for sequential recommendation through instruction tuning.
How:
Prompt Engineering: Converts user histories into natural language sequences with explicit instructions like "Recommend items similar to [target]."
Two-Stage Training:
General Pretraining on 100M interactions across diverse categories builds foundational understanding.
Category-Specific Finetuning sharpens predictions through contrastive learning, separating relevant items from hard negatives.
Candidate Generation: Temperature-controlled sampling produces diverse candidates, which BM25 matches against the catalog using title/description similarity.

Why It Works: The LLM’s inherent language understanding allows it to infer subtle relationships (e.g., "wireless headphones → noise-canceling earbuds") that ID-based models miss.

2. LLM for Data
LLMs are changing training data by generating synthetic training examples and refining metadata.

Bing’s Metadata Pipeline
How:
GPT-4 Annotation: Generates concise titles and snippets while adhering to guidelines like "avoid clickbait" and "include key entities."
Distillation: Trains Mistral-7B using confidence-weighted examples, focusing on high-certainty GPT-4 predictions. The student model gradually learns to match both output text and embedding distributions.
Why It Works: GPT-4’s strong language understanding produces high-quality labels, while distillation maintains quality at scale.
Spotify’s Synthetic Queries
How:
Query Generation: Doc2query-T5 produces multiple search-like queries per playlist (e.g., "upbeat workout songs") through beam search with length normalization.
LLM Filtering: GPT-4 evaluates query-playlist relevance using chain-of-thought prompting ("Analyze the relationship between the query and playlist themes").
Why It Works: Synthetic queries expand coverage for long-tail content, while LLM filtering ensures training data quality. The combination mimics human search behavior.

3. LLM for Scale on a budget
LLM can improve the model performance while still within computational constraints for a recommender system.

Parameter-Efficient Designs
Key Strategies:
Cluster-Based Compression: M3CSR’s 1,000 clusters reduce embedding dimensions while preserving neighborhood relationships.
Quantization: Semantic IDs’ 8-layer hierarchy achieves near-lossless compression through residual error correction.
Distillation: DLLM2Rec’s importance sampling focuses training on predictions where the teacher model shows high confidence, improving sample efficiency.
Why It Works: These methods maintain model accuracy while drastically reducing memory and compute requirements, enabling deployment on edge devices.

Transfer Learning Paradigms
CALRec’s Approach:
General Pretraining: Exposes the model to diverse interaction patterns across 15 categories.
Category Adaptation: Contrastive finetuning sharpens distinctions between similar items (e.g., different smartphone models).

Why It Works: The initial phase learns universal recommendation principles, while specialization adapts to category-specific nuances.
4. LLM as Recsys
Breaking down silos between search and recommendation systems with LLMs can provide step-function breakthroughs and improve the overall user experience in search and recommendations significantly.
Flan-T5 Adaptation
How:
Vocabulary Extension: Adds item IDs as special tokens initialized via average pooling of existing embeddings.
Multi-Task Training: Alternates between search queries ("Find jazz playlists") and recommendation prompts ("Suggest similar to [item]") within each batch.
Why It Works: Shared parameters enable knowledge transfer - understanding "jazz" in searches improves music recommendations.
Hybrid Retrieval Strategies
Spotify’s System:
Direct Matching: BM25 retrieves items with exact title/artist matches.
Exploratory Generation: LLMs produce conceptual queries ("study focus music") that surface less obvious candidates.
Ranking Fusion: Combines scores from both paths using learnable weights adjusted by user engagement history.
Why It Works: The hybrid approach satisfies both explicit search intent and discovery needs, increasing session depth.
Libraries

OLMOE: Open Mixture-of-Experts Language Models is a fully open, state-of-the-art Mixture of Expert model with 1.3 billion active and 6.9 billion total parameters.

All data, code, and logs released.
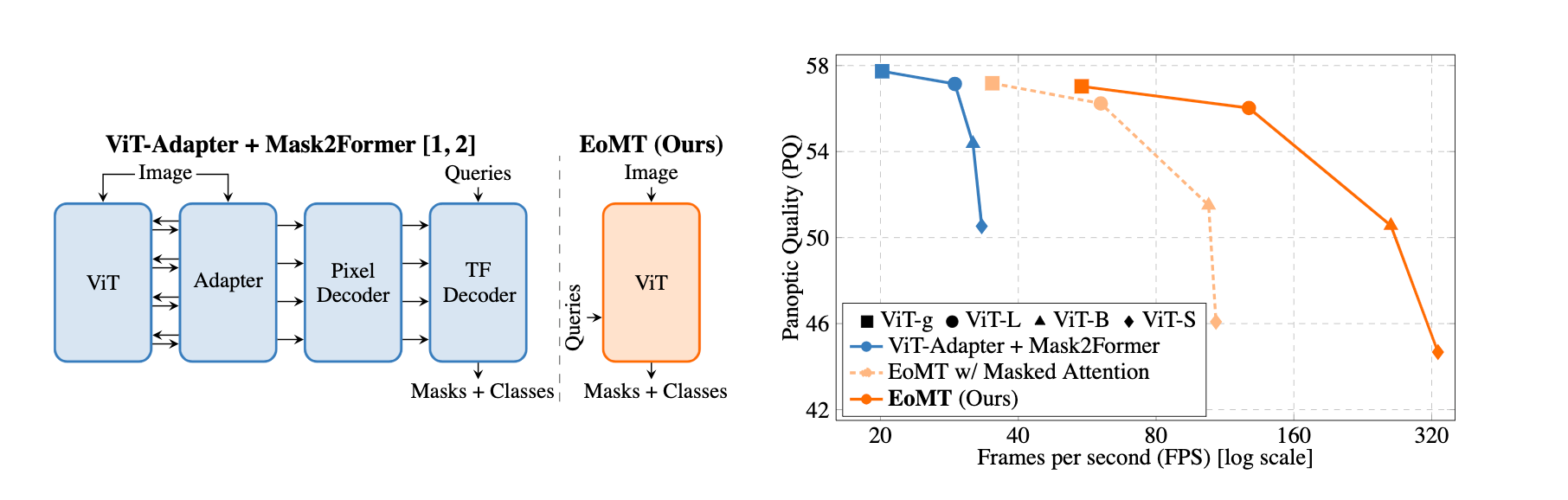
Encoder-only Mask Transformer (EoMT), a minimalist image segmentation model that repurposes a plain Vision Transformer (ViT) to jointly encode image patches and segmentation queries as tokens. No adapters. No decoders. Just the ViT.
Leveraging large-scale pre-trained ViTs, EoMT achieves accuracy similar to state-of-the-art methods that rely on complex, task-specific components. At the same time, it is significantly faster thanks to its simplicity, for example up to 4× faster with ViT-L.
Turns out, your ViT is secretly an image segmentation model. EoMT shows that architectural complexity isn’t necessary, plain Transformer power is all you need.

Moshi is a speech-text foundation model and full-duplex spoken dialogue framework. It uses Mimi, a state-of-the-art streaming neural audio codec. Mimi processes 24 kHz audio, down to a 12.5 Hz representation with a bandwidth of 1.1 kbps, in a fully streaming manner (latency of 80ms, the frame size), yet performs better than existing, non-streaming, codecs like SpeechTokenizer (50 Hz, 4kbps), or SemantiCodec (50 Hz, 1.3kbps).
Moshi models two streams of audio: one corresponds to Moshi, and the other one to the user. At inference, the stream from the user is taken from the audio input, and the one for Moshi is sampled from the model's output. Along these two audio streams, Moshi predicts text tokens corresponding to its own speech, its inner monologue, which greatly improves the quality of its generation. A small Depth Transformer models inter codebook dependencies for a given time step, while a large, 7B parameter Temporal Transformer models the temporal dependencies. Moshi achieves a theoretical latency of 160ms (80ms for the frame size of Mimi + 80ms of acoustic delay), with a practical overall latency as low as 200ms on an L4 GPU.

Learned QD contains the reference implementation for Discovering Quality-Diversity Algorithms via Meta-Black-Box Optimization paper, introducing Learned Quality-Diversity (LQD) a family of meta-optimized evolutionary algorithms designed to efficiently collect stepping stones for open-ended discovery. 🧑🔬
LQD introduces a novel approach to Quality-Diversity (QD) optimization by using meta-learning to discover sophisticated competition rules. Unlike traditional QD algorithms that rely on heuristic-based mechanisms (e.g., grid-based competition in MAP-Elites), LQD leverages attention-based neural architectures to parameterize and learn local competition strategies. These strategies are optimized across diverse black-box optimization tasks, resulting in algorithms that excel at balancing fitness, novelty, and diversity.
Key highlights:
Outperforms or matches established baselines like MAP-Elites, Dominated Novelty Search, Novelty Search, and Genetic Algorithms.
Demonstrates strong generalization to higher dimensions, larger populations, and out-of-distribution domains like robot control.
Naturally maintains diverse populations, even when optimized solely for fitness, rediscovering diversity as a key to effective optimization.
Workshops
Transformers have now been scaled to vast amounts of static data. This approach has been so successful it has forced the research community to ask, "What's next?". This workshop will bring together researchers thinking about questions related to the future of language models beyond the current standard model. The Future of Language Models and Transformers workshop is meant to be exploratory and welcome to novel vectors in which new setups may arise, e.g. data efficiency, training paradigms, and architectures. Some of the workshop sessions are recorded.