
Graph Neural Networks
Graph Neural Networks
Wild Distribution Shifts, One-shot NAS and Vertex Vector Similarity

This week, we are starting with a pretty theoretical article from Twitter where Twitter motivates how GNN(Graph Neural Network)s can be considered as Partial Differential Equation(PDE)s. This line of work and other line of work around geometric deep learning tries to motivate why these architectures might be better in terms of analytical/mathematical sense rather than most of the research in deep learning which is heavily biased towards empirical results.
We have a data distribution article from Stanford as the second article and in this article, they are talking about how to detect and mitigate the data distribution shift(training and test set are not similarly distributed). They have an open source package that you can use if data distribution shift is something that is problematic in your flow.
Third article is from Pinterest on the architecture that they have for their recommendation engine on the ads. If you have a recommendation engine which is completely embedding based(especially, two tower; user and ads towers), it would be perfect fit. I especially liked the comparison between regression based model to similarity based and why they went with a regression based models.
Facebook published a post around one-shot Neural Architecture Search(NAS) which follows a paper that has been published to do NAS as one-shot learning problem from larger supernet. If you are using NAS and spending a lot of GPU hours, this article might give your couple of ideas on how to reduce your AWS bill.
Google/IO announced a large number of offerings last month that I shared in this newsletter. Among one of them is Vertex vector similarity library which is the topic of the article below. In this space, I see Pinecone which provides an API for indexing and search, there is FAISS which is widely used and there are also search libraries that support vector based similarity search like Vespa and ElasticSearch.
Uber published a comprehensive article where they went through all of the data pipeline architecture for analyzing customer data for different application(Rider, Driver, Eater).
Without further ado, let’s enjoy this week’s articles!
Bugra
Articles
Twitter wrote a good blog post on GNN and how GNNs can be considered as PDEs.

Stanford AI Lab wrote a post that explains WILDS paper. It is also open source package and its source is available in here.

Pinterest wrote how they build an ads system based based on a regression-based deep learning model that is built on top of MLPs(Multi-Layer Perceptron). They compare various architectures with a list of pros-cons along with the loss function. Ads and recommendation engine people should read this post.
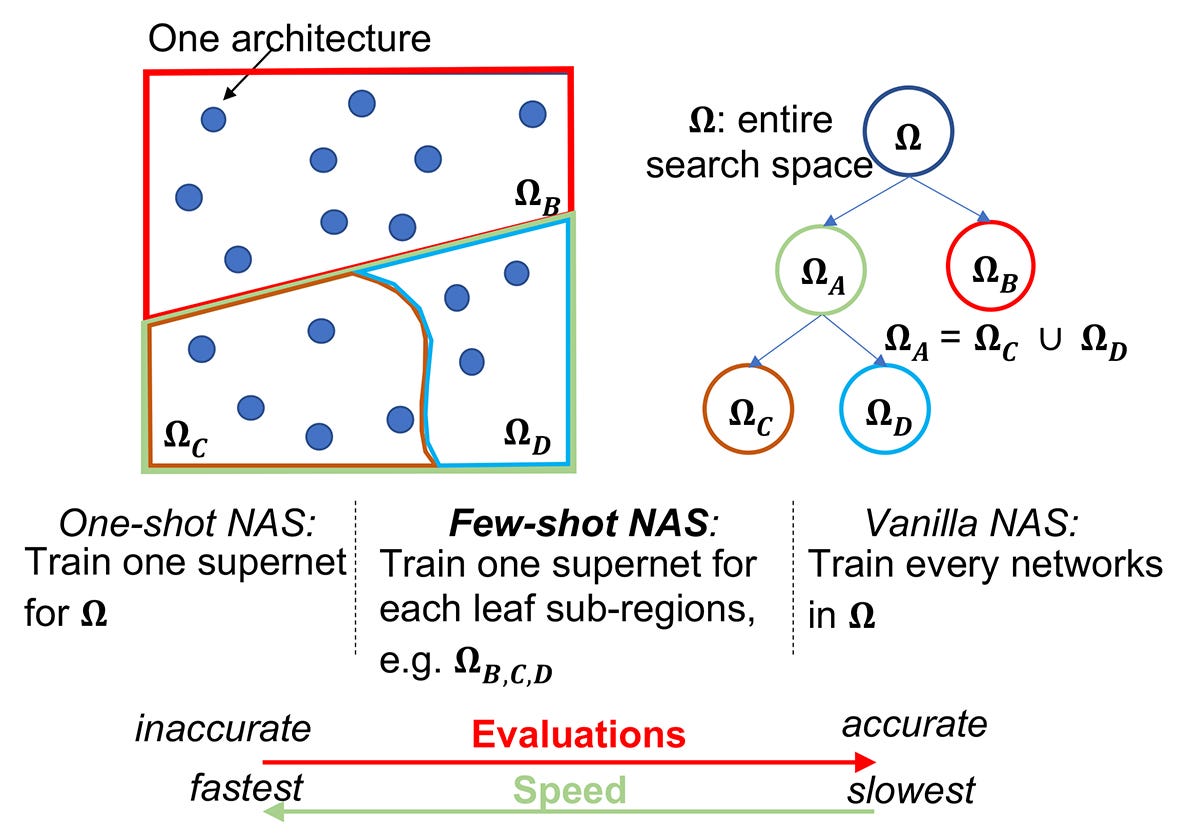
Facebook wrote a post on how to do one-shot NAS(Neural Architecture Search). The code is available in here and paper is in here.

Google cloud has a vector similarity search offering outlined in here. The research that powers this application is in here.
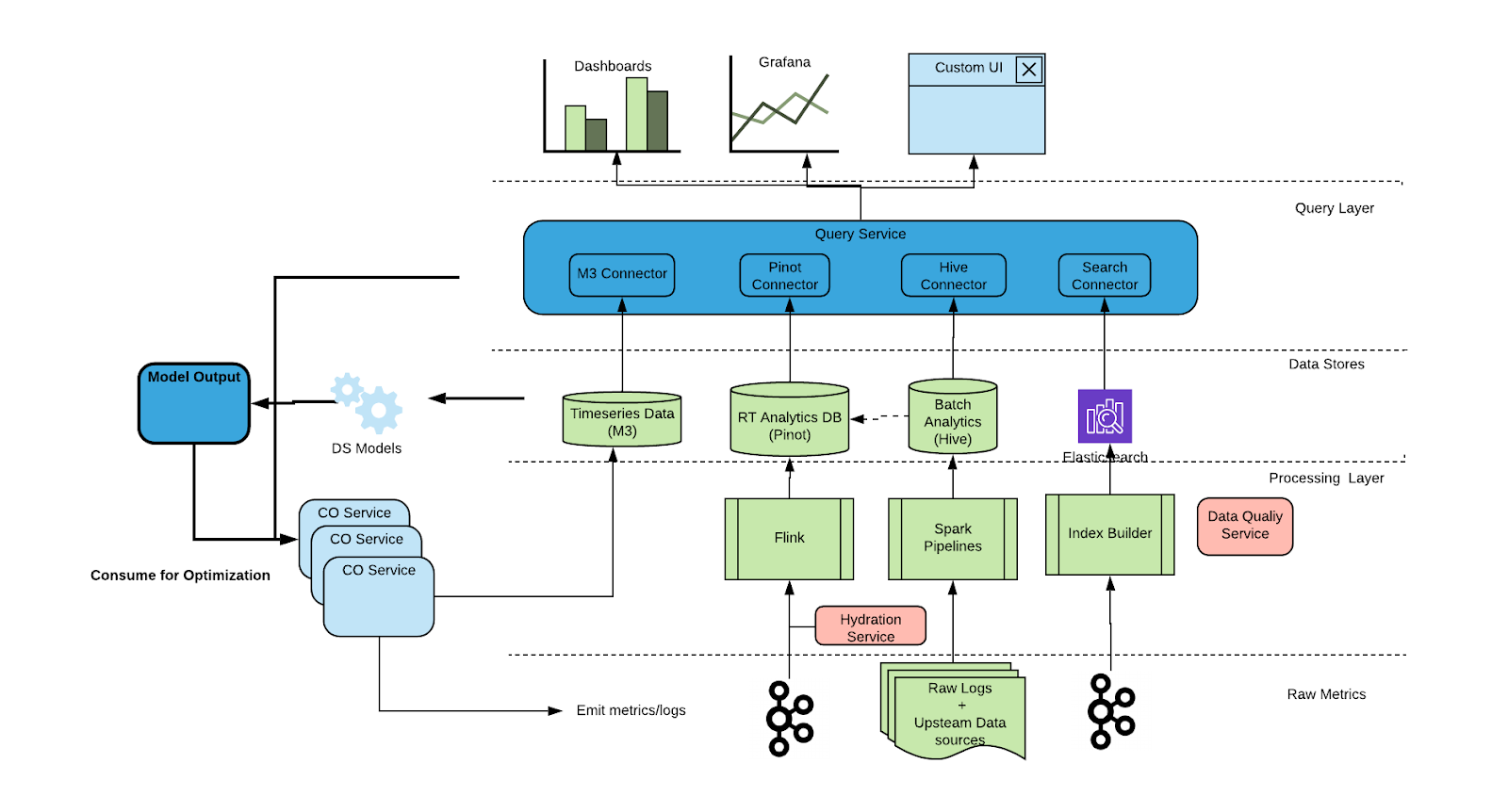
Uber published another nice article on their end to end data pipeline to analyze customer experience. In the previous newsletter, I also shared how they do CI/CD pipeline as well for ml models. Similar to the previous article, this article is very comprehensive and explains different aspects of the data pipeline(multi-app support, real-timeishness, etc).
Pinterest also publishes certain articles in Spanish in their medium page. If you speak Spanish, you should check it out.
Papers
Google published a paper titled Benchmark Lottery. This paper suggests similar to Lottery Ticket Hypothesis(mentioned in this newsletter), some of the algorithms/architectures success is highly dependent on the dataset and the way benchmark is actually executed. They propose a number of best practices which follows the biases that researchers had when they publish benchmark results such as dataset selection bias. The paper is long, but is not too technical and has a number of good suggestions that can be applicable not just for benchmark but dataset curation and generally for research.
Evaluating large models in the code is a paper from OpenAI that explains GitHub’s famous CoPilot application. It is an interesting read along with the metric that they chose to evaluate the success of the model(pass@k).
QUEEN: Neural Query Rewriting in E-commerce is a paper transformer based rewriter for the search queries in an ecommerce setting. They train a sequence to sequence model where they specify a “source” and a “target” query. The way they come up with a dataset of source-target pair is very standard and in the following way:
Start a product search session by searching with a query.
No action is taken on the current search result.
Start a second product search with a rewritten query.
Click/purchase on the search result of the rewritten query.
Rather than curating the dataset manually, it is a nice way to leverage search logs among different users to come up with a better query formulation.
A tale of two long tails defines two different errors in training of neural networks. Epistemic and aleatoric errors where the first one refers to the errors that model “can do better” with the dataset that it has seen, these are also referred as “reducible error” and the other one is model “cannot do better” with the dataset that it has seen to correctly label the instance as the dataset it has seen and the test set it has been getting tested has a lot of uncertainty. This paper defines these errors and how to mitigate them in the training process. They suggest data augmentation, data cleaning(especially epistemic error ones).
Libraries
modelvshuman is a library that benchmarks PyTorch and Tensorflow models between various algorithms and humans.
Microsoft has a Human AI interaction guideline available in here. It covers anything from how AI should behave under various circumstances to how UI should look like.
Deepmind has open-sourced software that can download Wikigraphs dataset.
Deepmind has open-sourced also an image library for Jax, called Pix.
Microsoft has an automl toolkit called nni, that does not only model optimization (quantization, pruning), but also neural architecture search. From what I see, it supports both PyTorch and Tensorflow.