Google improves upon NIMA(Neural Image Assessment) through MUSIQ
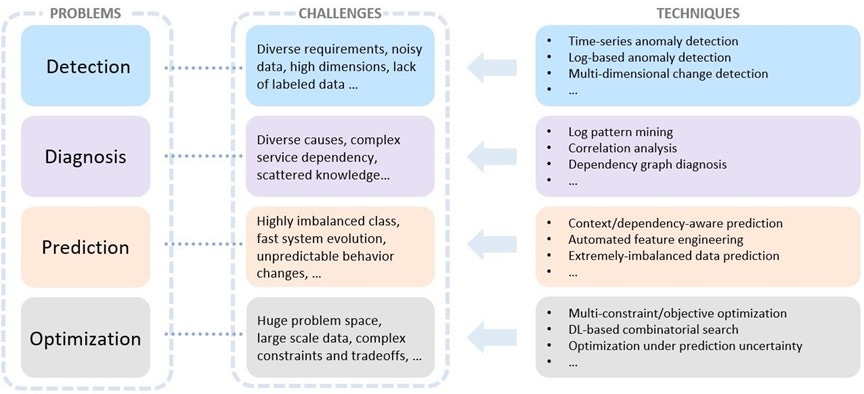
Microsoft introduces AIOps, Tensorflow's future, Uber ranks the notifications through XGBoost and Linear Programming

If you have to read one article this week:

Articles

Google improves upon NIMA(Neural Image Assessment) through MUSIQ, MUSIQ stands for Multi-scale Image Quality Transformer and yes, you have guessed right, the model is a variant of a Transformer model.
The one of the main shortcomings of NIMA was that the input image had to be resized and that created a challenge of the benchmark and algorithm itself in a real life datasets where the input images might have a varying sizes.
MUSIQ accommodates this shortcoming by using multi-scale input images so that the algorithm is scale-invariant. This multi-scale/multi-resolution input are extracted into 3 different embedding representation; scale embedding(SCE), hash-based spatial 2D embedding(HSE) and multi-scale patch embedding(MCE).
I like the approach and how it the approach is scale-invariant, but the way the method was developed felt to me that it is a lot more like HoG(Histogram of Gradients)/SIFT(Scale Invariant Feature Transformations) with regards to how the input images are processed.
Microsoft introduces a new unit AIOps detailing in the following post:
Cloud Intelligence/AIOps (“AIOps” for brevity) aims to innovate AI/ML technologies to help design, build, and operate complex cloud platforms and services at scale—effectively and efficiently.
AIOps has three pillars, each with its own goal:
AI for Systems to make intelligence a built-in capability to achieve high quality, high efficiency, self-control, and self-adaptation with less human intervention.
AI for Customers to leverage AI/ML to create unparalleled user experiences and achieve exceptional user satisfaction using cloud services.
AI for DevOps to infuse AI/ML into the entire software development lifecycle to achieve high productivity.
This is nothing new; ML for systems has been around for a while, but a cloud vendor tries to infuse ML to all of their business units is a right approach given how ML can unlock a variety of optimizations/opportunities in real world, while investing engineering resources, one can argue that ML For systems can become finally a reality from workshop in an eminent conference.
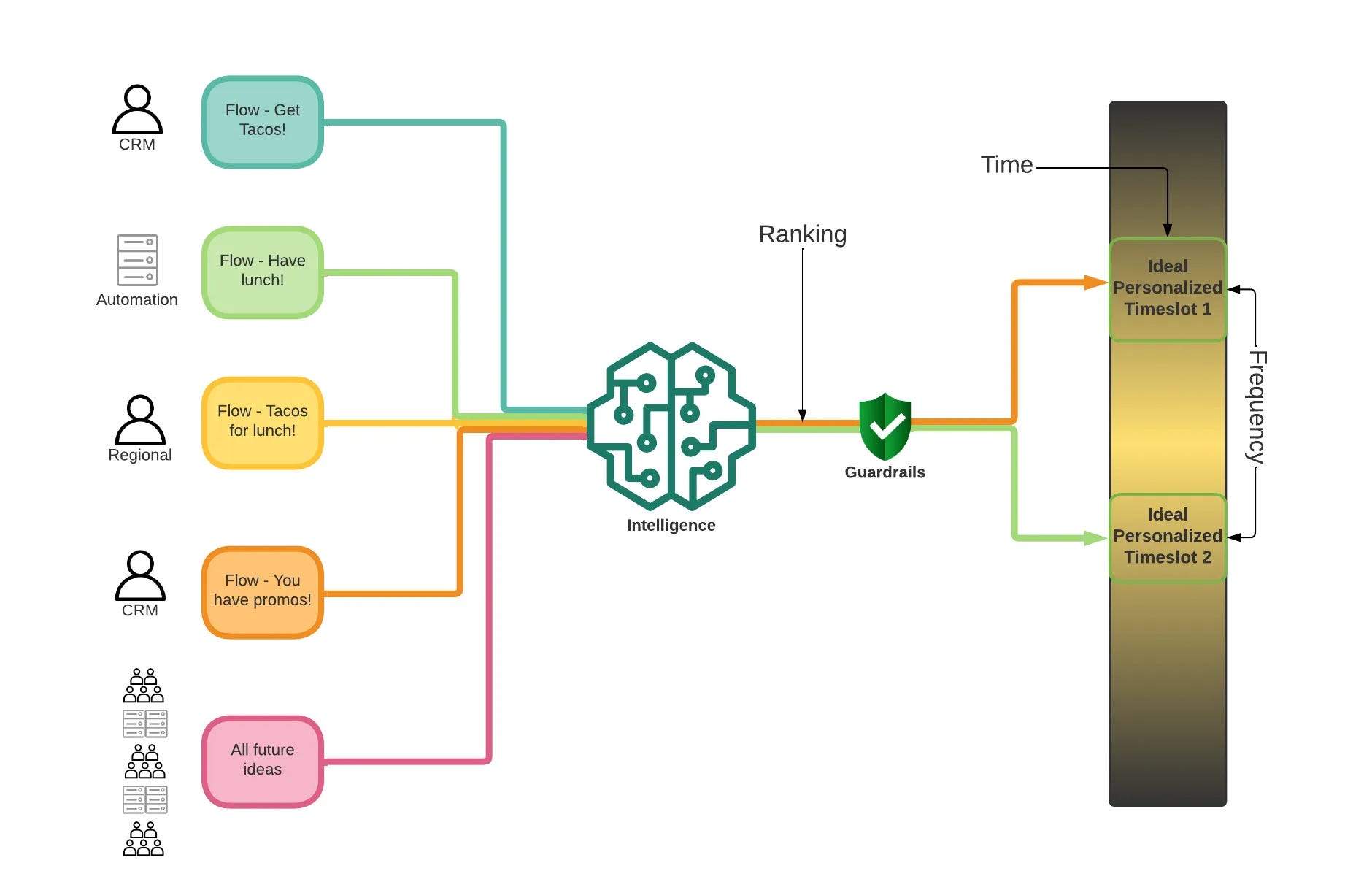
Uber wrote about how they optimized their notifications delivery over a period of time using linear programming(distribute the notifications over time) and XGBoost(ranking for various notifications) in here.
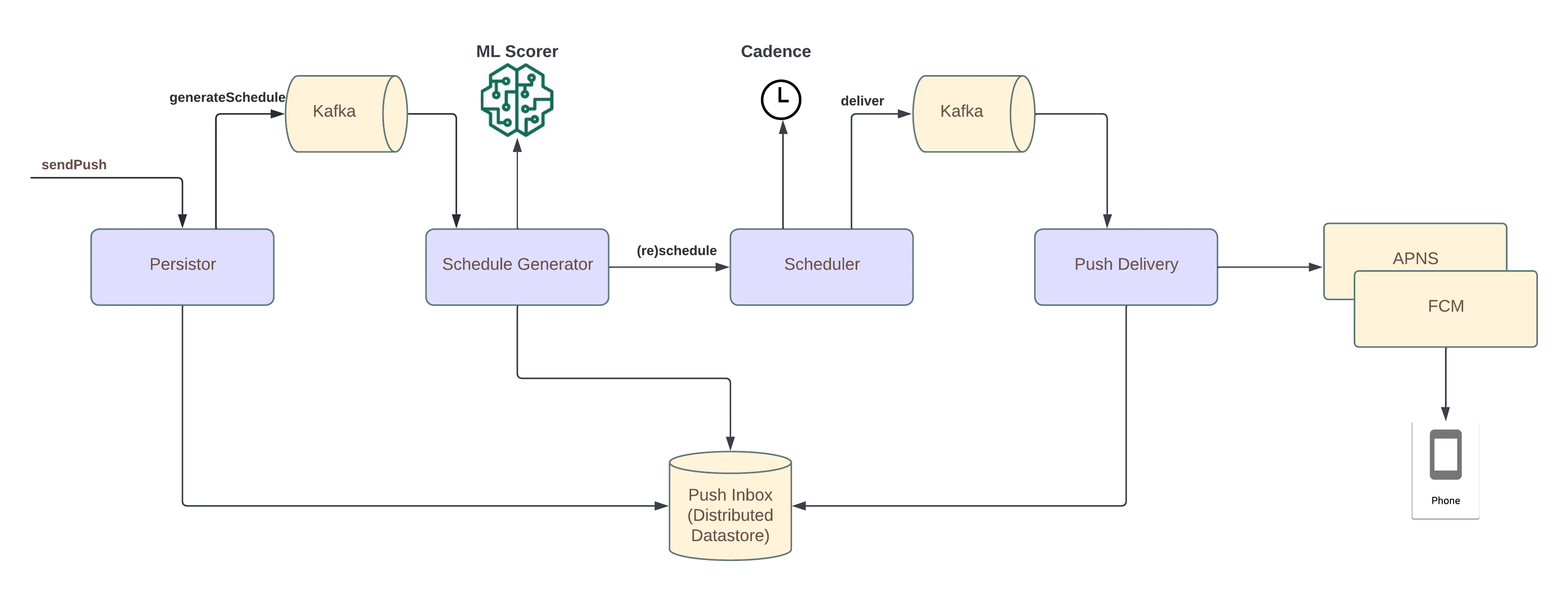
I like how they separated a number of concerns from each other while building the system from ground-up.
They create on a high level two main ML components in the system:
Ranking layer: This component aggregates all of the notifications that are put into the system through CRM(Customer Relationship Management) and ranks them. It does not anything about the delivery of the time of this notification, its main concern is to be able to provide the most relevant notifications and ranks them for a given user.
Timeslot sceduling layer: This component decides what time of the day for a given week that the notifications can be sent to the user. This component uses a number of constraints(2 pushes per day, restaurant availability for promotion) to optimize the time and sometimes day of the week for a given user. This layer does not have to know about the notifications themselves(what type of notification that is) but restaurant or restaurants for promotion should be known, but one make an assignment for promotion with the known restaurant.
Timeslot and ranking layer uses two different solutions to solve a customer problem, timeslot layer uses linear programming to optimize the time of the day or the day of the week for a given user where the ranking layer uses XGBoost to optimize the conversion rate of the notifications for a given user. By doing so, timeslot can actually be responsible and accountable to create the schedules, while ranking layer can optimize the for the business outcome overall.
Google wrote about the future of Tensorflow in the following post. The post goes into detail of four different tenets; Fast and Scalable, Applied ML, Ready to Deploy and Simplicity.
The two tenets(Fast and Scalable, Ready to Deploy) are more production oriented tenets where the other tenets(Applied ML, Simplicity) are more research oriented tenets. They tried to strike a balance in the tenets while optimizing for production use cases, they still put a core focus to the researchers and their use cases.
Fast and Scalable
XLA Compilation
Distributed Computing
Performance Optimization
Applied ML
New tools for CV and NLP
Production Grade Solutions
Developer Resources
Ready To Deploy
Easier Exporting
C++ API for applications
Deploy JAX Models
Simplicity
NumPy API
Easier Debugging
OpenAI opens the public access for Dall-E model in this blog post. There is a good number of companies using Dall-E to create various products such as Mixtiles, Cala.
Libraries
Collecting, labeling, and cleaning data for computer vision is a pain. Jump into the future and create your own data instead! Synthetic data is faster to develop with, effectively infinite, and gives you full control to prevent bias and privacy issues from creeping in. We created
zpyto make synthetic data easy, by simplifying the simulation (sim) creation process and providing an easy way to generate synthetic data at scale. Zpy is available in GitHub.Butterfree is a library to build features for your machine learning pipelines.
The library is centered on the following concetps:
ETL: central framework to create data pipelines. Spark-based Extract, Transform and Load modules ready to use.
Declarative Feature Engineering: care about what you want to compute and not how to code it.
Feature Store Modeling: the library easily provides everything you need to process and load data to your Feature Store.
Continuous Machine Learning (CML) is an open-source CLI tool for implementing continuous integration & delivery (CI/CD) with a focus on MLOps. Use it to automate development workflows — including machine provisioning, model training and evaluation, comparing ML experiments across project history, and monitoring changing datasets.
CML can help train and evaluate models — and then generate a visual report with results and metrics — automatically on every pull request.
Ploomber is the fastest way to build data pipelines. Use your favorite editor (Jupyter, VSCode, PyCharm) to develop interactively and deploy ☁️ without code changes (Kubernetes, Airflow, AWS Batch, and SLURM). Do you have legacy notebooks? Refactor them into modular pipelines with a single command.
DALL·E Flow is an interactive workflow for generating high-definition images from text prompt. First, it leverages DALL·E-Mega, GLID-3 XL, and Stable Diffusion to generate image candidates, and then calls CLIP-as-service to rank the candidates w.r.t. the prompt. The preferred candidate is fed to GLID-3 XL for diffusion, which often enriches the texture and background. Finally, the candidate is upscaled to 1024x1024 via SwinIR.
Parca is a library that does continuous profiling for analysis of CPU and memory usage, down to the line number and throughout time. Saving infrastructure cost, improving performance, and increasing reliability.
ReadySet is a lightweight SQL caching engine that precomputes frequently-accessed query results and automatically keeps these results up-to-date over time as the underlying data in your database changes. ReadySet is wire-compatible with MySQL and Postgres and can be adopted without code changes.
SystemDS is an open source ML system for the end-to-end data science lifecycle from data integration, cleaning, and feature engineering, over efficient, local and distributed ML model training, to deployment and serving. To this end, we aim to provide a stack of declarative languages with R-like syntax for (1) the different tasks of the data-science lifecycle, and (2) users with different expertise. These high-level scripts are compiled into hybrid execution plans of local, in-memory CPU and GPU operations, as well as distributed operations on Apache Spark. In contrast to existing systems - that either provide homogeneous tensors or 2D Datasets - and in order to serve the entire data science lifecycle, the underlying data model are DataTensors, i.e., tensors (multi-dimensional arrays) whose first dimension may have a heterogeneous and nested schema.

