

Google introduces AdaTape, Salesforce introduces LAM(Large Action Model)s
AudioCraft, Amazon's Lightrank and Candle(finally a decent machine learning library in Rust!)

Articles
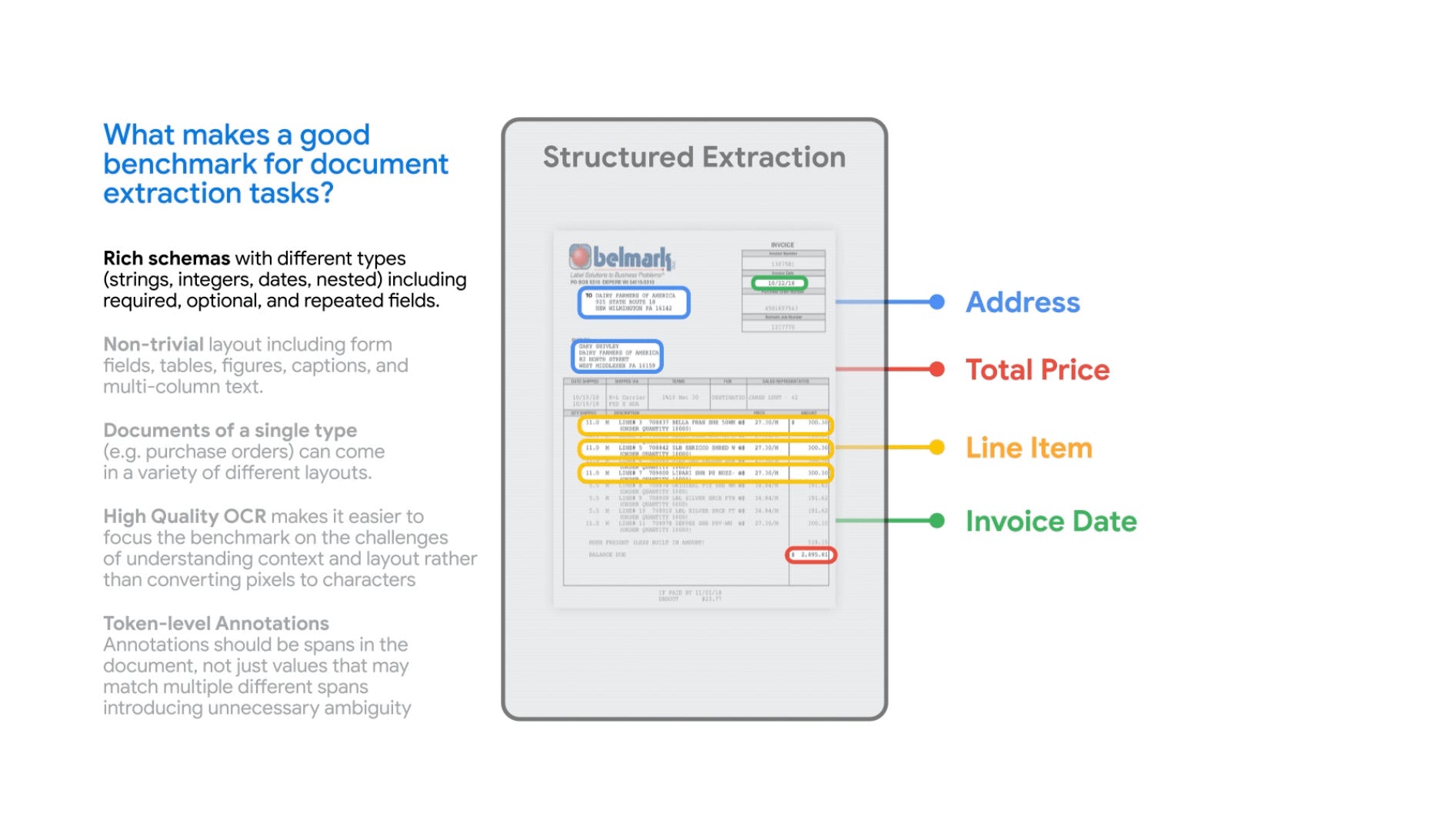
Google wrote a blog post in the document understanding where the blog post discusses the recent advances in document understanding, with a focus on the Visually Rich Document Understanding (VRDU) dataset. VRDU is a new dataset that better reflects the practical challenges of document understanding in real-world applications. Some of the themes that they talked about are the model architectures, document and how visually rich they are and the scale of the models.
Transformer-based models: Transformer-based models have been shown to be very effective for document understanding tasks. These models are able to learn long-range dependencies between words in a document, which is essential for understanding complex documents.
Visually rich documents: Recent work has focused on developing document understanding systems that can handle visually rich documents. These documents often contain tables, images, and charts, which can be challenging for traditional document understanding systems to process.
Larger models: Larger models, such as PaLM 2, have been shown to be able to achieve better accuracy on document understanding tasks than smaller models. This is because larger models are able to learn more complex relationships between text and visual information.
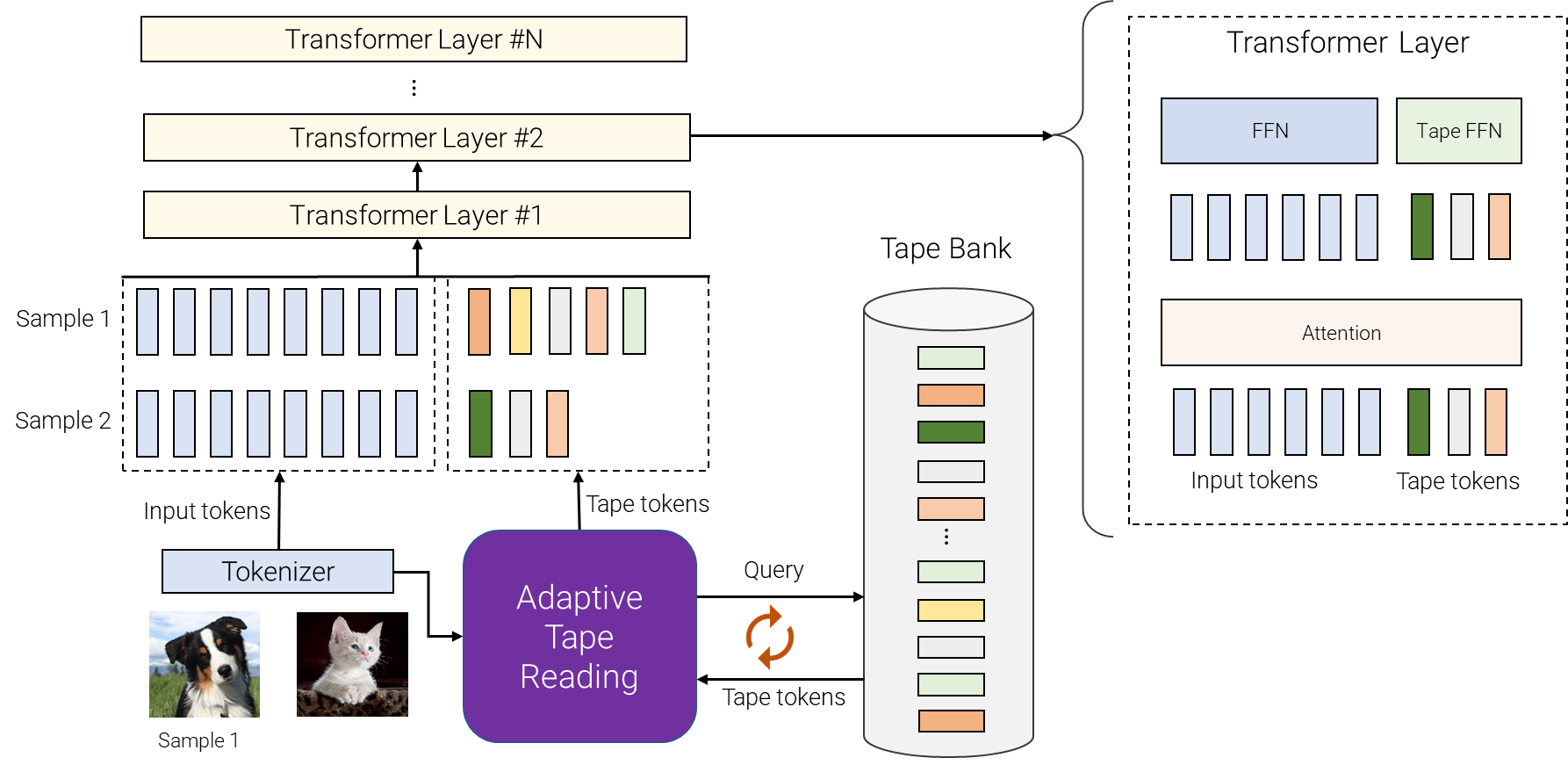
Google introduces a new model architecture called AdaTape that uses adaptive computation to improve the performance of foundation models. AdaTape works by adding a dynamic set of tokens to the input sequence of a foundation model. These tokens are called "tape tokens" and they represent the different steps that the model can take to process the input. The number of tape tokens that are added to the input depends on the complexity of the input. For simple inputs, only a few tape tokens are needed. For more complex inputs, more tape tokens are needed.
The novelty of this model architecture is that the tape tokens are used to control the computation of the foundation model. The foundation model will only process the tokens that are relevant to the input. This allows AdaTape to save computation time on inputs that are simple. On inputs that are complex, AdaTape can still achieve high accuracy by using more computation time.
How AdaTape differs from the state of the art other foundational models are:
Dynamic set of tokens: AdaTape uses a dynamic set of tokens to create elastic input sequences. This means that the number of tokens in the input sequence can vary depending on the complexity of the input. For simple inputs, only a few tokens are needed. For more complex inputs, more tokens are needed.
Adaptive tape reading mechanism: AdaTape uses an adaptive tape reading mechanism to determine a varying number of tape tokens that are added to each input based on input's complexity. This mechanism uses a neural network to predict the number of tape tokens that are needed for each input.
Performance: AdaTape outperforms other adaptive computation models on a variety of tasks, including image classification, natural language inference, and question answering. On the GLUE benchmark, AdaTape achieves a score of 89.8, which is a state-of-the-art result.
Efficiency: AdaTape is more efficient than other adaptive computation models. This is because AdaTape only processes the tokens that are relevant to the input. This can save a significant amount of computation time on simple inputs.
Salesforce introduces a new concept of model type called Large Action Models(LAMs) LAMs are a new type of AI model that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. They are also able to automate entire processes. And because they're naturally fluent in language, they'll intelligently interact with the world—communicating with people, adapting as circumstances change, and even interacting with other LAMs.
The blog post argues LAMs can represent a major shift in the development of AI. Just as LLMs made it possible to automate the generation of text, and, in their multi-modal forms, a wide range of media, LAMs may soon make it possible to automate entire processes.

Amazon wrote a blog post on a new method on compressing token-embedding matrices in language models. Token-embedding matrices are a large part of the size of language models, and they contain a lot of redundancy. The new method, called LightToken, uses low-rank approximation, recursive neural hashing, and a new loss function to compress the matrices while still maintaining accuracy. LightToken achieves a compression ratio of 25, which is five times better than the previous state-of-the-art method. It also outperforms existing matrix-compressing approaches on the GLUE and SQuAD benchmarks.
LightToken composes of the following methods:
Low-rank approximation is a technique for reducing the size of a matrix by representing it as a product of two smaller matrices. This is done by finding a basis for the matrix that captures the most important information.
Recursive neural hashing is a technique for compressing a vector into a binary code. This is done by recursively partitioning the vector into smaller pieces and then hashing each piece into a binary value.
New loss function LightToken uses a new loss function that is designed to preserve the semantic similarity of the compressed embeddings. This is important because it ensures that the compressed embeddings can still be used to represent the meaning of tokens.
Libraries
AudioCraft is a PyTorch library for deep learning research on audio generation. AudioCraft contains inference and training code for two state-of-the-art AI generative models producing high-quality audio: AudioGen and MusicGen.
Aeroresolve is a machine learning library designed from the ground up to be human friendly. It is different from other machine learning libraries in the following ways:
A thrift based feature representation that enables pairwise ranking loss and single context multiple item representation.
A feature transform language gives the user a lot of control over the features
Human friendly debuggable models
Separate lightweight Java inference code
Scala code for training
Simple image content analysis code suitable for ordering or ranking images
This library is meant to be used with sparse, interpretable features such as those that commonly occur in search (search keywords, filters) or pricing (number of rooms, location, price). It is not as interpretable with problems with very dense non-human interpretable features such as raw pixels or audio samples.
Candle is a minimalist ML framework for Rust with a focus on performance (including GPU support) and ease of use.
Examples:
Whisper: speech recognition model.
Llama and Llama-v2: general LLM.
Falcon: general LLM.
Bert: useful for sentence embeddings.
StarCoder: LLM specialized to code generation.
Stable Diffusion: text to image generative model

LlamaGPT is a self-hosted, offline, ChatGPT-like chatbot, powered by Llama 2. 100% private, with no data leaving your device.
Fooocus is an image generating software. It is a rethinking of Stable Diffusion and Midjourney’s designs:
Drawing lessons from Stable Diffusion, the software is offline, open source, and free.
Drawing lessons from Midjourney, the manual tweaking is not needed, and users only need to focus on the prompts and images.
Fooocus has included and automated lots of inner optimizations and quality improvements. Users can forget all those difficult technical parameters, and just enjoy the interaction between human and computer to "explore new mediums of thought and expanding the imaginative powers.