

Google builds UniAR, AirbnB uses ViTs!
Doordash implements Interleaving instead of A/B test!

Articles

Google wrote an UniAR is a unified approach to predictive modeling of both implicit and explicit human responses to diverse visual content. The model aims to bridge the gap between early-stage perceptual behavior (like attention) and later-stage explicit behavior (such as preferences or likes)
Model Architecture
The main model architecture has main 4 components:
Vision Transformer: This serves as the image encoder, processing visual input.
Word Embedding Layer: Used to embed text tokens, allowing the model to process textual information.
Multimodal Transformer: The core of UniAR, this component integrates visual and textual information to make predictions across various tasks.
Task-Specific Prediction Heads: These are used for different output types, such as attention heatmaps, scanpaths, and subjective ratings.
The model is designed to handle a wide range of visual content, including natural images, webpages, and graphic designs. It processes inputs in a unified sequence-to-sequence format, which allows for flexibility across different tasks and data types.
Advantages of this approach over other techniques
Unified Approach: UniAR can predict multiple aspects of human behavior using a single model, including attention heatmaps, viewing order (scanpaths), and subjective ratings or preferences.
Multimodal Processing: The model can handle both visual and textual inputs, making it versatile for various types of content.
Cross-Domain Generalization: Trained on diverse datasets, UniAR demonstrates strong performance across different image domains and behavior modeling tasks.
Minimal Fine-Tuning: The model's architecture allows for adaptation to new tasks with minimal changes, leveraging its inherent generality.
More information is available in paper.

Airbnb implemented an AI-powered photo tour feature to enhance the user experience when browsing property listings. This uses advanced computer vision techniques, specifically a Vision Transformer model, to analyze and organize photos of properties.
Vision Transformers(ViT)
ViT is a type of machine learning model that applies the transformer architecture, originally developed for natural language processing, to image recognition tasks. They have shown impressive performance in various computer vision tasks, often outperforming traditional convolutional neural networks (CNNs). They have the following advantages:
Patch-based approach: The input image is divided into fixed-size patches, which are then linearly embedded.
Positional embeddings: Added to the patch embeddings to retain positional information.
Self-attention mechanism: Allows the model to focus on different parts of the image for different tasks.
Transfer learning: ViTs can be pre-trained on large datasets and then fine-tuned for specific tasks.
They use the pre-trained model and then fine-tune that model into their image datasets by following the steps outlined in the post:
Pre-training: They started from a pre-trained model on ImageNet. They took that model and trained it with a large amount of host-provided data, which has lower accuracy and only covers some of our class labels. This provided a baseline model for transfer learning in the following steps.
Multi-task training: They fine-tuned the model from the previous step using both higher-accuracy training data for the target task (e.g., room-type classification), and an additional type of training data that has been labeled for another related task (e.g., object detection). This provided additional training data and created multiple different models for future steps.
Ensemble learning: They created an ensemble from multiple models in Step 2, which was achieved through training with different auxiliary tasks, and by using different versions of ViTs (e.g., ViT-base vs. ViT-large, and/or those consuming images of size 224 vs 384). This approach allowed us to generate a diverse set of models, from which we selected the best performers to construct the final ensemble model.
Distillation: Although the ensemble model has higher accuracy than any individual model, it requires more computational resources and thus increases the latency and cost of our product. They then trained a distilled model to imitate the behavior of the ensemble model, which has similar accuracy but reduced computational cost by several folds.

They demonstrate an ensemble model with multi-task learning to be superior all of the other approaches.
Airbnb uses ViTs for several purposes in their photo tour feature:
Image classification: Categorizing photos into different room types (bedroom, bathroom, kitchen, etc.) or amenities.
Object detection: Identifying key features or objects within each photo.
Image quality assessment: Evaluating the quality and relevance of photos to ensure the best user experience.
Semantic understanding: Comprehending the overall context and layout of the property from the photos.
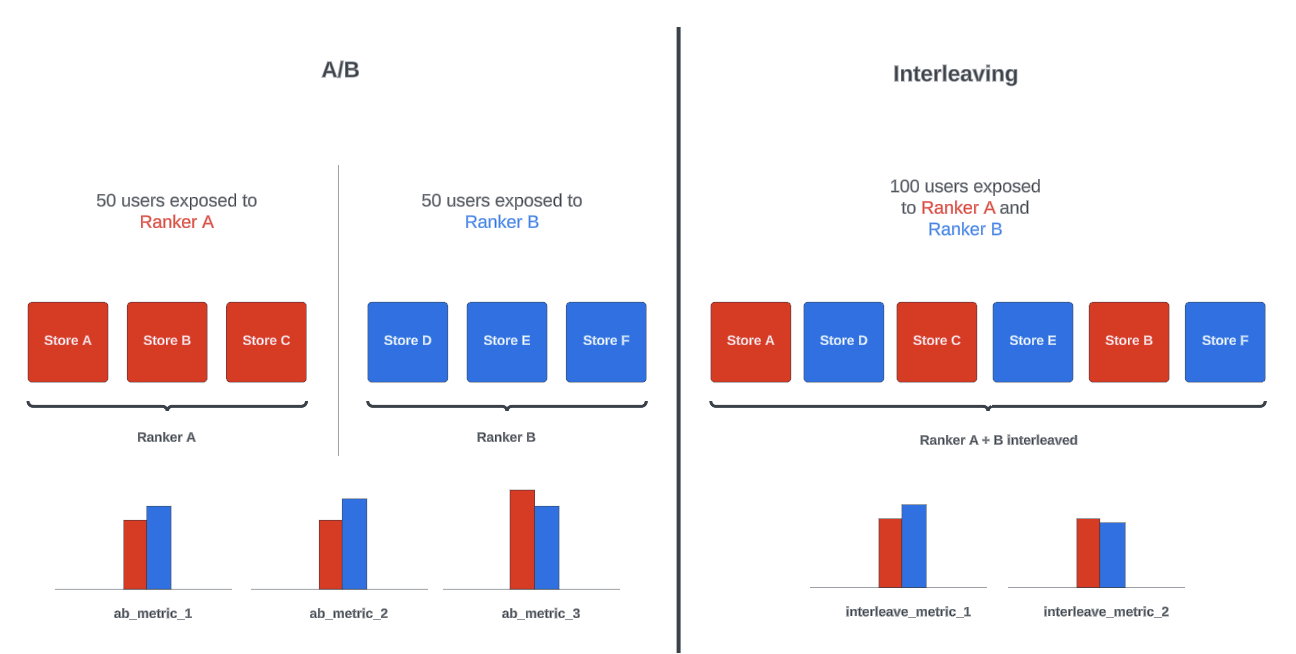
DoorDash has implemented interleaving designs to significantly improve the sensitivity and efficiency of their experimentation process. Traditionally relying on A/B testing, the company found that this method often lacked precision and speed, especially in search and ranking use cases. Interleaving design offers a solution by allowing multiple conditions to be tested simultaneously on the same user, resulting in sensitivity gains of more than 100 times that of traditional methods and some of the advantages are:
Higher sensitivity: DoorDash has achieved sensitivity improvements of 100x to 500x, surpassing reported gains from other companies like Netflix, Airbnb, and Amazon.
Faster iteration: The increased sensitivity allows for quicker and more confident decision-making.
Reduced exposure to suboptimal changes: Users spend less time experiencing underperforming variations.
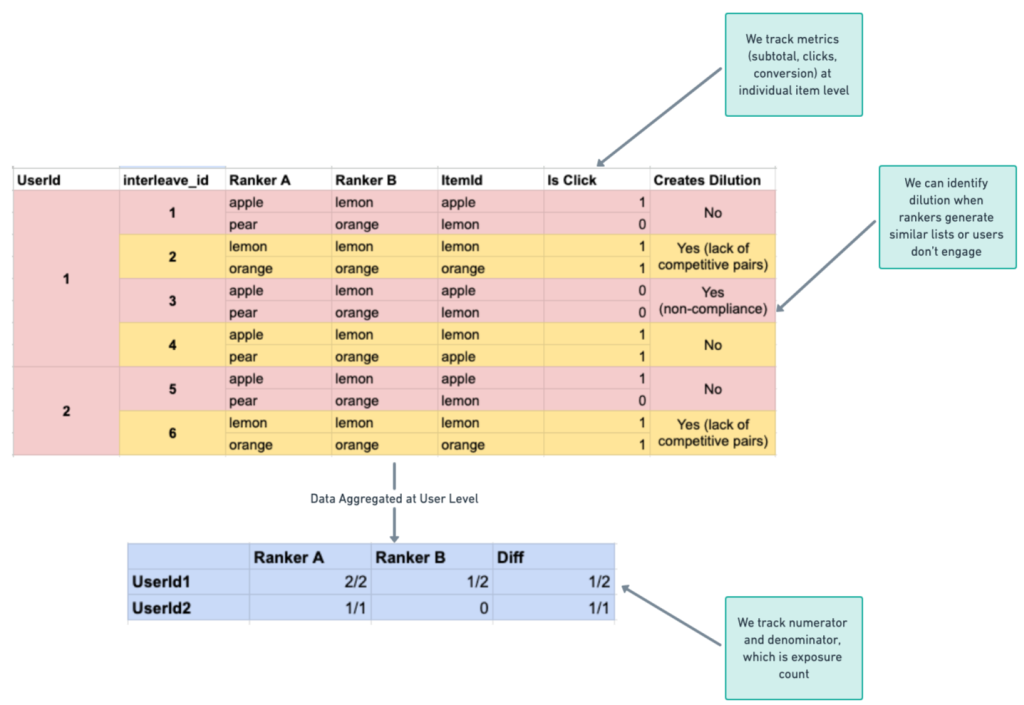
The high sensitivity of interleaving designs is attributed to three main factors:
Controls for within-subject variance: By testing multiple conditions on the same user simultaneously, interleaving designs effectively control for individual differences and environmental factors.
Handles dilution from competitive pairs: The design allows for identification of cases where rankers generate similar lists, enabling the removal of data where recommendations between treatment and control are too similar.
Handles dilution from non-engagement: Interleaving designs can identify users who are not actively engaging with the content, allowing for the removal of non-meaningful impressions.

The resulting framework has three main components:
Experiment Configuration: Unlike traditional A/B tests, interleaving experiments don't know the values to be served at configuration time. Instead, they use experiment objects to control the interleaving flow.
Interleaving Algorithm: DoorDash uses an algorithm that can be likened to team captains drafting players, where each "captain" represents a list to be interleaved.
Event Attribution: The company has developed a direct attribution approach that tracks metrics at the individual item level, allowing for more granular analysis.
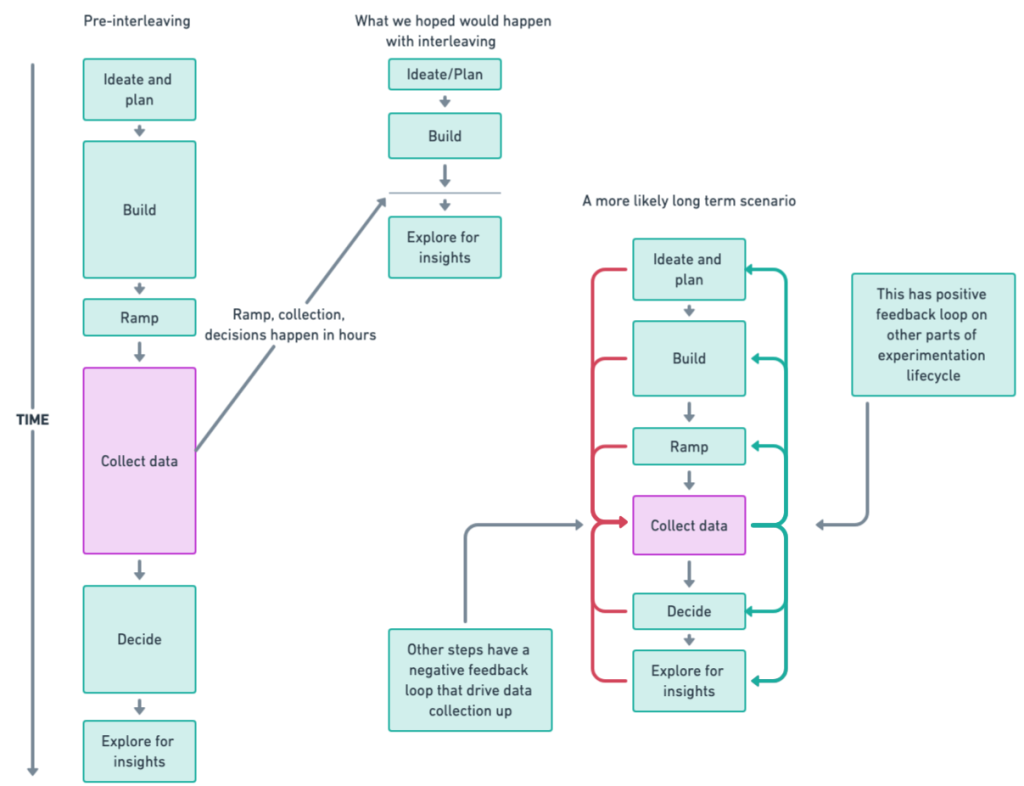
The blog post also discusses the challenges faced in implementing interleaving designs and provides recommendations for handling these challenges. One significant challenge was determining how to handle event attribution, for which DoorDash developed a direct attribution approach that tracks metrics at the individual item level
Results from five online experiments showed that removing dilution helped boost interleaving sensitivity even further, leading to much smaller required sample sizes. On average, vanilla interleaving showed a 67x improvement in sensitivity, while interleaving with dilution removal showed a 384x improvement

Libraries

Aide is the Open Source AI-native code editor. It is a fork of VS Code, and integrates tightly with the leading agentic framework on swebench-lite.
Aide combines the powerful features of VS Code with advanced AI capabilities to provide:
A combined chat + edit flow - Brainstorm a problem in chat by referencing files and jump into edits (which can happen across multiple files).
Proactive agents - AI iterates on linter errors (provided by the Language Server) and pulls in relevant context using go-to-definitions, go-to-references, etc to propose fixes or ask for more context from you.
Inline editing widget - Similar to the macos spotlight widget, press Ctrl/Cmd+K at any point to give instructions to AI.
Intelligent Code Completion - Context-aware code suggestions powered by state-of-the-art AI models.
AST navigation - Quickly navigate files in blocks rather than line-by-line.
DataChain is a modern Pythonic data-frame library designed for artificial intelligence. It is made to organize your unstructured data into datasets and wrangle it at scale on your local machine. Datachain does not abstract or hide the AI models and API calls, but helps to integrate them into the postmodern data stack.
Key Features
📂 Storage as a Source of Truth.
Process unstructured data without redundant copies from S3, GCP, Azure, and local file systems.
Multimodal data support: images, video, text, PDFs, JSONs, CSVs, parquet.
Unite files and metadata together into persistent, versioned, columnar datasets.
🐍 Python-friendly data pipelines.
Operate on Python objects and object fields.
Built-in parallelization and out-of-memory compute without SQL or Spark.
🧠 Data Enrichment and Processing.
Generate metadata using local AI models and LLM APIs.
Filter, join, and group by metadata. Search by vector embeddings.
Pass datasets to Pytorch and Tensorflow, or export them back into storage.
🚀 Efficiency.
Parallelization, out-of-memory workloads and data caching.
Vectorized operations on Python object fields: sum, count, avg, etc.
Optimized vector search.

PiML (or π-ML, /ˈpaɪ·ˈem·ˈel/) is a new Python toolbox for interpretable machine learning model development and validation. Through low-code interface and high-code APIs, PiML supports a growing list of inherently interpretable ML models:
GLM: Linear/Logistic Regression with L1 ∨ L2 Regularization
GAM: Generalized Additive Models using B-splines
Tree: Decision Tree for Classification and Regression
FIGS: Fast Interpretable Greedy-Tree Sums (Tan, et al. 2022)
XGB1: Extreme Gradient Boosted Trees of Depth 1, with optimal binning (Chen and Guestrin, 2016; Navas-Palencia, 2020)
XGB2: Extreme Gradient Boosted Trees of Depth 2, with effect purification (Chen and Guestrin, 2016; Lengerich, et al. 2020)
EBM: Explainable Boosting Machine (Nori, et al. 2019; Lou, et al. 2013)
GAMI-Net: Generalized Additive Model with Structured Interactions (Yang, Zhang and Sudjianto, 2021)
ReLU-DNN: Deep ReLU Networks using Aletheia Unwrapper and Sparsification (Sudjianto, et al. 2020)

OpenCoder is an open and reproducible code LLM family which includes 1.5B and 8B base and chat models, supporting both English and Chinese languages. Starting from scratch, OpenCoder is pretrained on 2.5 trillion tokens composed of 90% raw code and 10% code-related web data, and supervised finetuned on over 4.5M high-quality SFT examples, finally reaching the performance of top-tier code LLMs. We provide not only model weights and inference code, but also the reproducible training data, the complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols. Empowering researchers to build and innovate, OpenCoder is your open foundation for advancing code AI.
Pipet is a swiss-army tool for scraping and extracting data from online assets, made for hackers
Pipet is a command line based web scraper. It supports 3 modes of operation - HTML parsing, JSON parsing, and client-side JavaScript evaluation. It relies heavily on existing tools like curl, and it uses unix pipes for extending its built-in capabilities.
You can use Pipet to track a shipment, get notified when concert tickets are available, stock price changes, and any other kind of information that appears online.
DeepEval is a simple-to-use, open-source LLM evaluation framework, for evaluating and testing large-language model systems. It is similar to Pytest but specialized for unit testing LLM outputs. DeepEval incorporates the latest research to evaluate LLM outputs based on metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., which uses LLMs and various other NLP models that runs locally on your machine for evaluation.
Whether your application is implemented via RAG or fine-tuning, LangChain or LlamaIndex, DeepEval has you covered. With it, you can easily determine the optimal hyperparameters to improve your RAG pipeline, prevent prompt drifting, or even transition from OpenAI to hosting your own Llama2 with confidence.