Google builds Expert Choice Routing on top of MOE
Netflix improves downscaling videos through Deep learning methods, Spotify explains ML Infrastructure for user forecasting

Articles

Google published an Expert Choice Routing advancement in the Mixture of Experts modeling architecture for their large scale model. In this scheme, they set expert capacity k as the average tokens per expert in a batch of input sequences multiplied by a capacity factor, which determines the average number of experts that can be received by each token. To learn the token-to-expert affinity, our method produces a token-to-expert score matrix that is used to make routing decisions. The score matrix indicates the likelihood of a given token in a batch of input sequences being routed to a given expert.

Netflix built a deep learning based encoder and decoder for downscaling videos. This approach has some advantages over other codecs that are not deep learning or machine learning based:
A learned approach for downscaling can improve video quality and be tailored to Netflix content.
It can be integrated as a drop-in solution, i.e., they do not need any other changes on the Netflix encoding side or the client device side. Millions of devices that support Netflix streaming automatically benefit from this solution.
A distinct, NN-based, video processing block can evolve independently, be used beyond video downscaling and be combined with different codecs.

Amazon open-sources TabTransformer as a solution for tabular datasets. TabTransformer uses Transformers to generate robust data representations — embeddings — for categorical variables, or variables that take on a finite set of discrete values, such as months of the year. Continuous variables (such as numerical values) are processed in a parallel stream. In the semi-supervised setting, when labeled data is scarce, DNNs generally outperform decision-tree-based models, because they are better able to take advantage of unlabeled data. TabTransformer demonstrated an average 2.1% AUC lift over the strongest DNN benchmark. They made the library to be available part of Keras library and has a tutorial in here.
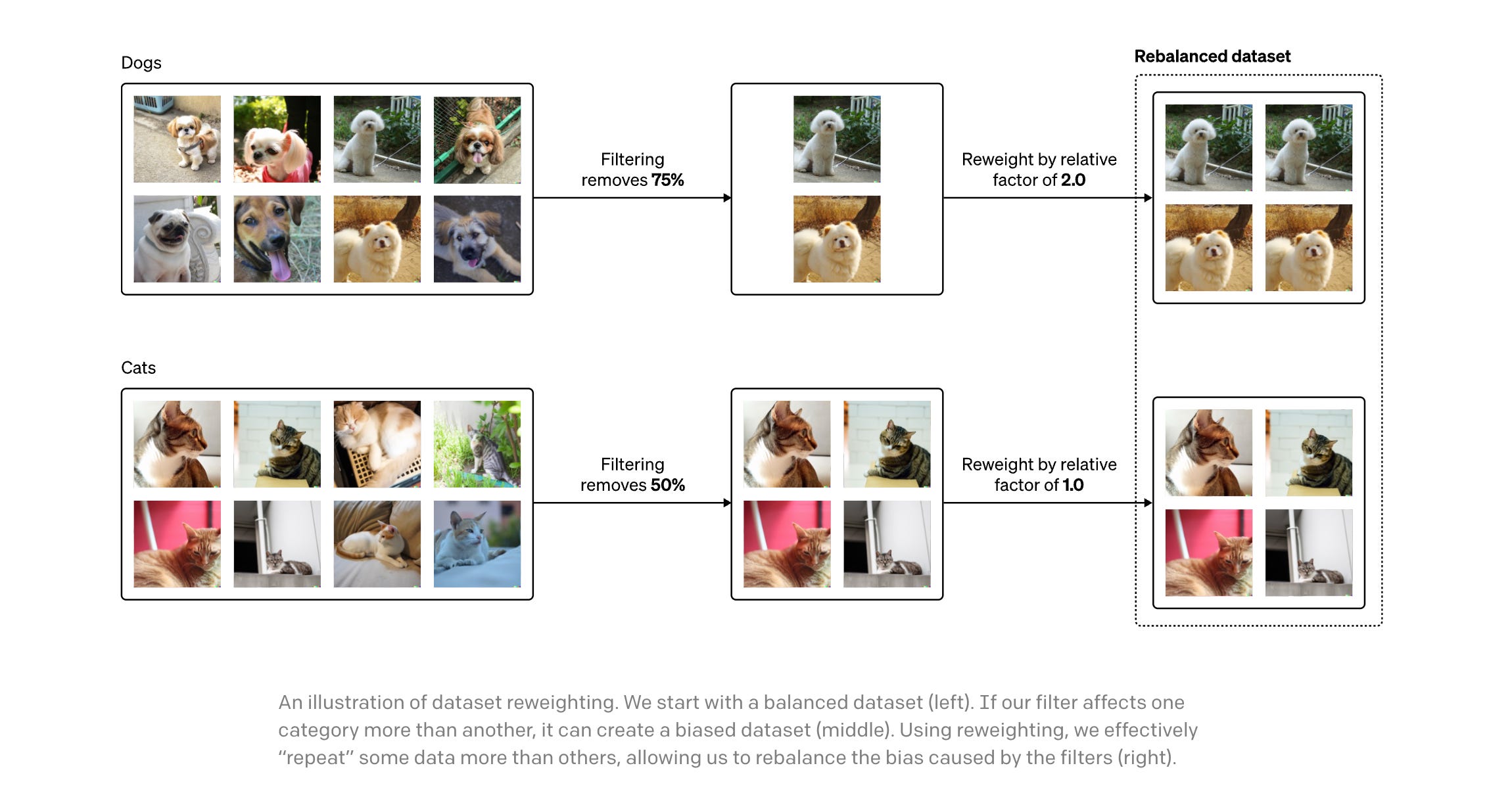
OpenAI wrote about various mitigation strategies on addressing biases in pre-training:
In the first section, they describe how they filtered out violent and sexual images from DALL·E 2’s training dataset. Without this mitigation, the model would learn to produce graphic or explicit images when prompted for them, and might even return such images unintentionally in response to seemingly innocuous prompts.
In the second section, they find that filtering training data can amplify biases, and describe our technique to mitigate this effect. For example, without this mitigation, they noticed that models trained on filtered data sometimes generated more images depicting men and fewer images depicting women compared to models trained on the original dataset.
In the final section, they turn to the issue of memorization, finding that models like DALL·E 2 can sometimes reproduce images they were trained on rather than creating novel images. In practice, they found that this image regurgitation is caused by images that are replicated many times in the dataset, and mitigate the issue by removing images that are visually similar to other images in the dataset.

Spotify explains how they build data infrastructure and ML infrastructure for user forecasting. This infrastructure can allow them to expand into different markets and allow them to do manual customization for different flows.
Balance quality control with fast iteration
There is a delicate balance between strict quality control and fast iteration, as strict quality control creates a lot of overhead for development.
Scaling is magical, but not always the solution
Research can also help narrow down the hyperparameter space and reduce brute-force searches through the part of space that has limited or no impact on the final outcome.
Simplicity
Often decisions have to be made on whether to build additional logic into the core of the system, or to build it as an extension, or discard the change as costs outweigh benefits.
Libraries
FLAIR is a large dataset of images that captures a number of characteristics encountered in federated learning and privacy-preserving ML tasks. This dataset comprises approximately 430,000 images from 51,000 Flickr users, which will better reflect federated learning problems arising in practice, and it is being released to aid research in the field.
DeepCTR is a Easy-to-use, Modular and Extendible package of deep-learning based CTR models along with lots of core components layers which can be used to easily build custom models.You can use any complex model with
model.fit(),andmodel.predict().OpenELM is a replication of Evolution Through Large Models, a recent paper from OpenAI exploring the links between large language models (LLMs) and evolutionary computing, particularly focused on code generation.
LLMs trained on datasets of code, such as OpenAI’s Codex, have shown good results in automated code generation. However, in cases where we are interested in a class of programs which are rarely found in the training distribution, evolutionary algorithms provide a way to generate code by making mutations to known, or "seed" programs. The ELM approach shows that an LLM trained on code can suggest intelligent mutations for genetic programming (GP) algorithms. Genetic algorithms explore the search space with random perturbations, but typically need to be highly customised with domain knowledge to allow them to make desirable changes — LLMs provide a way of encoding this domain knowledge and guiding the genetic algorithm towards intelligent exploration of the search space. More details are available in the release notes.
Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, they cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural network to perceive the image and generate the desired sequence. Their approach is based mainly on the intuition that if a neural network knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, our approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms. A tutorial shows how this framework can be used in here.
TorchScale is a PyTorch library that allows researchers and developers to scale up Transformers efficiently and effectively. It has the implementation of fundamental research to improve modeling generality and capability, as well as training stability and efficiency of scaling Transformers.
Stability - DeepNet: scaling Transformers to 1,000 Layers and beyond
Generality - Foundation Transformers (Magneto)
Efficiency - X-MoE: scalable & finetunable sparse Mixture-of-Experts (MoE)
EasyRec implements state of the art deep learning models used in common recommendation tasks: candidate generation(matching), scoring(ranking), and multi-task learning. It improves the efficiency of generating high performance models by simple configuration and hyper parameter tuning(HPO).