

Google open-sources Vizier
Pinterest introduces Lightweight Ranking into their ranking stack, Netflix predicts Out of Memory

Articles

Google open-sourced their blackbox optimization library called Vizier. Vizier works by having a server provide services, namely the optimization of blackbox objectives, or functions, from multiple clients. In the main workflow, a client sends a remote procedure call (RPC) and asks for a suggestion (i.e., a proposed input for the client’s blackbox function), from which the service begins to spawn a worker to launch an algorithm (i.e., a Pythia policy) to compute the following suggestions. The suggestions are then evaluated by clients to form their corresponding objective values and measurements, which are sent back to the service. This pipeline is repeated multiple times to form an entire tuning trajectory.
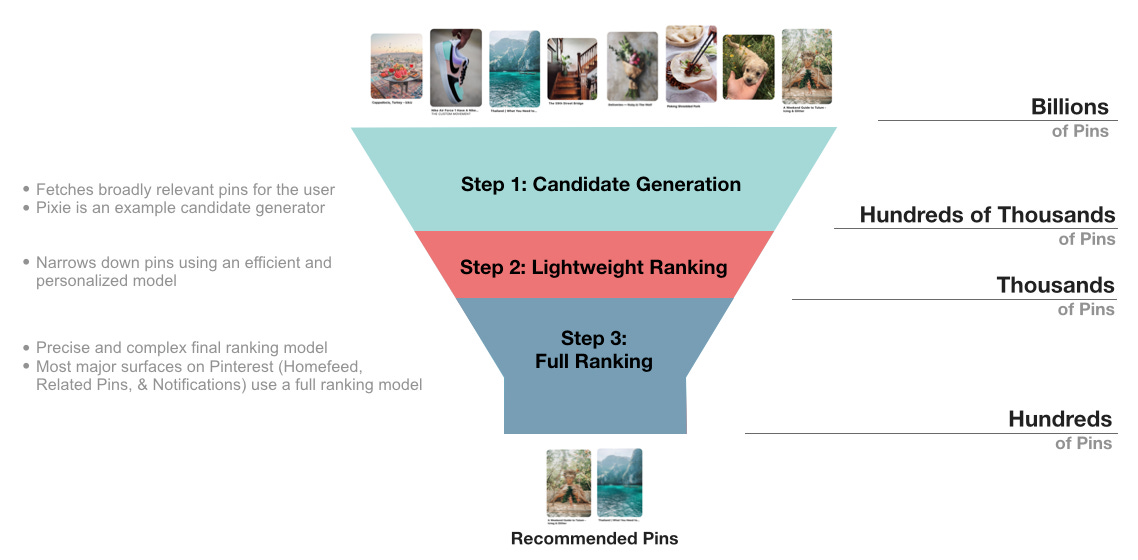
Oldie, but good goodie: Pinterest wrote about how they introduced a lightweight ranking between candidate generation and full ranking for their recommendation systems here.
The main contributions for lightweight ranking are:
Recommend Pins with better relevance and personalization to the user, especially compared to those from the existing “visit count” solution.
Build an efficient machine learning model to support scoring 75 million Pins per second.
Build a scalable and extensible multi-tenant framework that can be easily applied to support different Pixie clients.
Add flexibility to be able to stress certain types of pins based on the client surface’s ever-changing business needs.

Netflix wrote about how they use ML system to predict Out of Memory(OOM) problem in production.
There are a lot of challenges in data engineering Netflix solved and some of them are in the following:
Structuring the data in an ML-consumable format
Dealing with ambiguities and missing data
Incorporating On-site and field knowledge of devices and engineers
The article does not go into detail the ML model and specifics of the deployment, but very good read for data engineering and feature engineering.
Runtime Memory, OOM Kill Data and ground truth labeling
Libraries
Awful AI is a curated list to track current scary usages of AI - hoping to raise awareness to its misuses in society
Artificial intelligence in its current state is unfair, easily susceptible to attacks and notoriously difficult to control. Often, AI systems and predictions amplify existing systematic biases even when the data is balanced. Nevertheless, more and more concerning uses of AI technology are appearing in the wild. This list aims to track all of them.
Omni-Realm Benchmark (OmniBenchmark) is a diverse (21 semantic realm-wise datasets) and concise (realm-wise datasets have no concepts overlapping) benchmark for evaluating pre-trained model generalization across semantic super-concepts/realms, e.g. across mammals to aircraft.
Deploying machine learning data pipelines and algorithms should not be a time-consuming or difficult task. MLeap allows data scientists and engineers to deploy machine learning pipelines from Spark and Scikit-learn to a portable format and execution engine.
TorchScale is a PyTorch library that allows researchers and developers to scale up Transformers efficiently and effectively. It has the implementation of fundamental research to improve modeling generality and capability as well as training stability and efficiency of scaling Transformers.
Google open-sourced their Vizier library, which is for black-box optimization and research, based on Google Vizier, one of the first hyperparameter tuning services designed to work at scale. More information can be found in here.
trlX is a distributed training framework designed from the ground up to focus on fine-tuning large language models with reinforcement learning using either a provided reward function or a reward-labeled dataset.
Training support for 🤗 Hugging Face models is provided by Accelerate-backed trainers, allowing users to fine-tune causal and T5-based language models of up to 20B parameters, such as
facebook/opt-6.7b,EleutherAI/gpt-neox-20b, andgoogle/flan-t5-xxl. For models beyond 20B parameters, trlX provides NVIDIA NeMo-backed trainers that leverage efficient parallelism techniques to scale effectively.Built on top of HuggingFace's Transformers library, JaxSeq enables training very large language models in Jax. Currently it supports GPT2, GPTJ, T5, and OPT models. JaxSeq is designed to be light-weight and easily extensible, with the aim being to demonstrate a workflow for training large language models without with the heft that is typical other existing frameworks.
Nerfstudio provides a simple API that allows for a simplified end-to-end process of creating, training, and visualizing NeRFs. The library supports an interpretable implementation of NeRFs by modularizing each component. With modular NeRF components, we hope to create a user-friendly experience in exploring the technology. Nerfstudio is a contributor-friendly repo with the goal of building a community where users can easily build upon each other’s contributions.
dstack is an open-source tool that allows running reproducible ML workflows independently of the environment. It allows running ML workflows locally or remotely (e.g. in a configured cloud account). Additionally,
dstackfacilitates versioning and reuse of artifacts (such as data and models), across teams.DiffusionDB is the first large-scale text-to-image prompt dataset. It contains 14 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users.
Galactica is a general-purpose scientific language model. It is trained on a large corpus of scientific text and data. It can perform scientific NLP tasks at a high level, as well as tasks such as citation prediction, mathematical reasoning, molecular property prediction and protein annotation. Demos are available in here.