GPT-4o
Suppose we directly model p(text, pixels, sound) with one big autoregressive transformer

Articles

OpenAI has announced GPT-4o, their new flagship AI model that can reason across audio, vision, and text in real-time. The "o" stands for "omni", reflecting its multimodal capabilities to accept inputs and generate outputs across different modalities like text, audio, and images. A key breakthrough is GPT-4o's ability to respond to audio inputs with very low latency - as little as 232 milliseconds on average, which is similar to human response times in conversation. This enables much more natural voice interactions compared to previous models. GPT-4o matches the text performance of GPT-4 on English and coding tasks, while providing significant improvements on non-English languages. It is also 50% cheaper to run via the API compared to GPT-4. It is all around a significant improvement, but it is not as big of a leap that does not justify the version to be GPT-5, I expect a larger improvement for GPT-5 overall.
Compared to previous voice models that used a pipeline of separate speech recognition, language understanding, and speech synthesis models, GPT-4o is an end-to-end model that directly maps audio to audio or audio/visuals to text.

On benchmarks like the MMLU general knowledge test, GPT-4o sets new state-of-the-art scores, achieving 88.7% accuracy versus humans at 94%. It also shows improved reasoning abilities compared to GPT-4.The blog post acknowledges that while GPT-4o represents a significant step forward, all AI models including this one have limitations in terms of biases, hallucinations, and lack of true understanding.
OpenAI has wrote another blog post around data analysis capabilities of the ChatGPT.
It has a number of neat capabilities that are supported by interactively and iteratively:
File Integration
Users can directly upload data files from cloud storage services like Google Drive and Microsoft OneDrive into ChatGPT for analysis.
This allows easy access to the latest versions of files without having to manually upload or manage local copies.
Interactive Data Visualization
When files are uploaded, ChatGPT automatically generates an interactive table view of the data.
Users can expand this view to full-screen to better explore and understand the data.
By clicking on specific data points or areas, users can ask follow-up questions or select from suggested prompts to dive deeper into analysis.
Chart Customization
ChatGPT can generate visualizations like bar charts, line charts, pie charts, and scatter plots based on the data.
Users can interact with and customize these charts by hovering over elements, changing colors, and applying other formatting options.
The customized charts can then be downloaded for use in presentations, reports, or other documents.
There are also a variety of capabilities that can be very useful for ML/Data Science Practitioners for data related or feature related tasks.
Data Tasks
ChatGPT can handle a wide range of data-related tasks by writing and executing Python code behind the scenes, without users needing coding expertise.
Example tasks include merging datasets, cleaning and transforming data, creating pivot tables, surfacing key insights through analysis, and more.
Looking ahead, some of the capabilities can be even unlocked further interactivity and capabilities in future:
Data Analysis Query Capabilities:
Natural Language Querying: Users could pose data analysis queries in completely natural language, without having to learn SQL or any other querying syntax. ChatGPT would understand the intent behind the query and translate it into the appropriate SQL or Python code to execute against databases or data warehouses.
Multimodal Data Inputs: In addition to text queries, users could provide multimodal inputs like images, audio, or documents, and ChatGPT could extract relevant data from those sources to include in the analysis.
Interactive Query Refinement: ChatGPT could engage in an interactive dialog to refine and clarify the user's data analysis requirements, suggesting additional filters, aggregations, or visualizations based on the initial query.
Automated Query Optimization: By understanding the underlying data schemas and query patterns, ChatGPT could automatically optimize queries for better performance, indexing recommendations, or distributed execution across multiple data sources.
Query Explanation and Debugging: If a query produces unexpected results, ChatGPT could provide detailed explanations of the query logic, identify potential issues or data quality problems, and suggest fixes or alternative approaches.
Data Science Capabilities:
Automated Feature Engineering: Based on the data and problem statement, ChatGPT could recommend relevant features to include in a machine learning model, perform necessary data transformations, and handle missing values or outliers.
Model Selection and Tuning: ChatGPT could guide users through the process of selecting appropriate machine learning algorithms, tuning hyperparameters, and evaluating model performance using techniques like cross-validation or holdout sets.
Explainable AI: For complex models like deep neural networks, ChatGPT could provide explanations for model predictions, identify the most influential features, and surface potential biases or fairness issues.
Automated Machine Learning (AutoML): By leveraging its knowledge of data science techniques and best practices, ChatGPT could automate the entire end-to-end machine learning pipeline, from data preparation to model deployment and monitoring.
Multimodal Model Inputs: Similar to data analysis, ChatGPT could enable training machine learning models on multimodal data sources like text, images, audio, and video, expanding the range of potential use cases.
Continuous Learning and Model Updates: As new data becomes available or patterns change, ChatGPT could facilitate continuous learning and updating of deployed machine learning models to maintain their accuracy and relevance.
Thoughts
In the rapidly evolving world of artificial intelligence, OpenAI has emerged as a formidable force, leaving many startups scrambling to keep up. With the release of ChatGPT4-o, a powerful language model that outperforms its predecessors, OpenAI has raised the bar, posing significant challenges for companies that rely on AI technology. I want to tinker a bit about implications of OpenAI's dominance, the potential erosion of competitive advantages, and the business models that may thrive in a post-ChatGPT era, while also exploring the boundaries and limitations of these advanced language models.
As large language models (LLMs) continue to advance, the competitive advantages enjoyed by companies that rely on these models may begin to erode. The very nature of LLMs, which are trained on vast amounts of data, means that as the models improve, the gap between industry leaders and smaller players diminishes. Companies that have built their businesses around LLMs may find themselves in a worse position, as the technology they once considered a competitive edge becomes more widely available and accessible. This phenomenon could lead to a commoditization of AI services, making it increasingly difficult for companies to maintain a sustainable competitive advantage. The data will become more and more important as the performance of LLMs can be heavily influenced by the quality and relevance of the training data, as well as the specific fine-tuning techniques employed. Companies that have access to high-quality, domain-specific data and expertise in fine-tuning LLMs for their particular use cases may still be able to maintain a competitive edge.
I explained further on what I thought about this competitive edge in this post:
While the advancements in language models like ChatGPT4-o are undoubtedly impressive, one of the key limitations of language models like ChatGPT4-o is their lack of true understanding or reasoning capabilities. While these models can generate human-like text and provide coherent responses, they do not possess a deep understanding of the concepts they are discussing. Instead, they rely on pattern recognition and statistical associations learned from the training data. This limitation can manifest in several ways, such as:

Smoking apparently does wonders for pregnant women so that doctors not recommend only one day, but 2-3 per day. (not medical advice! )
Factual Inaccuracies: Language models can generate responses that sound plausible but may contain factual errors or inconsistencies, especially when dealing with topics outside their training data or when asked to extrapolate beyond their knowledge base. This highlights the importance of the training data and coverage of the training data even more.
Lack of Common Sense: Despite their impressive language capabilities, language models may struggle with tasks that require common sense reasoning or understanding of real-world contexts and implications.
Bias and Ethical Concerns: Language models can inherit biases present in their training data, leading to potentially harmful or unethical outputs. Addressing these biases and ensuring the responsible use of language models is an ongoing challenge.
Limited Domain Knowledge: While language models can be fine-tuned for specific domains, their performance may still be limited compared to specialized AI models or human experts with deep domain knowledge and experience.
Scalability and Computational Constraints: Training and deploying large language models require a lot of compute and the use case has to be evaluated very carefully if it meets a certain ROI bar that justifies this large amount of compute and memory overall.
Then, what type of business can actually survive in the post ChatGPT-8 world?
Specialized AI Solutions: While generalized AI models like ChatGPT4-o excel at a wide range of tasks, there may still be opportunities for businesses to develop specialized AI solutions tailored to specific industries or use cases. By focusing on niche applications and leveraging domain-specific knowledge, companies can create value that is difficult to replicate by generalized models. For example, a startup specializing in medical imaging analysis could develop AI models specifically trained on vast datasets of medical images, leveraging domain-specific knowledge and techniques that generalized LLMs may struggle with. Similarly, a company focused on predictive maintenance for industrial equipment could develop AI solutions tailored to the unique challenges and data patterns of that domain.
AI-Powered Services: Instead of relying solely on AI technology as a product, businesses could explore service-based models that combine AI capabilities with human expertise. By offering AI-powered services that leverage the strengths of both humans and machines, companies can create unique value propositions that are difficult to replicate by AI alone. For instance, a legal services firm could offer AI-assisted contract review and analysis, where the AI model handles the initial parsing and flagging of relevant clauses, while human legal experts provide final review and interpretation. This hybrid approach could potentially offer faster turnaround times, improved accuracy, and a more comprehensive understanding of legal nuances. This also allows business to interchange different types of LLMs under the hood that they use to provide a good service without getting locked in for a given LLM.
AI Ecosystem Enablers: As the demand for AI solutions continues to grow, businesses could position themselves as enablers within the AI ecosystem. This could involve providing infrastructure, tools, or platforms that support the development, deployment, and management of AI applications, catering to the needs of a wide range of industries and use cases. Examples of AI ecosystem enablers could include cloud-based AI platforms that simplify the deployment and scaling of AI models, development tools that streamline the training and fine-tuning of AI models, or monitoring and governance solutions that ensure the responsible and ethical use of AI systems. While I do not think that we need 60 different companies that will make the model serving very efficient, I think we would need multiple companies that will allow us to integrate “Human in the Loop” approach or distilling knowledge from models to other models in a seamless manner.
AI-Driven Data Monetization: With the increasing importance of data in the AI landscape, businesses could explore models that monetize the collection, curation, and analysis of high-quality data sets. By leveraging AI to enhance data quality and insights, companies can create valuable data products that fuel the development of AI applications across various industries.For instance, a company could specialize in collecting and curating large datasets of customer interactions, product reviews, or social media data, and then use AI techniques to extract valuable insights and patterns. These curated datasets could then be sold or licensed to businesses seeking to train their AI models on high-quality, relevant data. Recently Reddit has done a deal with OpenAI that was reflective of this.
Libraries
ILGPU is a JIT (just-in-time) compiler for high-performance GPU programs written in .Net-based languages. ILGPU is entirely written in C# without any native dependencies. It offers the flexibility and the convenience of C++ AMP on the one hand and the high performance of Cuda programs on the other hand. Functions in the scope of kernels do not have to be annotated (default C# functions) and are allowed to work on value types. All kernels (including all hardware features like shared memory and atomics) can be executed and debugged on the CPU using the integrated multi-threaded CPU accelerator.

Bend is a massively parallel, high-level programming language.
Unlike low-level alternatives like CUDA and Metal, Bend has the feeling and features of expressive languages like Python and Haskell, including fast object allocations, higher-order functions with full closure support, unrestricted recursion, even continuations. Yet, it runs on massively parallel hardware like GPUs, with near-linear speedup based on core count, and zero explicit parallel annotations: no thread spawning, no locks, mutexes, atomics. Bend is powered by the HVM2 runtime.
DataScript is an immutable in-memory database and Datalog query engine in Clojure and ClojureScript.
DataScript is meant to run inside the browser. It is cheap to create, quick to query and ephemeral. You create a database on page load, put some data in it, track changes, do queries and forget about it when the user closes the page.
DataScript databases are immutable and based on persistent data structures. In fact, they’re more like data structures than databases (think Hashmap). Unlike querying a real SQL DB, when you query DataScript, it all comes down to a Hashmap lookup. Or series of lookups. Or array iteration. There’s no particular overhead to it. You put a little data in it, it’s fast. You put in a lot of data, well, at least it has indexes. That should do better than you filtering an array by hand anyway. The thing is really lightweight.
The intention with DataScript is to be a basic building block in client-side applications that needs to track a lot of state during their lifetime. There’s a lot of benefits:
Central, uniform approach to manage all application state. Clients working with state become decoupled and independent: rendering, server sync, undo/redo do not interfere with each other.
Immutability simplifies things even in a single-threaded browser environment. Keep track of app state evolution, rewind to any point in time, always render consistent state, sync in background without locking anybody.
Datalog query engine to answer non-trivial questions about current app state.
Structured format to track data coming in and out of DB. Datalog queries can be run against it too.

Quary is an open-source business intelligence (BI) tool designed specifically for engineers. It allows you to connect to databases, write SQL queries to transform and organize data, create charts and dashboards, and deploy the organized data models back to the database.
With Quary, engineers can:
🔌 Connect to their Database
📖 Write SQL queries to transform, organize, and document tables in a database
📊 Create charts, dashboards and reports (in development)
🧪 Test, collaborate & refactor iteratively through version control
🚀 Deploy the organised, documented model back up to the database
MinBPE is a minimal, clean code for the (byte-level) Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings.
This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers.
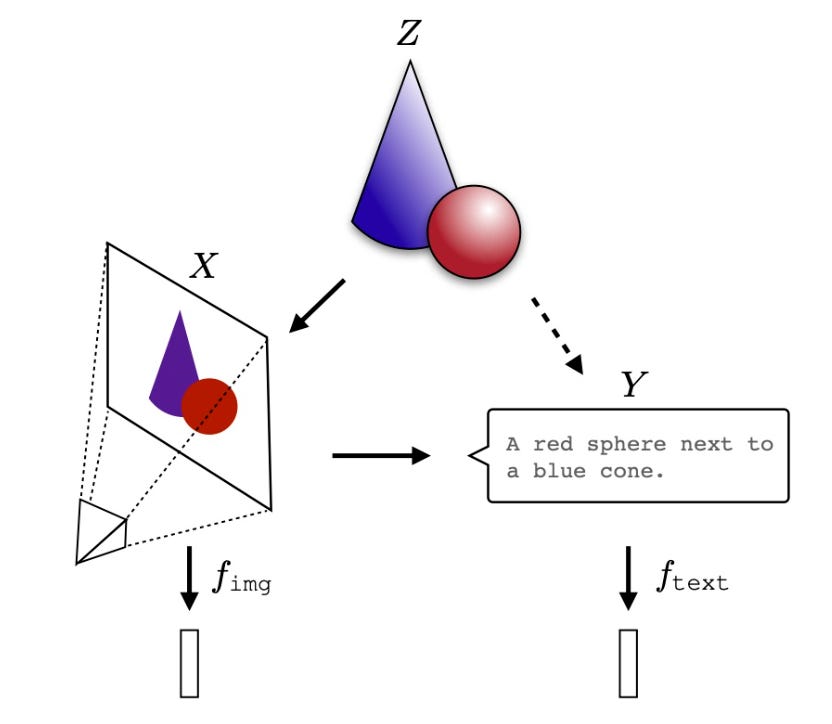
Conventionally, different AI systems represent the world in different ways. A vision system might represent shapes and colors, a language model might focus on syntax and semantics. However, in recent years, the architectures and objectives for modeling images and text, and many other signals, are becoming remarkably alike. Are the internal representations in these systems also converging?
The Platonic Representation Hypothesis(PRH) is that:
Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces.
The intuition behind our hypothesis is that all the data -- images, text, sounds, etc -- are projections of some underlying reality. A concept like
"Apfel"
🍎
can be viewed in many different ways but the meaning, what is represented, is roughly* the same. Representation learning algorithms might recover this shared meaning.
The code is available in GitHub and paper is in the arXiv.

LaVague is an open-source Large Action Model framework to develop AI Web Agents.
Our web agents take an objective, such as "Print installation steps for Hugging Face's Diffusers library" and performs the required actions to achieve this goal by leveraging our two core components:
A World Model that takes an objective and the current state (aka the current web page) and turns that into instructions
An Action Engine which “compiles” these instructions into action code, e.g. Selenium or Playwright & execute them
MegaBlocks is a light-weight library for mixture-of-experts (MoE) training. The core of the system is efficient "dropless-MoE" (dMoE, paper) and standard MoE layers.
MegaBlocks is integrated with Megatron-LM, where we support data, expert and pipeline parallel training of MoEs. Stay tuned for tighter integration with Databricks libraries and tools!
Molecular dynamics is a workhorse of modern computational condensed matter physics. It is frequently used to simulate materials to observe how small scale interactions can give rise to complex large-scale phenomenology. Most molecular dynamics packages (e.g. HOOMD Blue or LAMMPS) are complicated, specialized pieces of code that are many thousands of lines long. They typically involve significant code duplication to allow for running simulations on CPU and GPU. Additionally, large amounts of code is often devoted to taking derivatives of quantities to compute functions of interest (e.g. gradients of energies to compute forces).
However, recent work in machine learning has led to significant software developments that might make it possible to write more concise molecular dynamics simulations that offer a range of benefits. Here JAX, MD target JAX, which allows to write python code that gets compiled to XLA and allows us to run on CPU, GPU, or TPU. Moreover, JAX allows us to take derivatives of python code. Thus, not only is this molecular dynamics simulation automatically hardware accelerated, it is also end-to-end differentiable.
JAX, MD is a research project that is currently under development. Expect sharp edges and possibly some API breaking changes as we continue to support a broader set of simulations. JAX MD is a functional and data driven library. Data is stored in arrays or tuples of arrays and functions transform data from one state to another.
Belebele is a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. This dataset enables the evaluation of mono- and multi-lingual models in high-, medium-, and low-resource languages. Each question has four multiple-choice answers and is linked to a short passage from the FLORES-200 dataset. The human annotation procedure was carefully curated to create questions that discriminate between different levels of generalizable language comprehension and is reinforced by extensive quality checks. While all questions directly relate to the passage, the English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. Belebele opens up new avenues for evaluating and analyzing the multilingual abilities of language models and NLP systems.
The paper also goes in detail for this dataset.
Perplexica is an open-source AI-powered searching tool or an AI-powered search engine that goes deep into the internet to find answers. Inspired by Perplexity AI, it's an open-source option that not just searches the web but understands your questions. It uses advanced machine learning algorithms like similarity searching and embeddings to refine results and provides clear answers with sources cited.
Using SearxNG to stay current and fully open source, Perplexica ensures you always get the most up-to-date information without compromising your privacy.
Things I Enjoy(TIE)
This post is amazing and I highly encourage you to read it if you are interested in the distributed systems and programming in general.
This is a good read for providing a better alternative to Pomodoro Technique: https://www.lesswrong.com/posts/RWu8eZqbwgB9zaerh/third-time-a-better-way-to-work
OpenAI's GPT-4o sets a new benchmark with real-time multimodal capabilities, matching GPT-4 in text tasks and excelling in audio response with low latency.