
Articles
Traditional search engines on Pinterest relied heavily on user engagement signals and keyword-based retrieval, which often failed to capture nuanced relevance between a user's query and the diverse, multimedia content as they cannot be described or interpreted through the keywords. Pinterest wrote a great blog post on their approach to solve this problem through leveraging large language models (LLMs) to directly model and improve search relevance, resulting in good gains in user experience and engagement.
The article talks about main 4 different directions:
LLM Based X-Encoder
Pin Data Representation for LLM
Knowledge Distillation
Semi-Supervised Learning
which I will expand a bit more and technical details in the following sections:

1. LLM Based X-Encoder
Pinterest introduced a cross-encoder(X-Encoder) LLM as a "teacher" to predict the relevance of Pins to search queries. This model takes both the query and detailed Pin text features as input and outputs a multiclass relevance score, trained using human-annotated data and cross-entropy loss. This approach makes the search to be better than traditional keyword matching, allowing for a deeper semantic understanding of both queries and content of the pins.
LLM-Based X-Encoder Architecture
Input: Both the search query and enriched Pin text features are concatenated and fed into the model.
Model: Fine-tuned transformer-based architectures (e.g., BERT, T5, mDeBERTa, XLM-RoBERTa, Llama-3–8B) are used as cross-encoders.
Task: Multiclass classification, predicting a 5-level relevance score (from "not relevant" to "highly relevant").
Training: Uses human-annotated data, minimizing cross-entropy loss.
2. Pin Data Representation for LLM
To maximize the LLM’s effectiveness on both content and query pairs, Pinterest engineered a comprehensive set of text features for each Pin:
Pin titles/descriptions: Direct user input.
Synthetic captions: Generated using BLIP model, providing descriptive text for images.
High-engagement query tokens: Captures search terms that historically led to high engagement with the Pin.
Board titles: Context from user curation.
Link titles/descriptions: Additional context from external sources.
This multi-source representation of Pins ensure high coverage for queries and quality, enabling the model to better represent and understand and match the intent behind user queries. Ablation studies also show that adding each feature incrementally improves the model’s predictive accuracy, highlighting the importance of feature engineering.

3. Knowledge Distillation
While the LLM-based teacher model is highly accurate, it is computationally expensive and therefore not feasible for real-time production use at Pinterest’s scale. To address this, Pinterest uses knowledge distillation: the teacher model generates relevance labels for billions of query-Pin pairs, which are then used to train a lightweight "student" model. This student model is further optimized for speed and efficiency can be deployed in production to serve search results in real time.
More details with regards to teach and student model and their training paradigm are in the following:
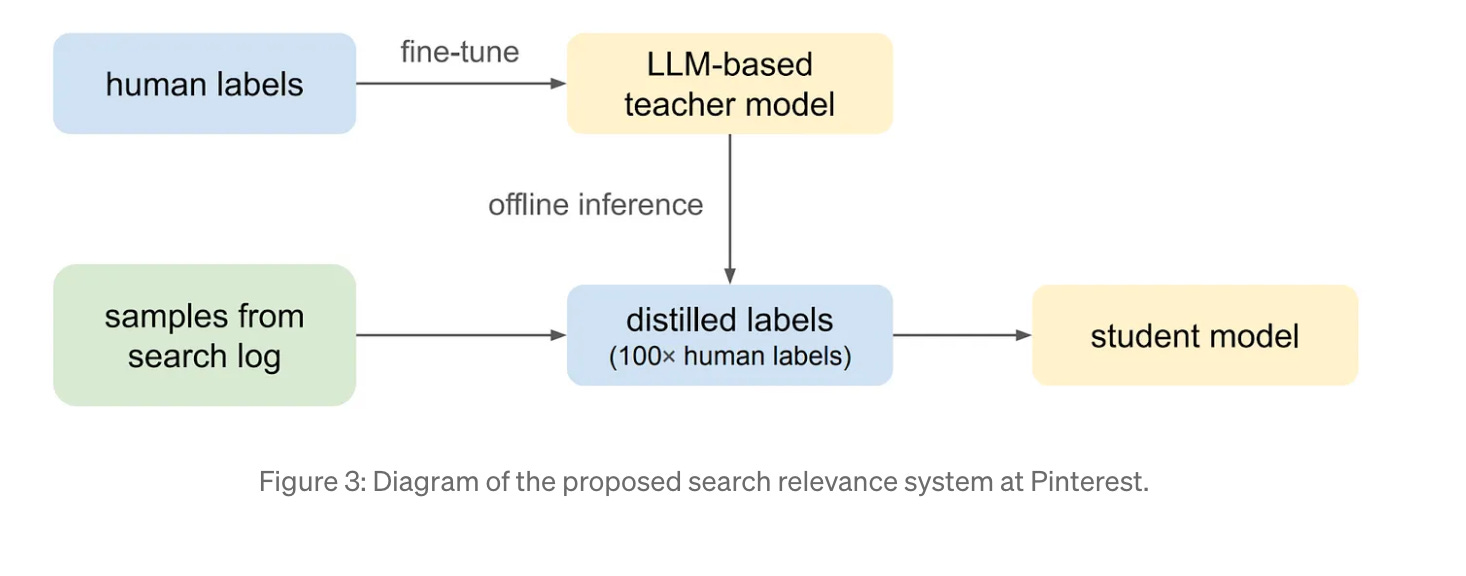
Teacher model (LLM X-encoder): Used offline to generate relevance labels for billions of query-Pin pairs.
Student model: A lightweight feed-forward neural network that ingests:
Query-level features (interest embeddings, SearchSAGE query embeddings)
Pin-level features (PinSAGE embeddings, visual/image embeddings, SearchSAGE Pin embeddings)
Query-Pin interaction features (BM25/text match scores, historical engagement rates)
4. Semi-Supervised Learning
By leveraging the teacher model to label massive amounts of previously unlabeled data, Pinterest significantly expands its training set beyond what is feasible with manual annotation. This semi-supervised learning approach not only increases the volume of training data but also enhances generalization to new languages and concepts, as the teacher model is multilingual and can adapt to seasonal and global trends.
The teacher model, being multilingual, enables the system to generalize to new languages and concepts not present in the original human-labeled data.
This approach allows Pinterest to scale relevance modeling globally, adapting to new trends and seasonal content without requiring manual annotation for every locale.
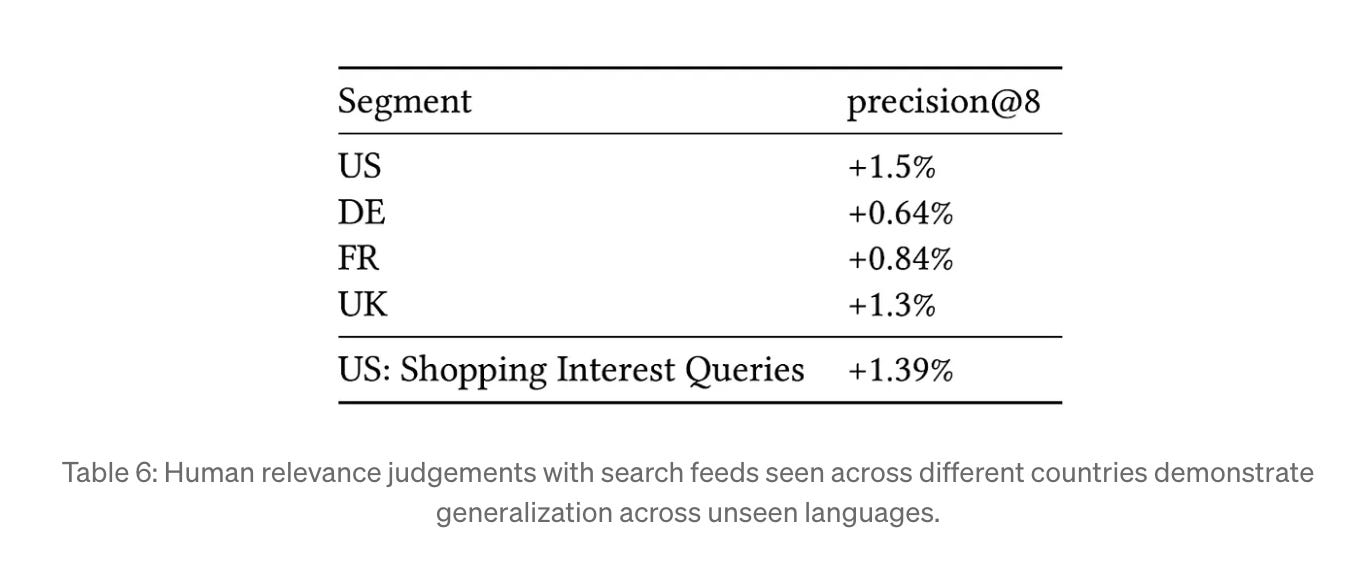
Results are pretty impressive:
LLM-based models (especially larger ones like Llama-3–8B) significantly outperform both traditional embedding-based models and smaller language models in predicting relevance.
Online: A/B tests show over 1% improvement in search feed relevance (nDCG@20) and over 1.5% improvement in search fulfillment rates globally, including in countries and languages not represented in the human-annotated training data, which makes the existing approach to be very generalizable and scalable outside of the training datasets of the Pins.

InstructPipe is a research prototype developed by Google to streamline the creation of machine learning (ML) pipelines in visual programming environments. By leveraging large language models (LLMs) and natural language instructions, InstructPipe automates the selection and connection of nodes in a visual editor, making the process accessible to both novices and experts.

Visual programming frameworks, such as Visual Blocks for ML, allow users to construct computational workflows by connecting modular blocks in a node-graph editor. This low-code approach is designed to lower the barrier for ML prototyping, enabling users to focus on high-level logic rather than intricate coding details.
However, even with visual programming, new users often struggle to set up pipelines from scratch. They must identify, select, and connect appropriate nodes from a blank workspace, which can be daunting and time-consuming, especially for those unfamiliar with ML concepts or the available node types.
InstructPipe addresses these challenges by introducing an AI assistant that translates human instructions into functional visual programming pipelines. Users can describe the desired pipeline in natural language, and InstructPipe automates much of the pipeline construction process.

In order to build such a system, it uses the following components:
Node Selector (LLM Module 1): Given a user instruction and a pipeline tag (e.g., “multimodal”), this module identifies a list of potentially relevant nodes. It uses brief node descriptions to filter out unrelated options.
Code Writer (LLM Module 2): Receives the selected nodes and user input, then generates pseudocode that defines the structure and connections of the pipeline. This module is provided with detailed node descriptions and examples for context.
Code Interpreter: Parses the generated pseudocode and renders the pipeline as a directed acyclic graph (DAG) in the visual editor, enabling further human-AI collaboration.

Pipelines in Visual Blocks are typically represented as verbose JSON files. InstructPipe introduces a pseudocode format that is highly token-efficient, compressing a 2,800-token JSON pipeline into a 123-token representation. This concise format maintains essential structural information while sacrificing some fine-grained annotations.
Libraries
TritonAcademy has a number of resources for Triton and tooling around Triton. Triton is an open-source programming language and compiler designed specifically for GPU programming. It aims to simplify the development of efficient GPU kernels by providing a higher-level abstraction than CUDA or other low-level GPU programming models.
Triton enables developers to write high-performance GPU code with Python-like syntax while automatically handling many low-level optimizations that would otherwise require significant expertise in GPU architecture. It was developed by OpenAI and is now widely used in machine learning and scientific computing applications.
Tutorials for Triton can also be a good accompanying site to provide complementary resources.

LightlyTrain brings self-supervised pretraining to real-world computer vision pipelines, using your unlabeled data to reduce labeling costs and speed up model deployment. Leveraging the state-of-the-art from research, it pretrains your model on your unlabeled, domain-specific data, significantly reducing the amount of labeling needed to reach a high model performance.
This allows you to focus on new features and domains instead of managing your labeling cycles. LightlyTrain is designed for simple integration into existing training pipelines and supports a wide range of model architectures and use-cases out of the box.

Why LightlyTrain
💸 No Labels Required: Speed up development by pretraining models on your unlabeled image and video data.
🔄 Domain Adaptation: Improve models by pretraining on your domain-specific data (e.g. video analytics, agriculture, automotive, healthcare, manufacturing, retail, and more).
🏗️ Model & Task Agnostic: Compatible with any architecture and task, including detection, classification, and segmentation.
🚀 Industrial-Scale Support: LightlyTrain scales from thousands to millions of images. Supports on-prem, cloud, single, and multi-GPU setups.

Chain-of-Experts (CoE) changes sparse Large Language Model (LLM) processing by implementing sequential communication between intra-layer experts within Mixture-of-Experts (MoE) models.
Mixture-of-Experts (MoE) models process information independently in parallel between experts and have high memory requirements. CoE introduces an iterative mechanism enabling experts to "communicate" by processing tokens on top of outputs from other experts.
Experiments show that CoE significantly outperforms previous MoE models in multiple aspects:
Performance: CoE with 2x iterations reduces Math validation loss from 1.20 to 1.12
Scaling: 2x iterations matches performance of 3x expert selections, outperforming layer scaling
Efficiency: 17.6% lower memory usage with equivalent performance
Flexibility: 823x increase in expert combinations, improving utilization, communication, and specialization
These advantages constitute a "free lunch" effect, enabling efficient scaling of LLMs.

Mem0 (pronounced as "mem-zero") enhances AI assistants and agents with an intelligent memory layer, enabling personalized AI interactions. Mem0 remembers user preferences, adapts to individual needs, and continuously improves over time, making it ideal for customer support chatbots, AI assistants, and autonomous systems.

DiffMM is a new multi-modal recommendation model that enriches the probabilistic diffusion paradigm by incorporating modality awareness. It utilizes a multi-modal graph diffusion model to reconstruct a comprehensive user-item graph, while harnessing the advantages of a cross-modal data augmentation module that provides valuable self-supervision signals.

Reinforcement Learning (RL) with rule-based rewards has shown promise in enhancing reasoning capabilities of large language models (LLMs). However, existing approaches have primarily focused on static, single-turn tasks like math reasoning and coding. Extending these methods to agent scenarios introduces two fundamental challenges:
Multi-turn Interactions: Agents must perform sequential decision-making and react to environment feedback
Stochastic Environments: Uncertainty where identical actions can lead to different outcomes
RAGEN addresses these challenges through:
A Markov Decision Process (MDP) formulation for agent tasks
Reason-Interaction Chain Optimization (RICO) algorithm that optimizes entire trajectory distributions
Progressive reward normalization strategies to handle diverse, complex environments

STORM: Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking is an LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.

marimo is a reactive Python notebook: run a cell or interact with a UI element, and marimo automatically runs dependent cells (or marks them as stale), keeping code and outputs consistent. marimo notebooks are stored as pure Python, executable as scripts, and deployable as apps.
VILA is a family of open VLMs designed to optimize both efficiency and accuracy for efficient video understanding and multi-image understanding.
Recoder is a fast implementation for training collaborative filtering latent factor models with mini-batch based negative sampling following recent work:
Tutorials
Simons Institute and SLMath Joint Workshop: AI for Mathematics and Theoretical Computer Science
A very simple language model based on counting consecutive tokens.
Implement and train a simple Transformer language model.
Train a model for four-digit addition.
Train a model to generate triangle-free graphs.
Below the Fold

cobalt is a media downloader that doesn't piss you off. it's friendly, efficient, and doesn't have ads, trackers, paywalls or other nonsense.
paste the link, get the file, move on. that simple, just how it should be.

Upscayl lets you enlarge and enhance low-resolution images using advanced AI algorithms. Enlarge images without losing quality.
Apple Section
I have recently started looking into CoreML and found some good resources in the intersection of ML and CoreML(machine learning framework by Apple):
iOS-learning-materials is a resource for web-resources, tutorials,
Stack OverflowandQuoraQ&A,GitHubcode repositories and useful resources that may help you dig a little bit deeper into iOS. All the resources are split into sub-categories which simlifies navigation and management.

neural-engine is a comprehensive repo that goes over neural engine aspects. Apple-Silicon-Guide is another resource for Apple’s specific chips and how to use them. CoreML Kit covers the software library that builds on top of the apple silicon.
NSFWDetector is a small (17 kB) CoreML Model to scan images for nudity. It was trained using CreateML to distinguish between porn/nudity and appropriate pictures. With the main focus on distinguishing between instagram model like pictures and porn.
Lumina gives you an opportunity to skip having to write AVFoundation code, and gives you the tools you need to do anything you need with a camera you've already built.
This repository has a collection of Open Source machine learning models which work with Apples Core ML standard.
Apple has published some of their own models. They can be downloaded here. Those published models are: SqueezeNet, Places205-GoogLeNet, ResNet50, Inception v3, VGG16 and will not be republished in this repository.

SimilaritySearchKit is a Swift package enabling on-device text embeddings and semantic search functionality for iOS and macOS applications in just a few lines. Emphasizing speed, extensibility, and privacy, it supports a variety of built-in state-of-the-art NLP models and similarity metrics, in addition to seamless integration for bring-your-own options.

CoreML Model Zoo has a lot of models published by Apple and other companies.