Google announces new Learn to Rank(LTR) Library: Rax through Jax
LocoProp, auton-survival, Neural Architecture Search for multiple visual domains

Articles

Google launched a new optimization functions for deep learning models called LocoProp and announced in the following blog post.
In “LocoProp: Enhancing BackProp via Local Loss Optimization”, we introduce a new framework for training DNN models. Our new framework, LocoProp, conceives neural networks as a modular composition of layers. Generally, each layer in a neural network applies a linear transformation on its inputs, followed by a non-linear activation function. In the new construction, each layer is allotted its own weight regularizer, output target, and loss function. The loss function of each layer is designed to match the activation function of the layer. Using this formulation, training minimizes the local losses for a given mini-batch of examples, iteratively and in parallel across layers. Our method performs multiple local updates per batch of examples using a first-order optimizer (like RMSProp), which avoids computationally expensive operations such as the matrix inversions required for higher-order optimizers. However, we show that the combined local updates look rather like a higher-order update. Empirically, we show that LocoProp outperforms first-order methods on a deep autoencoder benchmark and performs comparably to higher-order optimizers, such as Shampoo and K-FAC, without the high memory and computation requirements.
Google introduced a new ranking library called Rax through Jax.
The library’s objective is to optimize for the correctness of the relative order of a list of examples (e.g., documents) for a given context (e.g., a query). Rax provides support for ranking problems within the JAX ecosystem. It can be used in, but is not limited to, the following applications:
Search: ranking a list of documents with respect to a query.
Recommendation: ranking a list of items given a user as context.
Question Answering: finding the best answer from a list of candidates.
Dialogue System: finding the best response from a list of responses.
It has support for the ranking losses, metrics and transformations:
Ranking losses (
rax.*_loss):rax.softmax_loss,rax.pairwise_logistic_lossRanking metrics (
rax.*_metric):rax.mrr_metric,rax.ndcg_metricTransformations (
rax.*_t12n):rax.approx_t12n,rax.gumbel_t12n
The paper is also presented in KDD 2022.
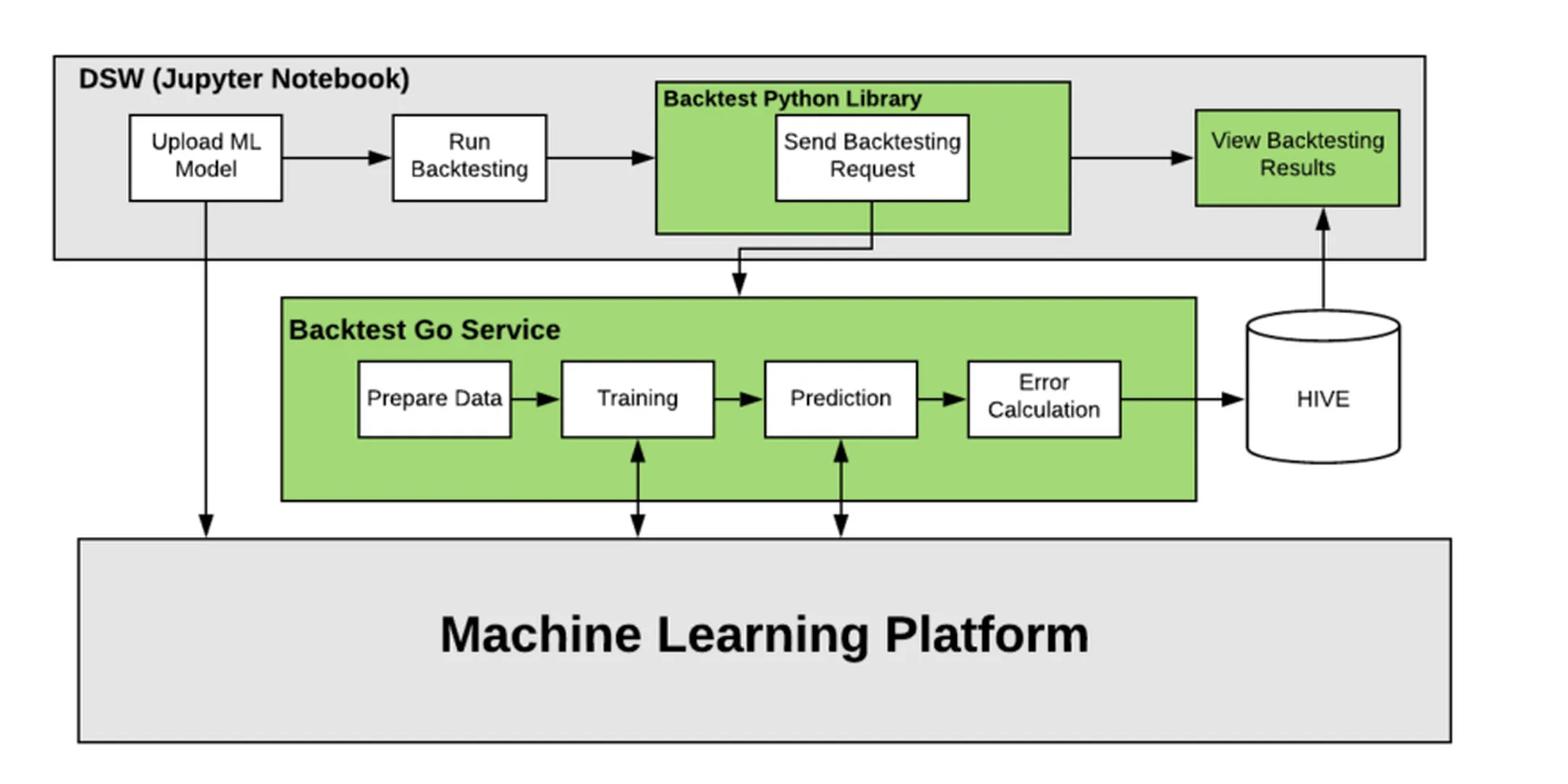
Some readers sent a post to me last week. Uber wrote a blog post a while back ago on how they do backtesting for their statistics and forecast models. They need a service that supports a tight feedback loop—showing where the forecasting models fall short—for data scientists to iterate quickly and effectively. In addition, a tight feedback loop ensures that business decision-makers have a holistic and nuanced view of statistics and models for financial planning.
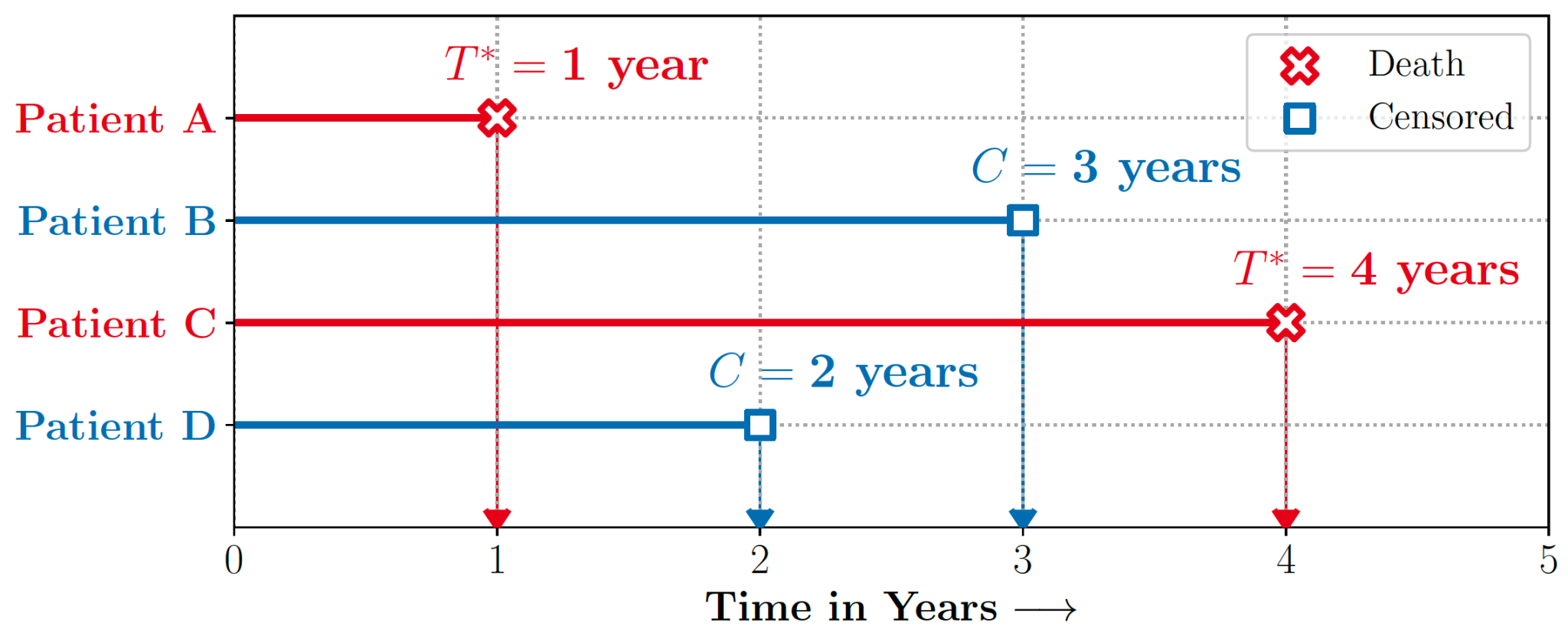
CMU published a new OSS package. Real-world decision-making often requires reasoning about when an event will occur. The overarching goal of such reasoning is to help aid decision-making for optimal triage and subsequent intervention. Discretizing time-to-event outcomes to predict if an event will occur is a common approach in standard machine learning. However, this neglects temporal context, which could result in models that misestimate and lead to poorer generalization.
auton-survival– a comprehensive Python code repository of user-friendly, machine learning tools for working with censored time-to-event data. This package includes an exclusive suite of workflows for a range of tasks from data pre-processing and regression modeling to model evaluation.auton-survivalincludes an API similar to thescikit-learnpackage, making its adoption easy for users with machine learning experience in Python.
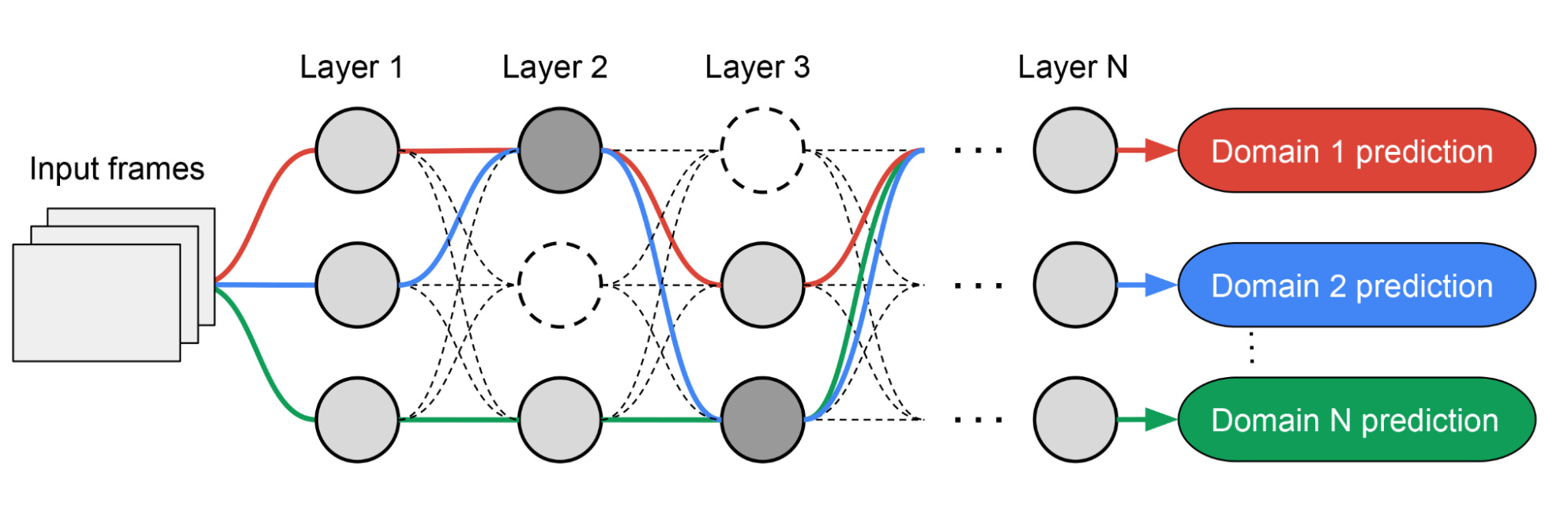
Google wrote how they are using Neural Architecture Search(NAS) for building a multiple visual domain models.
Inspired by TuNAS, MPNAS builds the MDL model architecture in two stages: search and training. In the search stage, to find an optimal path for each domain jointly, MPNAS creates an individual reinforcement learning (RL) controller for each domain, which samples an end-to-end path (from input layer to output layer) from the supernetwork (i.e., the superset of all the possible subnetworks between the candidate nodes defined by the search space). Over multiple iterations, all the RL controllers update the path to optimize the RL rewards across all domains. At the end of the search stage, we obtain a subnetwork for each domain. Finally, all the subnetworks are combined to build a heterogeneous architecture for the MDL model, shown below.
Since the subnetwork for each domain is searched independently, the building block in each layer can be shared by multiple domains (i.e., dark gray nodes), used by a single domain (i.e., light gray nodes), or not used by any subnetwork (i.e., dotted nodes). The path for each domain can also skip any layer during search. Given the subnetwork can freely select which blocks to use along the path in a way that optimizes performance (rather than, e.g., arbitrarily designating which layers are homogenous and which are domain-specific), the output network is both heterogeneous and efficient.
Libraries
Scenic is a codebase with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop classification, segmentation, and detection models for multiple modalities including images, video, audio, and multimodal combinations of them.
More precisely, Scenic is a (i) set of shared light-weight libraries solving tasks commonly encountered tasks when training large-scale (i.e. multi-device, multi-host) vision models; and (ii) several projects containing fully fleshed out problem-specific training and evaluation loops using these libraries.
hyper-nn gives users with the ability to create easily customizable Hypernetworks for almost any generic torch.nn.Module from Pytorch and flax.linen.Module from Flax. Our Hypernetwork objects are also torch.nn.Modules and flax.linen.Modules, allowing for easy integration with existing systems. For PyTorch, they use functorch.
Books
Bayes Rules! An Introduction to Applied Bayesian Modeling talks about basics in the bayesian modeling.